CentOS 7.x 环境下, 最详细的 apache hadoop3.2.1 集群的安装 和配置 jobhistory
文章目录
-
-
- 1.准备
- 2. 下载hadoop 包,并上传到linux (上传到第一个节点)
- 3. 进入上传目录并解压(在第一个节点上执行)
- 4.配置环境变量 (在第一个节点上执行)
- 5. 修改core-site.xml 文件()
- 6. 修改hdfs-site.xml 文件添加如下内容
- 7. 修改hadoop-env.sh 文件
- 8. 修改mapred-site.xml 文件
- 9. 修改yarn-site.xml文件
- 10. 添加工作节点修改 workers文件
- 11. 创建文件目录
- 12. 分发hadoop到其它节点
- 13. 初始化hadoop
- 14. 尝试启动,发现报错
- 15. 解决
- 16. 重新启动 发现启动成功
- 17. 测试mapreduce 任务
- 18. 一点建议
- 19. 配置jobHistory
- 20. 最后
-
1.准备
1. 准备好三台 虚拟机/服务器(小编用的是centos 7.7的镜像 ).
2. 配置好网络
3. 关闭selinux 和 防火墙
4. 更改主机名 hostname (小编用的是 hadoop01,hadoop02,hadoop03)
5. 同步三台 虚拟机/服务器时间
6. 配置好ssh 免密登录
7. 安装好jdk1.8的环境
如果上述操作不会可参考博客:
1. Linux CentOS7 创建新的虚拟机
2. Linux CentOS7 网络配置
3. Linux 关闭防火墙 , 配置ssh免密登录
4. Liunx JDK环境配置和安装
2. 下载hadoop 包,并上传到linux (上传到第一个节点)
小编上传的jar到Linux的地址为 /export/soft
安装在 /export/install
配置软链接指定路径为 /export/servers
点击下载apache hadoop3.2.1.tar.gz
3. 进入上传目录并解压(在第一个节点上执行)
# 进入上传目录
cd /export/soft
# 解压
tar -zxvf hadoop-3.2.1.tar.gz -C /export/install
# 进入/export/servers 目录
cd /export/servers
# 建立软链接并重命名
ln -s ../install/hadoop-3.2.1 hadoop
4.配置环境变量 (在第一个节点上执行)
# 进入profile.d 目录
cd /etc/profile.d
# 创建一个 hadoop.sh 文件
vim hadoop.sh
# 添加如下内容,保存退出
export HADOOP_HOME=/export/servers/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# 分发到其它节点
scp hadoop.sh root@hadoop02:$PWD
scp hadoop.sh root@hadoop03:$PWD
# 刷新(每个节点都执行)
source /etc/profile
# 测试(如果能进入hadoop 目录说明配置没问题)
cd $HADOOP_HOME
5. 修改core-site.xml 文件()
- 打开core-site.xml 文件
# 进入hadoop配置文件目录
cd $HADOOP_HOME/etc/hadoop
- 在configuration标签中 添加以下内容(记得修改为自己的路径和主机名)
<property>
<name>fs.defaultFSname>
<value>hdfs://hadoop01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop/hadoopDatas/tempDatasvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
6. 修改hdfs-site.xml 文件添加如下内容
- 打开 hdfs-site.xml
vim hdfs-site.xml
- 在configuration标签中 添加以下内容(记得修改为自己的路径和主机名)
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>hadoop01:50090value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>hadoop01:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop/hadoopDatas/namenodeDatasvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop/hadoopDatas/datanodeDatasvalue>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop/hadoopDatas/dfs/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///export/servers/hadoop/hadoopDatas/dfs/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///export/servers/hadoop/hadoopDatas/dfs/nn/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
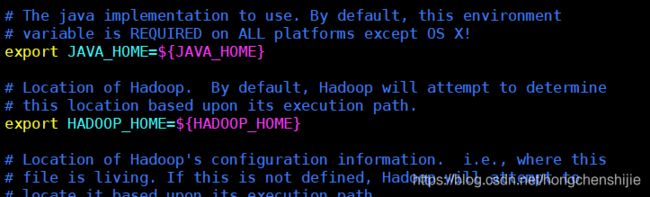
7. 修改hadoop-env.sh 文件
- 打开hadoop.env.sh 文件
vim hadoop.env.sh
- 修改如下内容
8. 修改mapred-site.xml 文件
- 打开vim mapred-site.xml 文件
vim mapred-site.xml
- 在configuration标签中 添加以下内容(记得修改为自己的主机名)
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.job.ubertask.enablename>
<value>truevalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop01:19888value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
9. 修改yarn-site.xml文件
- 打开yarn-site.xml 文件
vim yarn-site.xml
- 在configuration标签中 添加以下内容(记得修改为自己的主机名)
<property>
<name>yarn.resourcemanager.hostnamename>
<value>hadoop01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
10. 添加工作节点修改 workers文件
- 打开workers文件
vim workers
- 添加需要工作的节点(例如)
hadoop01
hadoop02
hadoop03
11. 创建文件目录
mkdir -p /export/servers/hadoop/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop/hadoopDatas/dfs/nn/edits
mkdir -p /export/servers/hadoop/hadoopDatas/dfs/snn/name
mkdir -p /export/servers/hadoop/hadoopDatas/dfs/nn/snn/edits
12. 分发hadoop到其它节点
# 进入安装目录
cd /export/install
# 分发hadoop 到其它节点
scp -r hadoop-3.2.1/ root@hadoop02:$PWD
scp -r hadoop-3.2.1/ root@hadoop03:$PWD
# 去另外两个节点上创建软链接
cd /export/servers
ln -s ../install/hadoop-3.2.1 hadoop
13. 初始化hadoop
hdfs namenode -format
14. 尝试启动,发现报错
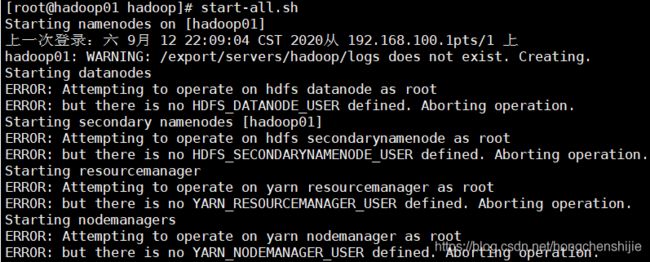
15. 解决
#进入hadoop脚本目录
cd $HADOOP_HOME/sbin
# 在start-dfs.sh文件最上面添加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 在stop-dfs.sh 文件最上面添加如下内容
HDFS_DATANODE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
# 在start-yarn.sh和stop-yarn.sh 文件中添加
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
# 拷贝到其它节点
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh root@hadoop02:$PWD
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh root@hadoop03:$PWD
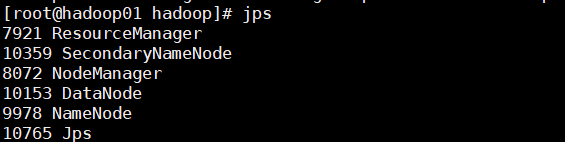
16. 重新启动 发现启动成功
#重启
start-all.sh
#使用jps命令进行检查
jps
- 主节点
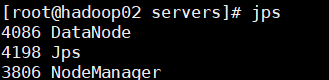
- 从节点 hadoop02
- 从节点 hadoop03
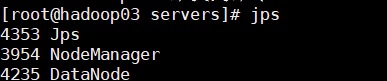
17. 测试mapreduce 任务
hadoop jar /export/servers/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar pi 10 100
18. 一点建议
# 1. 建议把start-all.sh 重命名为 start-all-hadoop.sh (每个节点都执行一下)
cd $HADOOP_HOME/sbin
mv start-all.sh start-all-hadoop.sh
# 2. stop-all.sh 重命名为 stop-all-hadoop.sh
mv stop-all.sh stop-all-hadoop.sh
#原因: 在spark 启动spark集群也是使用start-all.sh 启动,如果配置了spark变量很容造成冲突,最好的解决方法就是重命名
19. 配置jobHistory
- 进入配置文件目录
cd $HADOOP_HOME/etc/hadoop
- 打开mapred-site.xml 文件
vim mapred-site.xml
添加如下内容(如果您是根据我的博客搭建的集群,请跳过这一步,之前已添加过)
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop01:19888value>
property>
- 打开 yarn-site.xml 文件
vim yarn-site.xml
添加如下内容:
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>604800value>
property>
<property>
<name>yarn.nodemanager.log-aggregation.compression-typename>
<value>gzvalue>
property>
<property>
<name>yarn.nodemanager.local-dirsname>
<value>/export/install/hadoop-2.6.0/yarn/localvalue>
property>
<property>
<name>yarn.resourcemanager.max-completed-applicationsname>
<value>1000value>
property>
- 分发到其它节点
scp mapred-site.xml yarn-site.xml hadoop02:$PWD
scp mapred-site.xml yarn-site.xml hadoop03:$PWD
- 重启集群
stop-all-hadoop.sh
start-all-hadoop.sh
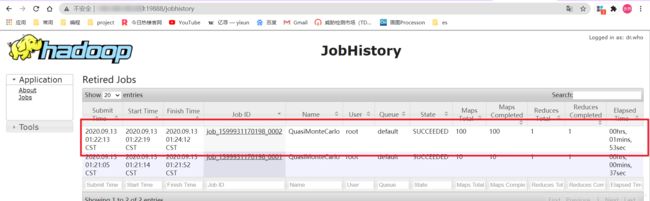
- 启动jobhistory
# hadoop3.0 推荐用此命令启动
mapred --daemon start historyserver
# 访问19888 端口
http://虚拟机ip地址:19888/jobhistory
20. 最后
- 如遇到问题可以在下方留言,共同探讨. 同时如果有不对的地方欢迎大佬指出.
- 如果我的博客对你有所帮助,可以的话点个赞,评论一波.