Spark Streaming 快速入门(实操)
教程目录
- 0x00 教程内容
- 0x01 Spark Streaming 编程
-
-
-
-
- 1. 启动Spark Shell
- 2. 创建 StreamingContext 对象
- 3. 创建 DStream 对象
- 4. 对 DStream 进行操作
- 5. 输出数据
-
-
-
- 0x02 校验结果并删除测试数据
-
-
-
-
- 1. 查看统计结果
- 2. 删除测试数据
-
-
-
- 0xFF 总结
0x00 教程内容
- Spark Streaming 编程
- 校验结果并删除测试数据
本案例是在官方文档上做了一定的修改,实现的过程非常简单:开启一个 Spark Streaming 应用,实时接受 TCP Socket 传过来的数据,并进行统计。
0x01 Spark Streaming 编程
Spark Streaming 上构建应用与 Spark 相似,都要先创建 Context 对象,并对抽象数据对象进行操作,Streaming 中处理的数据对象是 DStream。
1. 启动Spark Shell
spark-shell
2. 创建 StreamingContext 对象
// 引入Spark Streaming中的StreamingContext模块
import org.apache.spark._
// 或者直接执行下面这行
import org.apache.spark.streaming._
// 注:下面这一项在Spark 1.3及其之后的版本中不是必需的
// import org.apache.spark.streaming.StreamingContext._
// Spark Shell 会默认创建好 Spark Context 对象,所以下面这句我注释掉了,如果是在编辑器中编写代码,需根据实际情况加上并修改。
// 创建本地的SparkContext对象,包含2个执行线程,APP名字命名为StreamingWordCount
// val conf = new SparkConf().setMaster("local[2]").setAppName("StreamingWordCount")
// 创建的 Spark Context 对象为 sc ,我们需要创建本地的StreamingContext对象,第二个参数为处理的时间片间隔时间,设置为1秒
val ssc = new StreamingContext(sc, Seconds(1))
此处需要注意的是,我们创建 StreamingContext 对象,需要用到 SparkContext 对象(sc)和处理数据所需要设置的时间间隔。
回顾 RDD 的创建过程,我们是直接调用sc 相应的办法就行了。
val textFileRDD = sc.textFile("/home/hadoop-sny/datas/word.txt")
3. 创建 DStream 对象
因为我们是接受 TCP 的数据,所以我们要确认是哪台机器发过来的,而且需要指定端口号。我们使用的是 StreamingContext 对象的 socketTextStream()函数:
// 创建DStream,指明数据源为socket:来自localhost本地主机的9999端口
val lines = ssc.socketTextStream("localhost", 9999)

数据源可以有很多,原理都类似,我们可以调用不同的创建函数去连接 Kafka、 Flume、HDFS/S3、Kinesis 和 Twitter 等数据源。
4. 对 DStream 进行操作
我们需要对接收到的数据进行处理,处理的方式与我们前面教程是一样的。
// 使用flatMap和Split对这1秒内所收到的字符串进行分割
val words = lines.flatMap(_.split(" "))

切割后会得到一系列的单词,然后再进行下面的操作:
// map操作将独立的单词映射成(word,1)元组
val pairs = words.map(word => (word, 1))
// 对统计结果进行相加,得到(单词,词频)元组
val wordCounts = pairs.reduceByKey(_ + _)

5. 输出数据
我们可以将结果输出到一个文件中:
// 输出文件夹的前缀,Spark Streaming会自动使用当前时间戳来生成不同的文件夹名称
val outputFile = "/tmp/test-streaming"
// 将结果输出
wordCounts.saveAsTextFiles(outputFile)

除了输出成文件,其实还有很多种方式,上一篇已经提到过。
实现了流数据的处理逻辑后,我们还需要让 Spark Streaming 运行起来,所以需要执行 Spark Streaming 启动的流程,调用的是StreamingContext 对象的start() 函数和awaitTermination() 函数,分别表示启动信号和等待处理结束的信号。
// 启动Spark Streaming应用
ssc.start()
// 等待计算终止
ssc.awaitTermination()
TODO:经过测试,不执行 ssc.awaitTermination() 也不影响,但是编程的时候是必须的。
执行 ssc.start() 步骤的过程中会报错,显示拒绝连接,无法进行后续实验 :
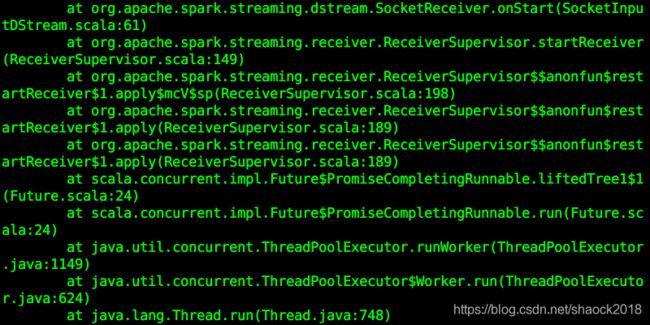
其实,当输入ssc.start()以后,Spark Streaming程序便启动起来,但是没有启动数据来源,所以显示连接不上,此时需要启动 NetCat 来向特定端口发送数据。
打开一个新的终端2,执行:
nc -l -p 9999
说明:
-l 参数表示创建一个监听端口
-p 参数表示当前连接结束后仍然保持监听,必须与 -l 参数同时使用。
发现还没安装:

所以可以通过YUM方式安装一下:
yum install -y nc
安装好后,再执行下面指令:
nc -l -p 9999
启动之后会处于待输入状态(阻塞状态):
![]()
此时返回终端1,发现不再报错,而是处于计算状态:
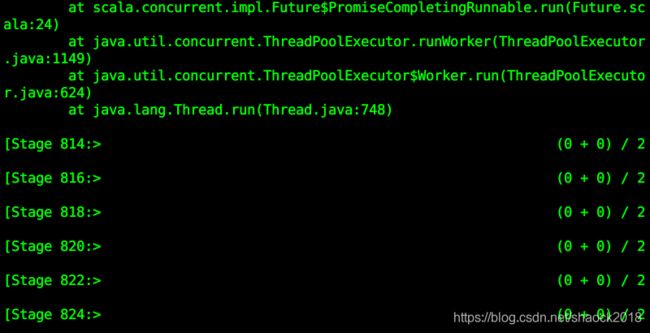
其实,此时已经在/tmp路径生成了很多文件了,并且会不断生成:

在终端2输入下面文本,按回车:
hello shao
hello shao
i love naiyi
teacher shao
hello naiyi

返回终端1查看:
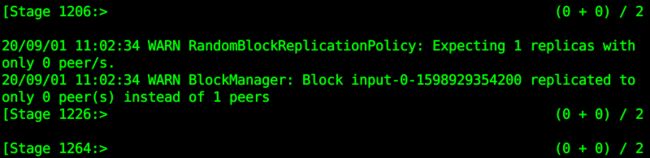
此时就已经在计算了,终端会每隔一秒钟统计一次。如果需要更加准确地观察,可以调大时间间隔,方便自己操作。
0x02 校验结果并删除测试数据
1. 查看统计结果
按Ctrl+Z 停掉终端1的应用后,输入下面的命令看输出的文件:
ls /tmp
发现生成了很多文件:
cat /tmp/test-streaming*/*
发现生成了很多文件:
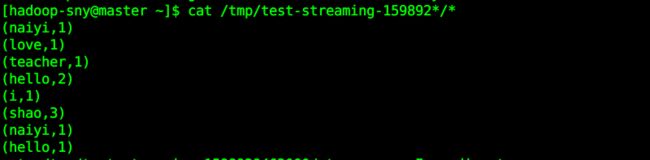
其实生成的文件夹中很多都是没有数据的,使用下面的命令可以过滤出有内容的文件夹,没有数据输出的文件夹的结果为 12 K:
sudo du -sh /tmp/test-str*

所以可以过滤掉12k大小的:
sudo du -sh /tmp/test-str* | grep -v '12K'

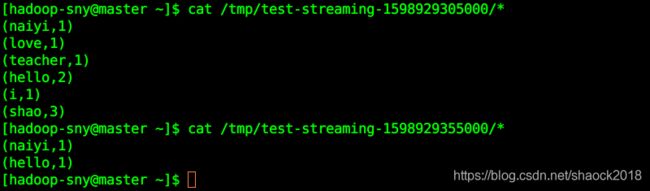
查看有数据的文件夹,则可以查看到 1 秒中获取到的数据流中所统计的词频结果(需改成自己的文件名):
cat /tmp/test-streaming-1598929305000/*
cat /tmp/test-streaming-1598929355000/*
2. 删除测试数据
rm -rf /tmp/test-streaming*
0xFF 总结
- 本章节为 Spark Streaming 的实操教程,理论教程请参考链接:Spark Streaming 快速入门(理论)
- 关注本博客,了解更多大数据知识。点赞、评论、关注,谢谢!
作者简介:邵奈一
全栈工程师、市场洞察者、专栏编辑
| 公众号 | 微信 | 微博 | CSDN | 简书 |
福利:
邵奈一的技术博客导航
邵奈一原创不易,如转载请标明出处,教育是一生的事业。