Java中文乱码字符集解决大全-(转)阿童沐
原来用的方法:过滤器
get传//获取request中的参数(包含中文的参数),并转换为utf-8 value = new String(value.getBytes(“iso-8859-1”), “utf-8”);
request.setCharacterEncoding(“utf-8”);
response.setContentType(“text/html;charset=utf-8”);
response.setCharacterEncoding(“utf-8”);//服务器端编码
<%@ page pageEncoding="utf-8" contentType="text/html; charset=ISO-8859-1"%>//ISO-8859-1 网页信息 导致乱码
<%
response.setCharacterEncoding("utf-8"); //修正 可以正确显示
%>
Test Character
public class CharTest extends HttpServlet
{
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
// TODO Auto-generated method stub
req.setCharacterEncoding("GBK"); //设置从客户端接收到的字符的编码格式,并按照这种编码格式进行解码
resp.setContentType("text/html;charset=utf-8"); //设置返回给客户端的字符的编码方式,通过http协议指定客户端按照这种编码方式进行解码转换
String name = req.getParameter("name");
String id = req.getParameter("id");
PrintWriter out = resp.getWriter();
out.println("
");
out.println("你所输入的中文字符串是:" + name);
out.println("
你输入的id是:" + id);
out.println("
");
}
@Override
public void doPost(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException
{
// TODO Auto-generated method stub
this.doGet(req, resp);
}
输出结果 name 是乱码

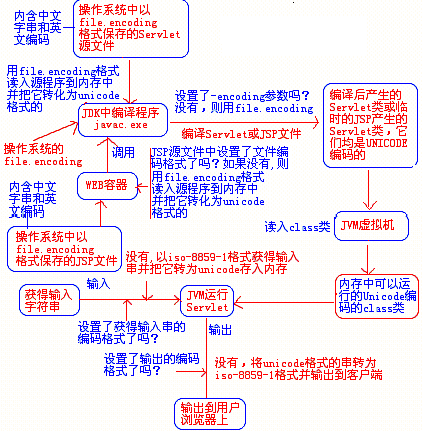
首先,经过上面的详细分析,我们可以清晰地看到,任何JAVA程序的生命期中,其编码转换的关键过程是在于:最初编译成class文件的转码和最终向用户输出的转码过程。
其次,我们必须了解JAVA在编译时支持的、常用的编码格式有以下几种:
*ISO-8859-1,8-bit, 同8859_1,ISO-8859-1,ISO_8859_1等编码
*Cp1252,美国英语编码,同ANSI标准编码
*UTF-8,同unicode编码
*GB2312,同gb2312-80,gb2312-1980等编码
*GBK , 同MS936,它是gb2312的扩充
及其它的编码,如韩文、日文、繁体中文等。同时,我们要注意这些编码间的兼容关体系如下:
unicode和UTF-8编码是一一对应的关系。GB2312可以认为是GBK的子集,即GBK编码是在gb2312上扩展来的。同时,GBK编码包含了20902个汉字,编码范围为:0x8140-0xfefe,所有的字符可以一一对应到UNICODE2.0中来。
再次,对于放在操作系统中的.java源程序文件,在编译时,我们可以指定它内容的编码格式,具体来说用-encoding来指定。注意:如果源程序中含有中文字符,而你用-encoding指定为其它的编码字符,显然是要出错的。用-encoding指定源文件的编码方式为GBK或gb2312,无论我们在什么系统上编译含有中文字符的JAVA源程序都不会有问题,它都会正确地将中文转化为UNICODE存储在class文件中。
然后,我们必须清楚,几乎所有的WEB容器在其内部默认的字符编码格式都是以ISO-8859-1为默认值的,同时,几乎所有的浏览器在传递参数时都是默认以UTF-8的方式来传递参数的。所以,虽然我们的Java源文件在出入口的地方指定了正确的编码方式,但其在容器内部运行时还是以ISO-8859-1来处理的,这里类似于JDK内部编码方式是使用UNICODE。
一套建议最优的解决汉字问题的办法
我们的目标是:我们在中文系统中编辑的含有中文字符串或进行中文处理的JAVA源程序经编译后可以移值到任何其它的操作系统中正确运行,或拿到其它操作系统中编译后能正确运行,能正确地传递中文和英文参数,能正确地和数据库交流中英文字符串。
我们的具体思路是:在JAVA程序转码的入口和出口及JAVA程序同用户有输入输出转换的地方限制编码方法使之正确即可。
具体解决办法如下:
1、 针对直接在console上运行的类
对于这种情况,我们建议在程序编写时,如果需要从用户端接收用户的可能含有中文的输入或含有中文的输出,程序中应该采用字符流来处理输入和输出,具体来说,应用以下面向字符型节点流类型:
对文件:FileReader,FileWrieter
其字节型节点流类型为:FileInputStream,FileOutputStream
对内存(数组):CharArrayReader,CharArrayWriter
其字节型节点流类型为:ByteArrayInputStream,ByteArrayOutputStream
对内存(字符串):StringReader,StringWriter
对管道:PipedReader,PipedWriter
其字节型节点流类型为:PipedInputStream,PipedOutputStream
同时,应该用以下面向字符型处理流来处理输入和输出:
BufferedWriter,BufferedReader
其字节型的处理流为:BufferedInputeStream,BufferedOutputStream
InputStreamReader,OutputStreamWriter
其字节型的处理流为:DataInputStream,DataOutputStream
其中InputStreamReader和OutputStreamWriter用于将字节流按照指定的字符编码集转换到字符流,如:
InputStreamReader in = new InputStreamReader(System.in,"GB2312");
流程如下:
1>首先从控制台获取到输入的字节流,这里需要知道字节流是采用何种字符集进行编码的,这里是GB2312;
2>程序使用GB2312字符集对输入程序的字节流进行解码,然后转换成为Java虚拟机内部使用的UNICODE格式;
3>通过InputStreamReader的方法获取到的字符流在程序中就变成了可用的UNICODE编码格式字符串。
OutputStreamWriter out = new OutputStreamWriter (System.out,"GB2312");
流程如下:
1>程序中首先准备好字符或字符串,这里使用的是JDK内部的UNICODE编码方式的字符串;
2>对字符串通过UNICODE -> GB2312 进行字节流转码;
3>将转换后的字节流通过write()函数写入输出流中,这样输出流中的字节流就是原来字符串的GB2312编码方式得到的。
这里均指定gb2312字符集的原因是中文windows操作系统均使用GBK字符集编码和解码,(从控制台输入的字符和想控制台输出的字符一定要采用GB2312编码格式
3、 针对Servlet类
在编译Servlet类的源程序时,用-encoding指定编码为GBK或GB2312,且在向用户输出时的编码部分用response.setContentType(“text/html;charset=GB2312”);或GBK来设置输出编码格式,同样在接收用户浏览器方面的输入时,我们用request.setCharacterEncoding(“GB2312”);这样无论我们的servlet类移植到什么操作系统中,只有客户端的浏览器支持中文显示,就可以正确显示
public class HelloWorld extends HttpServlet
{
public void init() throws ServletException
{
}
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException
{
request.setCharacterEncoding("GB2312"); // 设置输入编码格式
response.setContentType("text/html;charset=GB2312"); // 设置输出编码格式
PrintWriter out = response.getWriter(); // 建议使用PrintWriter输出
out.println("
");
out.println("Hello World! This is created by Servlet!测试中文!");
out.println("
");
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws IOException, ServletException
{
request.setCharacterEncoding("GB2312"); // 设置输入编码格式
response.setContentType("text/html;charset=GB2312"); // 设置输出编码格式
String name = request.getParameter("name");
String id = request.getParameter("id");
if (name == null)
name = "";
if (id == null)
id = "";
PrintWriter out = response.getWriter(); // 建议使用PrintWriter输出
out.println("
");
out.println("你传入的中文字串是:" + name);
out.println("
你输入的id是:" + id);
out.println("
");
}
public void destroy()
{
}
}
<%@page contentType="text/html; charset=gb2312"%>
<%request.setCharacterEncoding("GB2312");%>
5、 针对JSP代码
<%@page pageEncoding="GB2312"%>//JSP编译器能正确地解码我们的含有中文字符的JSP文件
<%@page contentType="text/html; charset=gb2312"%>保证JSP向客户端输出时是采用中文编码方式输出的
<%request.setCharacterEncoding("GB2312");%>//为了让JSP能正确获得传入的参数
<%
String action = request.getParameter("ACTION");
String name = "";
String str = "";
if(action!=null && action.equals("SENT"))
{
name = request.getParameter("name");
str = request.getParameter("str");
}
%>
你输入的字符为:"+name);
out.println("
你通过URL传入的字符为:"+str);
}
%>