吴恩达【深度学习工程师】学习笔记(八)
吴恩达【深度学习工程师】专项课程包含以下五门课程:
1、神经网络和深度学习;
2、改善深层神经网络:超参数调试、正则化以及优化;
3、结构化机器学习项目;
4、卷积神经网络;
5、序列模型。
今天介绍《改善深层神经网络:超参数调试、正则化以及优化》系列第三讲:超参数调试、Batch正则化和程序框架。
主要内容:1、超参数;
2、正则化网络;
3、Softmax回归;
4、程序框架Tensorflow。
1、超参数
超参数(Hyperparameters)包括:
-
α :学习因子
-
β :动量梯度下降因子
-
β1,β2,ε :Adam算法参数
-
#layers:神经网络层数
-
#hidden units:各隐藏层神经元个数
-
learning rate decay:学习因子下降参数
-
mini-batch size:批量训练样本包含的样本个数
一般来讲,超参数的重要性顺序如下:最重要的超参数是学习因子 α ;其次是动量梯度下降因子 β 、各隐藏层神经元个数#hidden units和批量训练样本包含的样本个数mini-batch size;然后是神经网络层数#layers和学习因子下降参数learning rate decay;最后是Adam算法的三个参数 β1,β2,ε ,可设置为0.9,0.999和 10−8 。
选择超参数的方法是使用随机选择。例如随机选择25个点作为待调试的超参数,在经过随机采样之后,我们可能得到某些区域模型的表现比较好。为了得到更好的参数,我们继续对选定的区域进行由粗到细的采样。如下图:
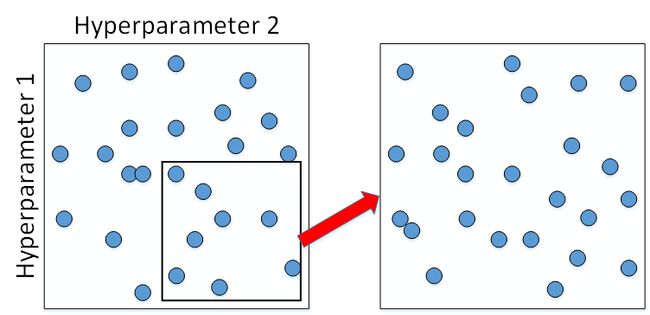
对于某些超参数可以进行尺度均匀采样的。例如对于超参数#layers和#hidden units,都是正整数,是可以进行均匀随机采样的,即超参数每次变化的尺度都是一致的(如每次变化为1,犹如一个刻度尺一样,刻度是均匀的)。
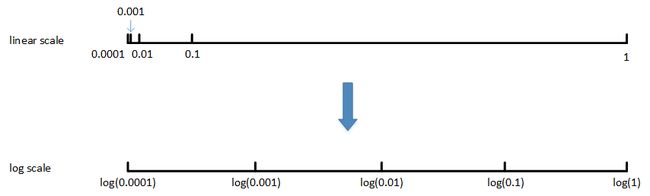
对于另外一些超参数可能需要非均匀随机采样。例如超参数 α ,待调范围是[0.0001, 1]。如果使用均匀随机采样,那么有90%的采样点分布在[0.1, 1]之间,只有10%分布在[0.0001, 0.1]之间。这在实际应用中是不太好的,因为最佳的 α 值可能主要分布在[0.0001, 0.1]之间,而[0.1, 1]范围内 α 值效果并不好。因此我们更关注的是区间[0.0001, 0.1],应该在这个区间内细分更多刻度。
通常的做法是将linear scale转换为log scale,将均匀尺度转化为非均匀尺度,然后再在log scale下进行均匀采样。这样,[0.0001, 0.001],[0.001, 0.01],[0.01, 0.1],[0.1, 1]各个区间内随机采样的超参数个数基本一致,也就扩大了之前[0.0001, 0.1]区间内采样值个数。
除了 α 之外,动量梯度因子 β 也是一样,在超参数调试的时候也需要进行非均匀采样。一般 β 的取值范围在[0.9, 0.999]之间,那么 1−β 的取值范围就在[0.001, 0.1]之间。那么直接对 1−β 在[0.001, 0.1]区间内进行log变换即可。
这里解释下为什么 β 也需要向 α 那样做非均匀采样。假设 β 从0.9000变化为0.9005,那么 11−β 基本没有变化。但假设 β 从0.9990变化为0.9995,那么 11−β 前后差别1000。 β 越接近1,指数加权平均的个数越多,变化越大。所以对 β 接近1的区间,应该采集得更密集一些。
2、正则化网络
在训练神经网络时,标准化输入可以提高训练的速度。方法是对训练数据集进行归一化的操作,即将原始数据减去其均值
μ 后,再除以其方差 σ2 。对于神经网络,又该如何对各隐藏层的输入进行标准化处理呢?
在神经网络中,第 l 层隐藏层的输入就是第 l−1 层隐藏层的输出 A[l−1] 。对 A[l−1] 进行标准化处理,从原理上来说可以提高 W[l] 和 b[l] 的训练速度。这种对各隐藏层的标准化处理就是Batch Normalization。值得注意的是,实际应用中,一般是对 Z[l−1] 进行标准化处理而不是 A[l−1] 。
Batch Normalization(简称BN)对第 l 层隐藏层的输入 Z[l−1] 做如下标准化处理,忽略上标 [l−1] :
其中,m是单个mini-batch包含样本个数, ε 是为了防止分母为零,可取值 10−8 。这样就使得该隐藏层的所有输入 z(i) 均值为0,方差为1。
大部分情况下并不希望所有的 z(i) 均值都为0,方差都为1。通常需要对 z(i) 进行进一步处理:
其中, γ 、 β 是可学习参数,跟W、b一样通过梯度下降等算法求得。 γ 和 β 的作用是让 z~(i) 的均值和方差为任意值。
这样,通过BN,对隐藏层的各个 z[l](i) 进行标准化处理,得到 z~[l](i) ,替代 z[l](i) 。
ps:输入的标准化处理和隐藏层的标准化处理是有不同的。输入的标准化处理使所有输入的均值为0,方差为1。而隐藏层的标准化处理是使各隐藏层输入的均值和方差为任意值。
对于L层神经网络,经过BN的作用,整体流程如下:

事实上,BN经常使用在mini-batch上。
在测试的时候,一个样本求其均值和方差是没有意义的,一般使用指数加权平均的方法来预测测试过程单个样本的
μ 和 σ2 。
指数加权平均的做法很简单,对于第 l 层隐藏层,考虑所有mini-batch在该隐藏层下的 μ[l] 和 σ2[l] ,然后用指数加权平均的方式来预测得到当前单个样本的 μ[l] 和 σ2[l] 。这样就实现了对测试过程单个样本的均值和方差估计。最后,再利用训练过程得到的 γ 和 β 值计算出各层的 z~(i) 值。
3、 Softmax回归
对于多分类问题,用C表示种类个数,神经网络中输出层就有C个神经元,即 n[L]=C 。其中,每个神经元的输出依次对应属于该类的概率,即 P(y=c|x) 。为了处理多分类问题,我们一般使用Softmax回归模型。Softmax回归模型输出层的激活函数如下所示:
输出层每个神经元的输出 a[L]i 对应属于该类的概率,满足:
所有的 a[L]i ,即 y^ ,维度为(C, 1)。
softmax 分类的损失函数。例如:C=4,某个样本的输出为:
从 y^ 值来看, P(y=4|x)=0.4 ,概率最大,而真实样本属于第2类,因此该预测结果不好。我们定义softmax 分类的损失函数为:
然而,由于只有当 j=2 时, y2=1 ,其它情况下, yj=0 。所以,上式中的 L(y^,y) 可以简化为:
要让 L(y^,y) 更小,就应该让 y^2 越大越好。
所有m个样本的代价函数为:
其预测输出向量 A[L] 即 Y^ 的维度为(4, m)。
softmax 分类的反向传播过程仍然使用梯度下降算法,其推导过程与二元分类有一点点不一样。因为只有输出层的激活函数不一样,我们先推导 dZ[L] :
对于所有m个训练样本:
4、程序框架Tensorflow
TensorFlow是谷歌开源的机器学习框架,其的最大优点就是采用数据流图来进行数值运算。图中的节点表示数学操作,图中的边则表示在节点间相互联系的张量。
它灵活的架构让你可以在多种平台上展开计算不用关注平台细节。