基于XGB单机训练VS基于SPARK并行预测(XGBoost4j-spark无痛人流解决方案)
作者·黄崇远
『数据虫巢』
全文共9000字
题图ssyer.com
“ Python训练VS并行化预测,无痛人流般的解决方案,你值得拥有。”
理解本文需要有一定的技术基础,包括对于Xgboost的基本理解以及使用经验,基本的Spark开发能力,如果对于Xgboost4j-spark有一定的了解就更好了。


01
诉求背景
在这里,我就不做XGB的科普了,如果不清楚的,请自行谷歌,官网。
首先我们确定我们需要做的事情,那就是尝试在Python单机的环境下训练模型,获取到模型文件,然后加载在Spark环境中做并行预测,涉及到并行预测会用到XGBoost4j-spark框架。
这看起来是一个伪诉求,为什么会存在使用单机来训练,然后跑到Spark上预测的这种诉求,比如存在以下几个问题。
(1) 为什么不直接在单机,比如Python的XGB上进行Train以及Predict?
(2) 为什么不直接在XGBoost4j-spark上做Train以及Predict?
上面两个问题简直就是灵魂拷问,看似合情合理,无法推翻。来,让我们来逐一探讨一下。
先说单机Python的XGB。
我们使用XGB通常是分类或者回归场景,是一种相对偏传统的做法(非深度学习系列),所以带标的数据样本量级通常不会太大,几万是常见的,几十万也能接受,上百万也能处理的了(单机的内存和核稍微大点),所以在Python单机上训练是没有太多压力的。
并且,Python本来就是一个脚本式的语言,所以代码非常简洁,跑起来非常快,离线部署起来也不难。由于Python对应的很多数据处理的相关库,对于数据探索,特征挖掘,进而进行模型调优是非常便捷的。
如果是处于一种正常迭代的情况下,你可能会处于反复调整采样方式,不断的增减模型,不断的调参的这种循环中,这需要一个轻量级并且灵活的环境来支持,而Python的环境恰巧非常符合。这意味着Python对应的XGB环境是比较利于这种良好迭代节奏的。
说完了训练,说预测,并且这里说的不是服务化实时预测,说的是批量离线预测的话题,因为如果是实时,就不存在使不使用Spark做并行预测的话题了。
如果说我们的预测场景是几十上百万,又甚至是上千万的量级,其实单机都能撸的过来,再不行就做多线程嘛(Python无法做多线程,但是逻辑里可以做多进程的方式来实现并行),再不行就切割数据,分散到多个节点嘛,最后再聚拢数据。
我曾把模型利用自己写的调度脚本进行并行化,并将预处理和预测错峰执行,再同时并行三个模型预测,调调一些调度参数,把128GB内存,以及64核的单机服务器打的满满的,2个小时3个模型分别做1亿多数据的二分类。
OK,这里是1亿数据,如果是2亿,3亿,5亿呢?然后如果不止3个模型,是十个八个模型呢?解决肯定是可以解决的,但是做资源分配,并行处理,甚至多机拆解任务会把人搞死。关键一旦跑起来之后这个机器就基本上干不了其他的了,这意味着这压根儿不存在啥资源调度的问题。
所以,需要解决这种大规模多模型预测对于资源的消耗问题,甚至是效率问题。
说完了单机,说Spark的多机,指的是XGB的spark框架代表XGBoost4j-spark。
模型并行化,好处当然大家都知道的,大规模的数据不管是训练还是预测,都“咻咻”的,并且不需要考虑训练或者预测资源的问题,资源不够多配点excute就好了,别说3亿数据,只要集群中有资源,10亿我都给你分分钟预测出来。
所以预测这层天然是符合这种大规模离线预测场景的。
回到训练,除了上述单机场景中的迭代领域这个优点也就是对应Spark的缺点。spark其实相对来说是一个比较笨重的框架,任务提交、任务的响应和执行需要比较费时,如果资源临时不够还得排排队,这对于我们需要快速灵活迭代模型的诉求是相悖的。
除了上面的缺点还有缺点吗?有的,XGBoost4j-spark的训练过程在数据量少的情况下,其训练带来的精度有可能是低于单机的,相当于进一步稀释了训练样本,这在于训练样本数本来就不算特别多的场景中,是有一定的影响的。
关于这一点,我们在后面拆解XGBoost4j-spark源码的时候再来进一步说明。
所以,在这里,在训练数据量百万级以内,离线预测量级在数亿以上的场景中,单机训练Spark并行预测的搭配太合适了,简直就是天造地设的...
好吧,差点出口成章了。既然如此般配,那么可以直接Python版的XGB训练好的Model,直接丢到XGBoost4j-spark中load,然后愉快的预测呢?
答案是不行!竟然是不行。我也很纳闷,为啥不行。做个工作流每天让Python定时训练模型,然后丢到Spark环境中每天做预测,然后还一边用Python来调模型,一旦模型指标非常OK的,离线验证之后,直接丢到Spark流程中替换。
这个过程是多么的自然,但结果竟然是不行。说好的XGBoost4j-spark是Xgboost的分支项目的呢,这也不像亲儿子啊。
真的是不行,所以才有了这个文章,和研究方向。我试图从源码中探索为什么不行,理论上一定行的事,然后找到这个路径的解决方案。
02
XGBoost单机源码拆解
代码来源:git clone --recursivehttps://github.com/dmlc/xgboost
这是XGB在github上的开源代码,其中也包括了XGBoost4j-spark这个分支的项目代码,一箭双雕。
首先来看下XGB主体部分的代码目录:
|--xgboost
|--include
|--xgboost //定义了 xgboost 相关的头文件
|--src
|--c_api
|--common //一些通用文件,如对配置文件的处理
|--data //使用的数据结构,如 DMatrix
|--gbm //定义了若分类器,如 gbtree 和 gblinear
|--metric //定义评价函数
|--objective //定义目标函数
|--tree //对树的一些列操作
从目录结构的角度看,代码层次结构,代码模块是非常干净利落的。
由于我们的重点不在于XGB的单机代码,如果对XGB感兴趣的,可以沿着cli_main.cc的执行入口,再到训练的核心方法CLITrain(param),再到Learner::UpdateOneIter()的实际树更新逻辑,再到Learner里头实现ObjFunction::GetGradient()梯度求解的过程(包括Loss函数,一阶和二阶的导师计算)。
然后在Tree的执行逻辑里,提供了上述所说的Updater逻辑,实际建树的各种策略。
|--src
|--tree
|--updater_basemaker-inl.h //定义了派生子TreeUpdater的类BaseMaker
|--updater_colmaker.cc
//ColMaker使用基于枚举贪婪搜索算法,通过枚举所有特征来寻找最佳分裂点
|--updater_skmaker.cc
//SkMaker派生自BaseMaker的,使用,使用近似sketch方法寻找最佳分裂点
|--updater_refresh.cc //TreeRefresher用于刷新数据集上树的统计信息和叶子指
|--updater_prune.cc //TreePruner是树的兼职操作
|--updater_hismaker.cc //HistMaker直方图法
|--updater_fast_hist.cc //快速直方图
这里对于单机版的源码就不作过多分析和拆解,重点是Xgboost4j-spark。
03
XGBoost4j-spark的训练过程
关于XGBoost基于Spark的分布式实现,实际上是基于RABIT(dmlc开源的底层通信框架)实现。Spark版本的建树逻辑基本和单机版一致,计算上区别在于:并行的特征计算在不同的服务器上进行,计算结果需要通过消息在Tracker(负责控制计算逻辑)上进行汇总。这个动作是可以大大加快特征层并行化的效率的。
并且,由于项目结构上的关系,比如XGBoost4j-spark本来就是作为XGBoost的分支项目而存在的,所以一定不会大规模造轮子,能用的轮子尽量用,这是项目构建原则,所以,我们要找到Spark分布式版本与单机版本的关联性。

这张图,在分析很多XGBoost并行化原理时都用到,具体原图出自于哪,无法考究了,先借用下。
我们可以看到这是一个典型的Spark任务的逻辑结构图,以Tracker为壳子的Task在最外层,内层是单个RABIT节点,然后下面挂着一个看着很熟悉的XGBoost训练任务。没错,不是很熟悉,是真的单机XGBoost训练任务。
trainWithRDD方法内部会检查cpu、nWorkers等参数,并完成资源分配计划。接着启动rabit tracker(用于管理实际计算的rabit worker),调用buildDistributedBoosters进行分布式初始化和计算。
buildDistributedBoosters方法是核心部分。先根据参数nWorkers对数据进行repartition(nWorkers)操作,进行数据重分布,接着,直接调用mapPartion进行partition层面的数据逻辑处理。可以看出,nWorkers决定了最终数据的partition情况,以及rabit worker的数量。在RDD partition内部,数据会先进行稀疏化处理,然后再转为JXGBoost接受的数据结构。接着,启动rabit worker 和JXGBoost进行训练。
至此spark 的分布式模型转化为JXGBoost的分布式训练。从结果上看,spark就像是数据和资源管理的框架,核心的训练过程还是封装在rabit中。上述的接口调用的整体流程如下图:
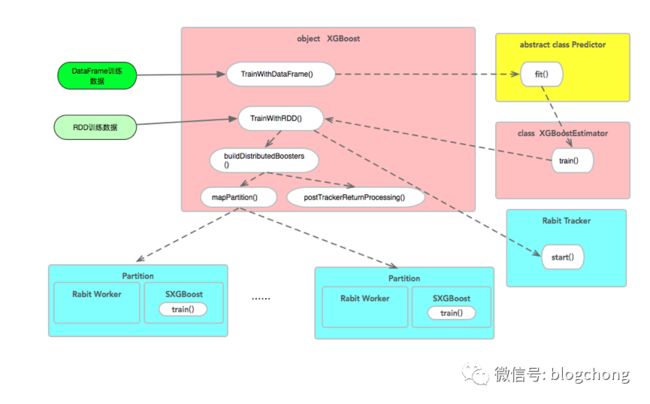
这图依然是借用的,甚至上面两段话的总结大部分都是参考过来的,跟我直接看源码的结论差不多,所以总结凑合着看。下面,我们来拆解代码。
训练的入口是XGBoostClassifier.fit,但实际上调用的是XGBoostClassificationModel.train
在这一步里,有几个关键动作,先对一些参数进行判断。
=>判断一些关键参数
+判断evalMetric
+判断objectiveType
+判断numClass
+判断weightCol
+判断baseMarginCol
然后一个是如上面总结所说的,先对数据进行了转换,转换入口是DataUtils.convertDataFrameToXGBLabeledPointRDDs,输出是trainingSet,相当于数据已经转换ready好。
=>转换RDD类型:
DataUtils def convertDataFrameToXGBLabeledPointRDDs(
labelCol: Column,
featuresCol: Column,
weight: Column,
baseMargin: Column,
group: Option[Column],
dataFrames: DataFrame*)
PS:统一转换为dataset为float类型
+分为有特征权重与无特征权重两种
+内部转换分为sparseVector和DenseVector两个处理 value.map(_.tofloat)
+XGBLabeledPoint //序列化?
更重要的动作在于:
val (_booster, _metrics) = XGBoost.trainDistributed(trainingSet, derivedXGBParamMap, hasGroup = false, evalRDDMap)
val model = new XGBoostClassificationModel(uid, _numClasses, _booster)
这意味着,通过这个函数调用,最终拿到了model。我们进一步来看trainDistributed内部的实现。
trainDistributed(XGBoost类)
核心的解释是:通过Spark的Partitions到Rabit分布式执行,返回booster。
其中包括parameterFetchAndValidation做关键参数处理,包括这些参数num_workers,num_round,use_external_memory,custom_obj,custom_eval,missing。
还有结合了Spark以及Rabit的断点管理类:CheckpointManager方法。
对于对trainDf进行repartitionForTraining的composeInputData方法。
通过checkpointManager.loadCheckpointAsBooster来构建一个Booster。
到了关键之处,结合CheckPoint做树训练轮次的遍历,checkpointManager.getCheckpointRounds,并且这个为下一个关键实现节点,我们在拆细到内部来看。
checkpointRound循环内部
startTracker,实际上一个RabitTracker,启停拿到work等待资源等操作。然后通过SparkParallelismTracker将core等资源给到tracker,总之是属于Spark相关逻辑范畴。
然后到了关键有点迷的地方:
val boostersAndMetrics = if (hasGroup) {
trainForRanking(transformedTrainingData.left.get, overriddenParams, rabitEnv,
checkpointRound, prevBooster, evalSetsMap)
} else {
trainForNonRanking(transformedTrainingData.right.get, overriddenParams, rabitEnv,
checkpointRound, prevBooster, evalSetsMap)
}
我们看到有两个分支,关键判断节点在于hasGroup,我们追踪这个变量,发现在XGBoost.trainDistributed方法调用是,默认就是false,然后在后续的处理逻辑中,压根儿就没有被赋值过了,那么这里做两条分支的意义在哪?暂时没有找到答案。
严格意义上说,我们看trainForNonRanking的核心执行逻辑就行了。
trainForNonRanking内部逻辑
首先是buildWatches,内部把trainPoints分为train部分和test部分,根据外部传参train_test_ratio控制,调用Watches(有点像是对train数据集的另外一个包装)。
然后肉戏又来了,关键的分布式预测过程,buildDistributedBooster,底层依赖Rabit,先拿到对应的train数据集的Partitions。
buildDistributedBooster内部逻辑
val booster = SXGBoost.train(watches.toMap("train"), overridedParams, round,watches.toMap, metrics, obj, eval,earlyStoppingRound = numEarlyStoppingRounds, prevBooster)
但实际上更底层调用的是JXGBoost.train。
xgboostInJava=JXGBoost.train(dtrain.jDMatrix,params.filter(_._2 != null).mapValues(_.toString.asInstanceOf[AnyRef]).asJava,round, jWatches, metrics, obj, eval, earlyStoppingRound, jBooster)
JXGBoost.train逻辑
更底层的逻辑:
+begin to train
{
+booster.update(dtrain, obj); //更新booster。
//调用Booster原生类,内部进行叶子节点的predict,然后算train数据和predict(XGBoostJNI.XGBoosterPredict)出来的梯度getGradient(梯度计算类IObjective)
//然后更新公式中的Grad和Hess,boost(dtrain, gradients.get(0)=grad, gradients.get(1)=hess),实际调用底层XGBoostJNI.XGBoosterBoostOneIter
}
+evaluation //评估,使用metricts
+booster.saveRabitCheckpoint()
+Iterator(booster -> watches.toMap.keys.zip(metrics).toMap) //在watches范围内循环迭代
在这里,比如XGB一阶和二阶求解的时候,调用了更加底层的原生接口XGBoostJNI.XGBoosterBoostOneIter。
在执行完train动作之后:
+val (booster, metrics) =def postTrackerReturnProcessing(trackerReturnVal: Int,distributedBoostersAndMetrics: RDD[(Booster, Map[String, Array[Float]])],sparkJobThread: Thread): (Booster, Map[String, Array[Float]])
//重要:distributedBoostersAndMetrics最终整合成一个booster与metrics元组,处理过程val (booster, metrics) = distributedBoostersAndMetrics.first()
=>Any of "distributedBoostersAndMetrics" can be used to create the model. ?
最让我迷的地方来了,在PostTracker之后,其实就是各个Tracker通讯逻辑了,我们上面可以看到实际上每个Tracker都训练了一个XGB,并且从返回值也可以看到是一个distributedBoostersAndMetrics: RDD[(Booster, Map[String, Array[Float]])],这种数据结构的数据。
实际上就是一个Booster与混淆矩阵的集合,但该方法的返回值只有一个booster和metrics的元组对,所以一定在内部做了选择或者合并或者相关逻辑。
通过深入可以看到,实际上从这个方法注释上有一句可以看到端倪“Any of "distributedBoostersAndMetrics" can be used to create the model. ”。这意味着他是选择其中的一个booster作为结果的,再一看,我擦,直接.first(),让我有点难以接受。
Booster都拿到了,整个Train的过程也就结束了。我们可以看到分布式的训练过程并没有想象中复杂,也没有想象中起到那么牛逼的作用,特征并行化这部分没有细说,但是从切分TrainSet到通过RDD进行类似单机的XGB训练,这部分的逻辑是相对清晰的,只不过最终选择Booster的过程是如此的随意有点难以接受。
04
XGBoost4j-spark的预测过程
本质上是把加载或者训练好的booster进行广播,减少通讯的时间,然后rdd进行按row预测,实际调用的是JVM原生Predict接口,简单的要命。
XGBoostJNI.XGBoosterPredict
dataset.map{
rowIterator =>
+missing值填充
+feature格式化
输出=>val Array(rawPredictionItr, probabilityItr, predLeafItr, predContribItr) = producePredictionItrs(bBooster, dm)
过程{
+Broadcast[Booster] //model=>booster对训练好的booster进行广播 =》 broadcastBooster.value.predict =》 Booster:booster.predict(data.jDMatrix, outPutMargin, treeLimit) =》XGBoostJNI.XGBoosterPredict
}
}
结论:本质上通过RDD进行分布式切割,然后逐行Row读取,通过对Booster的广播避免变量传递通讯,然后做逐个predict,其实我们自己也可以写这个过程的,只要有了Booster之后,重点是如何解决Booster的生成。
05
XGBoost4j-spark的模型保存过程
重点关注Xgboost4j保存过程与单机保存过程不一致的地方,将有助于我们解决开头部分无法直接加载单机训练的model的问题。
class XGBoostClassificationModelWriter(instance: XGBoostClassificationModel) extends MLWriter {
override protected def saveImpl(path: String): Unit = {
// Save metadata and Params
implicit val format = DefaultFormats
implicit val sc = super.sparkSession.sparkContext
DefaultXGBoostParamsWriter.saveMetadata(instance, path, sc)
// Save model data
val dataPath = new Path(path, "data").toString
val internalPath = new Path(dataPath, "XGBoostClassificationModel")
val outputStream = internalPath.getFileSystem(sc.hadoopConfiguration).create(internalPath)
outputStream.writeInt(instance.numClasses)
instance._booster.saveModel(outputStream)
outputStream.close()
}
}
代码解释:
(1) instance,实际上就是train好的model
(2) save动作分三部分,第一部分保存saveMetadata,第二部分往4j版的model文件写instance.numClasses,第三步,保存booster,instance._booster.saveModel(outputStream)
重点关注metadata的内容是什么,booster保存的跟单机保存差别不大,实际也是调用的outputStream.write(this.toByteArray())。
def saveMetadata(
instance: Params, //instance重点也是取里头的Params
path: String,
sc: SparkContext,
extraMetadata: Option[JObject] = None,
//实际上看调用,后面两个参数使用的是默认参数
paramMap: Option[JValue] = None): Unit = {
val metadataPath = new Path(path, "metadata").toString
val metadataJson = getMetadataToSave(instance, sc, extraMetadata, paramMap)
//重点函数
sc.parallelize(Seq(metadataJson), 1).saveAsTextFile(metadataPath)
}
=》getMetadataToSave方法:实际就是把模型的参数表(就是XGB的参数表,转换成json格式)+uid,classname,timestamp,sparkVersion。
可以看到,实际上metadata保存的确实是一些元数据信息,并且其保存的内容确实“别具特色”,难怪单机版的model无法直接加载,但实际上我们只需要instance._booster.saveModel(outputStream)这部分。
06
XGBoost4j-spark的模型加载过程
说完保存,我们来研究xgboost4j具有独特的模型加载过程,单本质上还是为了获取booster。
private class XGBoostClassificationModelReader extends MLReader[XGBoostClassificationModel] {
/** Checked against metadata when loading model */
private val className = classOf[XGBoostClassificationModel].getName
override def load(path: String): XGBoostClassificationModel = {
implicit val sc = super.sparkSession.sparkContext
val metadata = DefaultXGBoostParamsReader.loadMetadata(path, sc, className)
val dataPath = new Path(path, "data").toString
val internalPath = new Path(dataPath, "XGBoostClassificationModel")
val dataInStream = internalPath.getFileSystem(sc.hadoopConfiguration).open(internalPath)
val numClasses = dataInStream.readInt()
val booster = SXGBoost.loadModel(dataInStream)
val model = new XGBoostClassificationModel(metadata.uid, numClasses, booster)
DefaultXGBoostParamsReader.getAndSetParams(model, metadata)
model
}
}
XGBoostClassificationModelReader类的load方法入口。传入的Model路劲,实际上是个文件夹:
+metadata //保存了元数据信息
+data/XGBoostClassificationModel //保存了二进制的Booster
Booster的实际load过程:
val booster = SXGBoost.loadModel(dataInStream)
=》new Booster(JXGBoost.loadModel(in))
=> Booster.loadModel(in);
=>XGBoostJNI.XGBoosterLoadModelFromBuffer
PS:最终可以看到,实际调用的依然是XGBoostJNI原生接口。
metadata的作用:
入口:DefaultXGBoostParamsReader.getAndSetParams(model, metadata)
/**
* Extract Params from metadata, and set them in the instance.
* This works if all Params implement [[org.apache.spark.ml.param.Param.jsonDecode()]].
* TODO: Move to [[Metadata]] method
*/
def getAndSetParams(instance: Params, metadata: Metadata): Unit = {
implicit val format = DefaultFormats
metadata.params match {
case JObject(pairs) =>
pairs.foreach { case (paramName, jsonValue) =>
val param = instance.getParam(handleBrokenlyChangedName(paramName))
val value = param.jsonDecode(compact(render(jsonValue)))
instance.set(param, handleBrokenlyChangedValue(paramName, value))
}
case _ =>
throw new IllegalArgumentException(
s"Cannot recognize JSON metadata: ${metadata.metadataJson}.")
}
}
所以,由于booster内部已经保存了我们所需要的各种树状结构,以及相关的参数,所以 instance.set(param, handleBrokenlyChangedValue(paramName, value))的动作实际上是没有本质意义的。
07
基于XGBoost4j-spark的解决方案
从上面几个大步骤的分析,我们可以得出以下几个结论。
首先,从目前看,在数据量不大的时候,还对样本进行RDD的切分,在做分布式的Booster训练,在做选择,其实是把样本进一步切分小了,在样本本来就不多的情况下,并不是一个好事情,还不如用单机来训练。
其次,单机预测的Booster到底能不能在Spark中用,答案这回是肯定的。我们通过源码分析可以知道,XGBoost4j-spark只要涉及到底层的逻辑,都是调用原生的XGBoostJNI入口,不管是计算一阶二阶导数,还是直接predict还是train,包括求解梯度等等,都是如此。
我就说嘛,XGBoost4j-spark不可能脱离开XGBoost单独造这么多轮子的,,所以更多的是利用Spark的资源调度的能力,相当于包了层壳子。
基于这个结论,单机拿到的Booster一定能在XGBoost4j-spark上用来predict。
结合模型save和load的分析,其实要解决加载的问题很简单,那就是构造一个load入口。
如果要做侵入式的解决,那就修改源码中的load函数,直接把什么metadata虚头巴脑的过程给咔嚓掉,只留下SXGBoost.loadModel(dataInStream)的精华部分。然后重新编译打包,做成你的第三方外部依赖。
我个人认为这种方案是一个次的方案,比较死板,并且这种侵入式的更改逻辑非常麻烦,需要编译打包。
还有一种无侵入式的解决方案就是,我叫他“劫持接口”,即我们不调用XGBoost4j-spark的load方法,我们调用我们自己的load方法,然后修改逻辑在这里修改,然后剩下的底层部分使用XGBoost4j-spark的逻辑,相当于我们只是劫持了这一部分,然后按需修改。
如果需要达到这个目的,我们就需要写一个类似XGBoostClassificationModelReader的类,比如我们称之为XGBoostClassificationModelReaderBlogchong类,然后同样继承MLReader[XGBoostClassificationModel]。这样对于底层的实现就不需要再重复实现了。
private class XGBoostClassificationModelReader extends MLReader[XGBoostClassificationModel] {
private val className = classOf[XGBoostClassificationModel].getName
override def load(path: String): XGBoostClassificationModel = {
implicit val sc = super.sparkSession.sparkContext
val metadata = DefaultXGBoostParamsReader.loadMetadata(path, sc, className)
val dataPath = new Path(path, "data").toString
val internalPath = new Path(dataPath, "XGBoostClassificationModel")
val dataInStream = internalPath.getFileSystem(sc.hadoopConfiguration).open(internalPath)
val numClasses = dataInStream.readInt()
val booster = SXGBoost.loadModel(dataInStream)
val model = new XGBoostClassificationModel(metadata.uid, numClasses, booster)
DefaultXGBoostParamsReader.getAndSetParams(model, metadata)
model
}
}
其中,我们把metadata部分移除,还需要注意XGBoost4j-spark在二进制文件的头部“掺了点沙子”,即分类的类别数numClasses,统统干掉。只留下loadModel的部分。
然后调用预测的transform方法,愉快的玩耍吧。
08
总结
整个优化方案其实非常简单,但是要做出这个方案需要很多的判断,比如Booster是否一致性,这决定了根本性的二进制文件是否能迁移的问题。
此外,对于实际上两种方式的模型保存的差异性要搞清楚,搞清楚了差异才能回到统一的解决路子上,所以才会拆解Save和Load的过程。
不过话又说回来,本质上Predict的过程并不难,也是拆解完其执行逻辑之后,发现其实就是RDD切割数据,然后Booster广播,然后类似单机的predict预测。
我们自己也可以不用框架实现这个目标,比如使用Java的XGB,然后在RDD内部做单机预测,其实逻辑也是类似的,结论真是有点让人悲伤。
不过,既然提供了XGBoost4j-spark框架,我们还是可以用起来的,毕竟是官方推荐版本,内部做了流程上的优化,而且要我们自己写一大段代码也是很复杂的(目测了下transform的逻辑近千行代码还是有的),何必呢。
至此,本文核心内容就结束了。
其实这个研究的起点,正式之前我所说的,大规模离线预测单机受限,且实操下来发现XGBoost4j-spark的预测过程对于网络通信要求非常高,并不是十分的稳定,经常出现RPC通讯相关的错误。此外就是,对于train的资源配置,需要花点耐心。总之,这些都是不太好的地方。
基于这种特殊的场景诉求,所以把源码撸了一遍,然后解决方案竟然是如此简单,大有吃力不讨好的味道?其实不是的,任何一步的改动都需要有足够的理论支撑,而看源码,寻找代码的逻辑结构是找理论依据,依据寻找解决方案。
至于上面说到的“接口劫持”这种无侵入的解决方案,其实非常适用类似的场景,比如需要修改一些知名框架的时候,又不想大动干戈的修改编译源码,这种方式就非常轻量级了,简直就是代码界的“无痛人流”。
参考文献
【01】https://github.com/dmlc/xgboost

文章都看完了,来个赏ba~

--凌晨1点,求知使我快乐并动力十足。
对于新手朋友,或者一些处于开发分析状态想了解一些数据挖掘相关技能的朋友,或者是刚毕业将要毕业想从事数据方向的应届朋友,以及对广告感兴趣的朋友(职业广告数据挖掘从业人员),欢迎加入我的知识星球。
