机器学习:03 Kaggle比赛 患者是否患糖尿病
文章目录
- 过拟合和欠拟合处理
- 模型融合方法(model ensemble)
-
- Bagging
- Stacking
- boost
-
- Adaboost
- Gradient Boosting Tree
- Bagging和Boosting 对比
- Kaggle比赛: 患者是否患糖尿病
-
- 数据集介绍
- 数据预处理
- 载入数据
- 数据可视化分析
-
- 不同类别整体数据分布
- 特征相关性分析
- 模型融合介绍
-
- 投票器模型融合
- Bagging
- RandomForest
- Adaboost
- 模型训练
-
- 特征工程
- 导入模型库
- 决策树
- 随机森林
- Adaboost
- Boosting
-
- GBDT
- XGBoost
- LGB
过拟合和欠拟合处理
-
过拟合
-
找更多的数据来学习
-
增大正则化系数
-
特征选择
-
差异化模型融合
-
-
欠拟合
- 找更多的特征
- 减小正则化系数
模型融合方法(model ensemble)
问题1:模型很多时候效果不好原因?
答案1:过拟合
问题2:如何缓解过拟合
答案2:可以通过模型融合进行解决
介绍三种方式的模型融合方法。
-
bagging
- 随机森林
-
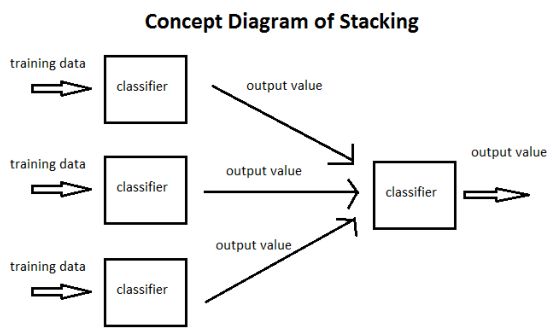
stacking
-
boost
- Adaboost
- GradientBoostTree
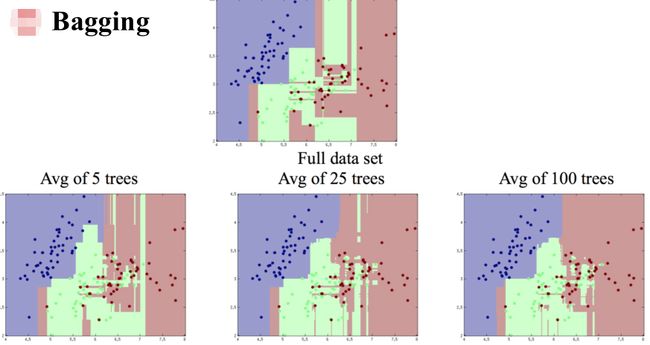
Bagging
-
用一个算法
- 不用全部数据集,每次取一个子集训练一个模型
- 分类:用多个模型的结果vote
- 回归:用多个模型平均
-
用不同算法
- 用模型结果vote 或者平均
Stacking
用多种模型预测结果作为特征训练

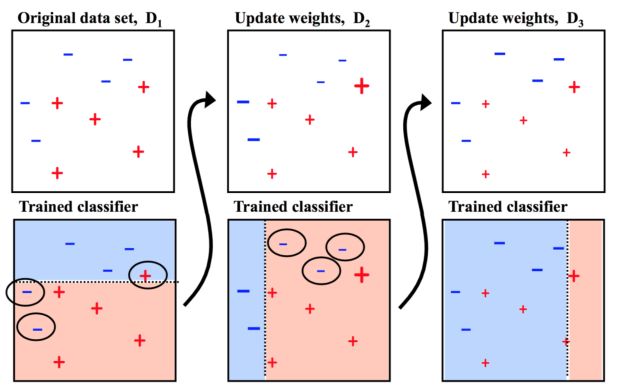
boost
Adaboost
AdaBoost的核心理念,是按顺序拟合一系列弱预测器,后一个弱预测器建立在前一个弱预测器转换后的数据上。每一个弱预测器的预测能力,仅仅略好于随机乱猜。最终的预测结果,是所有预测器的加权平均(或投票结果).
多个弱分类器一起构成一个强大的分类器进行预测。每个分类器都有一定的权重。
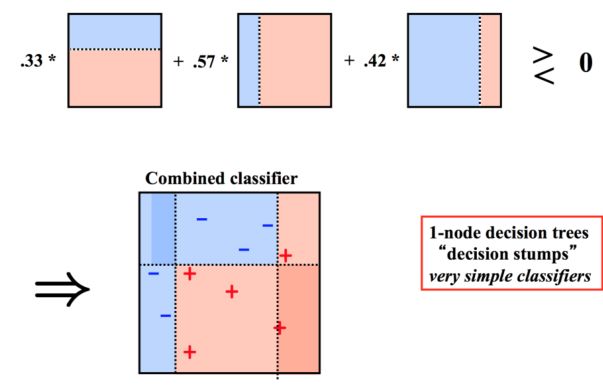
Gradient Boosting Tree
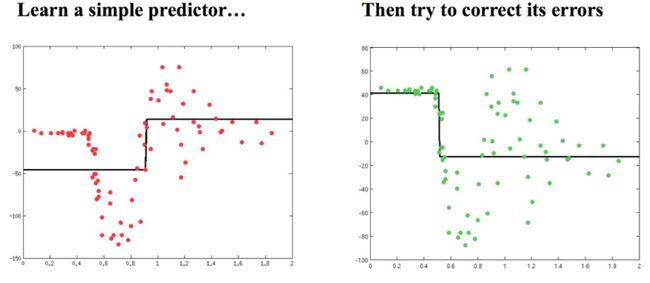
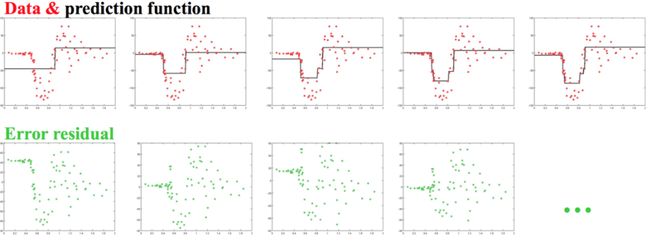
Bagging和Boosting 对比

Kaggle比赛: 患者是否患糖尿病
数据集介绍
-
数据来源:来自国家糖尿病/消化/肾脏疾病研究所,皮马人的医疗记录
-
数据目标:基于诊断测量来诊断性的预测患者是否患有糖尿病。
-
数据集的内容是皮马人的医疗记录,以及过去5年内是否有糖尿病。所有的数据都是数字,问题是(是否有糖尿病是1或0),是二分类问题。数据有8个属性,1个类别:
- Pregnancies:怀孕次数
- Glucose:葡萄糖
- BloodPressure:血压 (mm Hg)
- SkinThickness:皮层厚度 (mm)
- Insulin:胰岛素 2小时血清胰岛素(mu U / ml
- BMI:体重指数 (体重/身高)^2
- DiabetesPedigreeFunction:糖尿病谱系功能
- Age:年龄 (岁)
- Outcome:类标变量 (0或1)
数据预处理
- 明确有多少特征,哪些是连续的,哪些是类别的
- 缺失值弥补,使数据完整
- 连续数值型特征进行标准化,使得均值为0,方差为1
- 类别型的特征进行one-hot编码
- 需要转换成类别型数据的连续型数据进行二值化
- 为防止过拟合,选择是否要将数据进行正则化
- 在对数据进行初探之后发现效果不佳,可以尝试使用多项式方法,寻找非线性的关系
- 根据实际问题分析是否需要对特征进行相应的函数转换
载入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(color_codes = True)
%matplotlib inline
data = "pima-indians-diabetes.data.csv"
#年纪、怀孕、血液检查的次数... 匹马印第安人糖尿病的数据集
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
df = pandas.read_csv(data, names=names)
df.head()
| preg | plas | pres | skin | test | mass | pedi | age | class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 2 | 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 3 | 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 4 | 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
df['class'].value_counts()
0 500
1 268
Name: class, dtype: int64
df.dtypes
preg int64
plas int64
pres int64
skin int64
test int64
mass float64
pedi float64
age int64
class int64
dtype: object
df.info()
RangeIndex: 768 entries, 0 to 767
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 preg 768 non-null int64
1 plas 768 non-null int64
2 pres 768 non-null int64
3 skin 768 non-null int64
4 test 768 non-null int64
5 mass 768 non-null float64
6 pedi 768 non-null float64
7 age 768 non-null int64
8 class 768 non-null int64
dtypes: float64(2), int64(7)
memory usage: 54.1 KB
df.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| preg | 768.0 | 3.845052 | 3.369578 | 0.000 | 1.00000 | 3.0000 | 6.00000 | 17.00 |
| plas | 768.0 | 120.894531 | 31.972618 | 0.000 | 99.00000 | 117.0000 | 140.25000 | 199.00 |
| pres | 768.0 | 69.105469 | 19.355807 | 0.000 | 62.00000 | 72.0000 | 80.00000 | 122.00 |
| skin | 768.0 | 20.536458 | 15.952218 | 0.000 | 0.00000 | 23.0000 | 32.00000 | 99.00 |
| test | 768.0 | 79.799479 | 115.244002 | 0.000 | 0.00000 | 30.5000 | 127.25000 | 846.00 |
| mass | 768.0 | 31.992578 | 7.884160 | 0.000 | 27.30000 | 32.0000 | 36.60000 | 67.10 |
| pedi | 768.0 | 0.471876 | 0.331329 | 0.078 | 0.24375 | 0.3725 | 0.62625 | 2.42 |
| age | 768.0 | 33.240885 | 11.760232 | 21.000 | 24.00000 | 29.0000 | 41.00000 | 81.00 |
| class | 768.0 | 0.348958 | 0.476951 | 0.000 | 0.00000 | 0.0000 | 1.00000 | 1.00 |
数据可视化分析
不同类别整体数据分布
seaborn常用命令
- 【1】set_style()是用来设置主题的,Seaborn有5个预设好的主题:darkgrid、whitegrid、dark、white、ticks,默认为darkgrid
- 【2】set()通过设置参数可以用来设置背景,调色板等,更加常用
- 【3】displot()为hist加强版
- 【4】kdeplot()为密度曲线图
- 【5】boxplot()为箱图
- 【6】joinplot()联合分布图
- 【7】heatmap()热点图
- 【8】pairplot()多变量图,可以支持各种类型的变量分析,是特征分析很好用的工具
data:必不可少的数据;hue:用一个特征来显示图像上的颜色,类似于打标签;vars:只留几个特征两两比较,否则使用data的全部变量;
sns.pairplot(df,hue = 'class')
特征相关性分析
plt.figure(figsize=(12,6))
sns.heatmap(df.corr(),annot = True)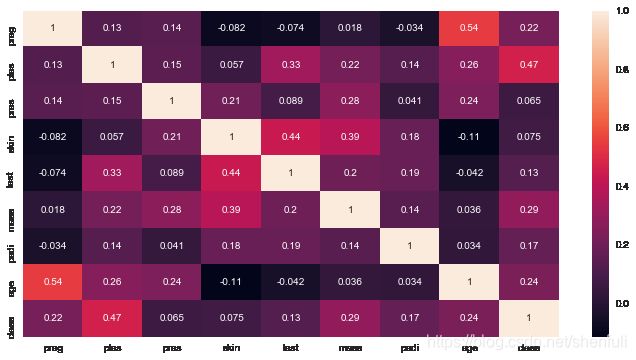
模型融合介绍
投票器模型融合
from sklearn import model_selection
# 线性模型lr(特征必须数值化处理-> 标准化处理,对缺失数值填充,数据敏感)
from sklearn.linear_model import LogisticRegression
# 决策数:多个决策树进行投票给出结果(容易过拟合,通过正则化项、最大树深度、叶子结点个数等等控制)
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifier
import warnings
warnings.filterwarnings('ignore')
df.head(2)
| preg | plas | pres | skin | test | mass | pedi | age | class | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
array = df.values
X = array[:,0:8]
Y = array[:,8]
kfold = model_selection.KFold(n_splits=5, random_state=2018)
# 创建投票器的子模型
estimators = []
model_1 = LogisticRegression()
estimators.append(('logistic', model_1))
model_2 = DecisionTreeClassifier()
estimators.append(('dt', model_2))
model_3 = SVC()
estimators.append(('svm', model_3))
# 构建投票器融合
ensemble = VotingClassifier(estimators)
# 通过k折交叉验证获取平均得分
## https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
## 针对scoring 得分标准 https://blog.csdn.net/qq_32590631/article/details/82831613
## 也可以自定义自己的评分标准 https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
result = model_selection.cross_val_score(ensemble, X, Y, cv=kfold,scoring='accuracy')
print(result)
print(result.mean())
[0.76623377 0.71428571 0.77922078 0.83006536 0.76470588]
0.770902300314065
Bagging
from sklearn.ensemble import BaggingClassifier
dt = DecisionTreeClassifier()
num = 100
kfold = model_selection.KFold(n_splits=5, random_state=2018)
#base_estimator 个体预测器,默认是DecisionTreeClassifier或DecisionTreeRegressor
model = BaggingClassifier(base_estimator=dt, n_estimators=num, random_state=2018)
result = model_selection.cross_val_score(model, X, Y, cv=kfold,scoring='accuracy')
print(result.mean())
0.7669637551990494
RandomForest
from sklearn.ensemble import RandomForestClassifier
num_trees = 100
max_feature_num = 5
kfold = model_selection.KFold(n_splits=5, random_state=2018)
model = RandomForestClassifier(n_estimators=num_trees, max_features=max_feature_num)
result = model_selection.cross_val_score(model, X, Y, cv=kfold,scoring='accuracy')
print(result.mean())
0.7747814277226042
Adaboost
from sklearn.ensemble import AdaBoostClassifier
num_trees = 25
kfold = model_selection.KFold(n_splits=5, random_state=2018)
model = AdaBoostClassifier(n_estimators=num_trees, random_state=2018)
result = model_selection.cross_val_score(model, X, Y, cv=kfold,scoring='accuracy')
print(result.mean())
0.7513623631270689
模型训练
特征工程
X = df.iloc[:,:-1]
y = df.iloc[:,-1]
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,stratify = y,test_size= 0.3,random_state=42)
导入模型库
#决策树
from sklearn.tree import DecisionTreeClassifier
#bagging
from sklearn.ensemble import BaggingClassifier,RandomForestClassifier
# boosting
from sklearn.ensemble import AdaBoostClassifier,GradientBoostingClassifier
决策树
dtree = DecisionTreeClassifier(criterion = 'gini',max_depth = 5)
dtree.fit(X_train,y_train)
print('Training Score : ',dtree.score(X_train,y_train))
print('Testing Score : ',dtree.score(X_test,y_test))
y_pred = dtree.predict(X_test)
y_pred_prob = dtree.predict_proba(X_test)
Training Score : 0.8435754189944135
Testing Score : 0.7705627705627706
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[142 8]
[ 45 36]]
<--------Classification Report-------->
precision recall f1-score support
0 0.76 0.95 0.84 150
1 0.82 0.44 0.58 81
accuracy 0.77 231
macro avg 0.79 0.70 0.71 231
weighted avg 0.78 0.77 0.75 231
随机森林
rf = RandomForestClassifier(n_estimators=10, random_state=42)
rf.fit(X_train,y_train)
print('Training Score : ',rf.score(X_train,y_train))
print('Testing Score : ',rf.score(X_test,y_test))
y_pred = rf.predict(X_test)
y_pred_prob = rf.predict_proba(X_test)
Training Score : 0.9906890130353817
Testing Score : 0.7316017316017316
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[130 20]
[ 42 39]]
<--------Classification Report-------->
precision recall f1-score support
0 0.76 0.87 0.81 150
1 0.66 0.48 0.56 81
accuracy 0.73 231
macro avg 0.71 0.67 0.68 231
weighted avg 0.72 0.73 0.72 231
Adaboost
abc = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=1),n_estimators=100)
abc.fit(X_train,y_train)
print('Training Score : ',abc.score(X_train,y_train))
print('Testing Score : ',abc.score(X_test,y_test))
y_pred = abc.predict(X_test)
y_pred_prob = abc.predict_proba(X_test)
Training Score : 0.8696461824953445
Testing Score : 0.7489177489177489
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[127 23]
[ 35 46]]
<--------Classification Report-------->
precision recall f1-score support
0 0.78 0.85 0.81 150
1 0.67 0.57 0.61 81
accuracy 0.75 231
macro avg 0.73 0.71 0.71 231
weighted avg 0.74 0.75 0.74 231
Boosting
GBDT
gb = GradientBoostingClassifier(learning_rate=0.05,n_estimators=50,max_depth=3)
gb.fit(X_train,y_train)
print('Training Score : ',gb.score(X_train,y_train))
print('Testing Score : ',gb.score(X_test,y_test))
y_pred = gb.predict(X_test)
y_pred_prob = gb.predict_proba(X_test)
Training Score : 0.8603351955307262
Testing Score : 0.7489177489177489
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[131 19]
[ 39 42]]
<--------Classification Report-------->
precision recall f1-score support
0 0.77 0.87 0.82 150
1 0.69 0.52 0.59 81
accuracy 0.75 231
macro avg 0.73 0.70 0.71 231
weighted avg 0.74 0.75 0.74 231
XGBoost
from xgboost import XGBClassifier
xgb = XGBClassifier()
xgb.fit(X_train,y_train)
print('Training Score : ',xgb.score(X_train,y_train))
print('Testing Score : ',xgb.score(X_test,y_test))
y_pred = xgb.predict(X_test)
y_pred_prob = xgb.predict_proba(X_test)
Training Score : 0.9050279329608939
Testing Score : 0.7575757575757576
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[130 20]
[ 36 45]]
<--------Classification Report-------->
precision recall f1-score support
0 0.78 0.87 0.82 150
1 0.69 0.56 0.62 81
accuracy 0.76 231
macro avg 0.74 0.71 0.72 231
weighted avg 0.75 0.76 0.75 231
LGB
#!pip install lightgbm
from lightgbm import LGBMClassifier
lgbm = LGBMClassifier(max_depth=3,
learning_rate=0.1,
n_estimators=50,)
lgbm.fit(X_train,y_train)
print('Training Score : ',lgbm.score(X_train,y_train))
print('Testing Score : ',lgbm.score(X_test,y_test))
y_pred = lgbm.predict(X_test)
y_pred_prob = lgbm.predict_proba(X_test)
Training Score : 0.8379888268156425
Testing Score : 0.7575757575757576
from sklearn.metrics import confusion_matrix,classification_report
print('<--------Confusion Matrix-------->\n',confusion_matrix(y_test,y_pred))
print('<--------Classification Report-------->\n',classification_report(y_test,y_pred))
<--------Confusion Matrix-------->
[[130 20]
[ 36 45]]
<--------Classification Report-------->
precision recall f1-score support
0 0.78 0.87 0.82 150
1 0.69 0.56 0.62 81
accuracy 0.76 231
macro avg 0.74 0.71 0.72 231
weighted avg 0.75 0.76 0.75 231