二叉树题目合集【Python】
这篇文章记录了leetcode上目前遇到的二叉树的题目。
110. 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
本题中,一棵高度平衡二叉树定义为:
一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4
返回 false 。
思路:
方法一 自顶向下先序遍历思路
此方法容易想到,但会产生大量重复计算
思路是构造一个求树深度的函数getHeight,用先序遍历的思路,首先判断当前根节点是否平衡。即判断根节点的左右子树高度差是否<=1,接着递归地判断左右子树分别是否是平衡二叉树。由于计算的时候是自顶向下,在计算完父亲节点树的高度后,在递归子树又要重新计算子树高度,所以会有很多重复计算子树高度的步骤,复杂度较高。
时间复杂度 O ( N l o g N ) O(NlogN) O(NlogN), N N N为树节点个数:最差情况下,当树是满二叉树时,isBalanced(root)遍历树所有节点,判断每个节点的深度depth(root)需要遍历 各子树的所有节点 。(若不满足平衡,会直接返回,而不会遍历到它的子树,所以最坏情况是满二叉树)
- 满二叉树高度的复杂度 O ( l o g N ) O(log N) O(logN) ,将满二叉树按层分为 l o g ( N + 1 ) log (N+1) log(N+1)层;
- 通过调用
depth(root),判断二叉树各层的节点的对应子树的深度,需遍历节点数量为 N × 1 N \times 1 N×1, N − 1 2 × 2 \frac{N-1}{2} \times 2 2N−1×2, N − 3 4 × 4 \frac{N-3}{4} \times 4 4N−3×4, N − 7 8 × 8 \frac{N-7}{8} \times 8 8N−7×8, …, 1 × N + 1 2 1 \times \frac{N+1}{2} 1×2N+1, 因此各层执行depth(root)的时间复杂度为 O ( N ) O(N) O(N)(每层开始,最多遍历 N N N个节点,最少遍历 N + 1 2 \frac{N+1}{2} 2N+1个节点)。
其中, N − 3 4 × 4 \frac{N-3}{4} \times 4 4N−3×4代表从此层开始总共需遍历 N − 3 N-3 N−3 个节点,此层共有 4 个节点,因此每个子树需遍历 N − 3 4 \frac{N-3}{4} 4N−3 个节点。
- 因此,总体时间复杂度 = 每层执行复杂度 × \times × 层数复杂度 = O ( N × l o g N ) O(N×logN) O(N×logN) 。

空间复杂度 O ( N ) O(N) O(N): 最差情况下(树退化为链表时),系统递归需要使用 O ( N ) O(N) O(N)的栈空间。
def isBalanced(self, root):
"""
自顶向下,先序遍历,先判断根节点的左右子树高度差,再递归判断左右子树
最差情况下(为 “满二叉树” 时), isBalanced(root) 遍历树所有节点,判断每个节点的深度 depth(root) 需要遍历各子树的所有节点 。
满二叉树的复杂度为logn, 每层计算该层节点的深度需要遍历该层以下所有节点,所以复杂度为n 最终复杂度为nlogn
"""
def getHeight(root):
if not root:
return 0
return max(getHeight(root.left), getHeight(root.right)) + 1
if not root:
return True
return abs(getHeight(root.left) - getHeight(root.right)) <= 1 and \
self.isBalanced(root.left) and self.isBalanced(root.right)
方法二 自底向上后序遍历思路
自顶向下的方法,会重复计算很多子树的高度。那么自底向上的思路就是以后序遍历的顺序,用helper函数向上传递当前子树的高度:如果高度为-1,说明不平衡,直接返回-1。
root为空,平衡,返回高度为0- 递归计算左子树高度,如果高度为-1,说明左子树不平衡,直接返回-1
- 递归计算右子树高度,如果高度为-1,说明右子树不平衡,直接返回-1
- 判断左右子树高度差是否<=1,如果不满足说明不平衡,直接返回-1;如果满足,返回树的高度为
max(left, right) + 1
时间复杂度 O ( N ) O(N) O(N): N N N 为树的节点数;最差情况下,需要递归遍历树的所有节点。
空间复杂度 O ( N ) O(N) O(N): 最差情况下(树退化为链表时),系统递归需要使用 O ( N ) O(N) O(N) 的栈空间。
def isBalanced2(self, root):
"""
自底向上,后序遍历,左右中
1. 先递归计算左右子树的高度(如果为-1,代表不是平衡,可以剪枝,直接返回-1给根节点)
2. 再由计算得到的左右子树高度,来计算根节点树的高度(或不平衡,高度值为-1)
最差情况,递归遍历树的所有节点,时间复杂度n
"""
def helper(root):
"""
如果root是平衡的,那么返回这棵树的高度
如果root不平衡,那么返回-1
"""
if not root:
return 0
# 计算左子树高度
left = helper(root.left)
if left == -1:
return -1
# 计算右子树高度
right = helper(root.right)
if right == -1:
return -1
if abs(left - right) > 1:
return -1
else:
return max(left, right) + 1
return helper(root) != -1
563. 二叉树的坡度
给定一个二叉树,计算整个树的坡度。
一个树的节点的坡度定义即为,该节点左子树的结点之和和右子树结点之和的差的绝对值。空结点的的坡度是0。
整个树的坡度就是其所有节点的坡度之和。
示例:
输入:
1
/ \
2 3
输出:1
解释:
结点 2 的坡度: 0
结点 3 的坡度: 0
结点 1 的坡度: |2-3| = 1
树的坡度 : 0 + 0 + 1 = 1
思路:
方法一 自顶向下
从计算根节点的坡度开始,一直到计算孩子节点坡度。先序遍历的顺序
def findTilt(self, root):
"""
自顶向下
"""
self.ans = 0
def sumTree(root):
if not root:
return 0
return sumTree(root.left) + sumTree(root.right) + root.val
def traverse(root):
"""
计算root的坡度
"""
if not root:
return 0
# 先计算根节点树的和,来得到坡度
self.ans += abs(sumTree(root.left) - sumTree(root.right))
# 然后递归到求左右孩子的坡度,这样的话,子树的节点和就会计算多次
traverse(root.left)
traverse(root.right)
traverse(root)
return self.ans
方法二 自底向上
先计算左右孩子子树的节点和,再向上计算传递根节点树的节点和。
def findTilt2(self, root):
"""
自底向上
先计算左右子树的和,再累加坡度,再计算当前树的和
"""
self.ans = 0
def traverse(root):
"""
计算树的节点和
"""
if not root:
return 0
left = traverse(root.left)
right = traverse(root.right)
self.ans += abs(left - right)
return left + right + root.val
traverse(root)
return self.ans
617. 合并二叉树
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
输入:
Tree 1 Tree 2
1 2
/ \ / \
3 2 1 3
/ \ \
5 4 7
输出:
合并后的树:
3
/ \
4 5
/ \ \
5 4 7
注意: 合并必须从两个树的根节点开始。
思路:
我们目标是将t2合并到t1中去,采用递归的思路:
- 如果
t1为空,则返回t2 - 如果
t2为空,则返回t1 - 如果
t1和t2都不为空,则用先序遍历的顺序,先更新t1节点的值为t1.val += t2.val,然后递归的更新t1的左子树为合并t1的旧左子树和t2的左子树,更新t1的右子树为合并t1的旧右子树和t2的右子树。
时间复杂度: O ( N ) O(N) O(N),其中 N N N 是两棵树中节点个数的较小值。
空间复杂度: O ( N ) O(N) O(N),在最坏情况下,会递归 N N N层,需要 O ( N ) O(N) O(N)的栈空间。
def mergeTrees(self, t1, t2):
"""
:type t1: TreeNode
:type t2: TreeNode
:rtype: TreeNode
"""
if not t1:
return t2
if not t2:
return t1
t1.val += t2.val
t1.left = self.mergeTrees(t1.left, t2.left)
t1.right = self.mergeTrees(t1.right, t2.right)
return t1
1361. 验证二叉树
二叉树上有 n 个节点,按从 0 到 n - 1 编号,其中节点 i 的两个子节点分别是 leftChild[i] 和 rightChild[i]。
只有 所有 节点能够形成且 只 形成 一颗 有效的二叉树时,返回 true;否则返回 false。
如果节点 i 没有左子节点,那么 leftChild[i] 就等于 -1。右子节点也符合该规则。
注意:节点没有值,本问题中仅仅使用节点编号。
示例 1:
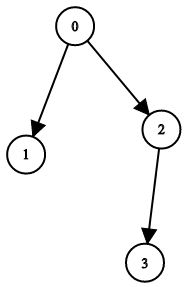
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,-1,-1,-1]
输出:true
示例 2:
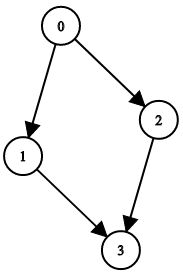
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,3,-1,-1]
输出:false
示例 3:

输入:n = 2, leftChild = [1,0], rightChild = [-1,-1]
输出:false
示例 4:
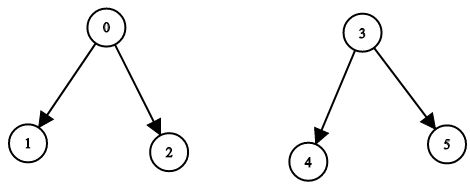
输入:n = 6, leftChild = [1,-1,-1,4,-1,-1], rightChild = [2,-1,-1,5,-1,-1]
输出:false
思路:
我们将验证二叉树的过程分为两步:第一步找到二叉树的根节点,第二步从根节点开始对二叉树进行遍历,判断其是否为一颗有效的二叉树。
第一步:由示例3.4可知,根节点有且只能有一个,并且只能单向。所以用图的思想来看的话,入度为0的节点就是根节点。那么我们就可以遍历leftchild和rightchild,统计每个节点的入度到in_degree数组中。如果入度为0的节点个数不为1,说明根节点要么没有,要么不止一个,不符合。
第二步:找到根节点之后,用层次遍历的方法去遍历每个联通的节点,记录遍历到节点的个数count。如果count > n,说明有节点被遍历了不止一次,对应错误示例2(也可以直接在第一步中查看入度是否全为1来判断)。如果是有效的二叉树,那么count=k,即所有节点恰好都被遍历过一次。
def validateBinaryTreeNodes(self, n, leftChild, rightChild):
"""
:type n: int
:type leftChild: List[int]
:type rightChild: List[int]
:rtype: bool
"""
in_degree = [0] * n
# 计算所有节点的入度
for u in leftChild:
if u != -1:
in_degree[u] += 1
for v in rightChild:
if v != -1:
in_degree[v] += 1
# 当入度为0的节点个数不为1,说明根节点不是只有一个,有可能没有有可能有多个
if in_degree.count(0) != 1:
return False
else:
q = [in_degree.index(0)] # 取入度为0的作为根节点
count = 0 # 统计树中所有节点被访问的次数,有效的二叉树每个节点只能被访问一次即,count==n
# 层序遍历
while q:
node = q.pop(0)
count += 1 # 访问的节点个数+1
if count > n:
return False
if leftChild[node] != -1:
q.append(leftChild[node])
if rightChild[node] != -1:
q.append(rightChild[node])
return count == n
958. 二叉树的完全性检验
给定一个二叉树,确定它是否是一个完全二叉树。
百度百科中对完全二叉树的定义如下:
若设二叉树的深度为 h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。(注:第 h 层可能包含 1~ 2h 个节点。)
示例 1:
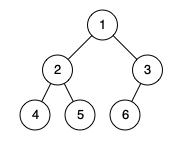
输入:[1,2,3,4,5,6]
输出:true
解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
示例 2:
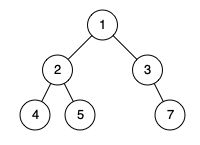
输入:[1,2,3,4,5,null,7]
输出:false
解释:值为 7 的结点没有尽可能靠向左侧。
思路:
对于完全二叉树或满二叉树,在「节点的编号pos」、「层数level」上有很多数学性质,同时层序遍历也是最常用于这类问题的遍历方式——因为涉及到每层的性质。
这个问题我们可以使用层序遍历,对每一层的节点进行判断,注意这边我们空节点也会压入队列。观察到完全二叉树该层的None节点只会出现在最后,而不会出现在开头或是中间,所以我们使用flag记录None节点是否出现,如果在遍历到之后的非空节点,这个flag已经被标记过,说明该层节点没有左对齐。
def isCompleteTree(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
if not root:
return True
q = [root]
flag = False # 记录当前这层是否出现了none
while q:
count = len(q)
for i in range(count):
node = q.pop(0)
if node: # 非空节点,先判断之前是否出现none,再把左右孩子压入
if flag: # 在该节点之前出现了none
return False
q.append(node.left)
q.append(node.right)
else: # 遇到空节点,记录
flag = True
return True
965. 单值二叉树
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
只有给定的树是单值二叉树时,才返回 true;否则返回 false。
示例 1:
输入:[1,1,1,1,1,null,1]
输出:true
示例 2:
输入:[2,2,2,5,2]
输出:false
思路:
遍历所有节点,查看节点值是否相等即可。
我们这里不使用额外空间保存所有节点的节点值,我们比较「前驱节点」和「当前节点」的值,查看是否相等。如果不相等就修改全局变量res为false
def isUnivalTree(self, root):
"""
:type root: TreeNode
:rtype: bool
"""
self.pre = float('-inf') # 前驱节点值初始化为负无穷
self.res = True
def inOrder(root):
if not root:
return
# 结果是false,直接return
if not self.res:
return
inOrder(root.left)
# 判断是否为初始状态
if self.pre == float('-inf'):
self.res = True
elif self.pre != root.val:
self.res = False
self.pre = root.val
inOrder(root.right)
inOrder(root)
return self.res
993. 二叉树的堂兄弟节点
在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处。
如果二叉树的两个节点深度相同,但父节点不同,则它们是一对堂兄弟节点。
我们给出了具有唯一值的二叉树的根节点 root,以及树中两个不同节点的值 x 和 y。
只有与值 x 和 y 对应的节点是堂兄弟节点时,才返回 true。否则,返回 false。
示例 1:
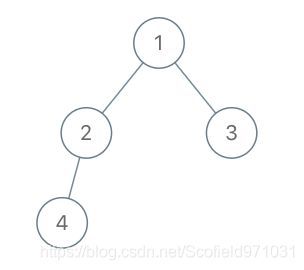
输入:root = [1,2,3,4], x = 4, y = 3
输出:false
示例 2:
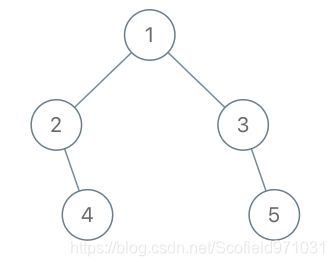
输入:root = [1,2,3,null,4,null,5], x = 5, y = 4
输出:true
示例 3:

输入:root = [1,2,3,null,4], x = 2, y = 3
输出:false
思路:
方法一 遍历所有节点记录父亲节点和深度
所谓堂兄弟节点是在同一层,但是父亲节点不同的节点。所以最粗暴的方法就是遍历所有节点,然后记录每个节点的父亲节点par和深度level,分别保存到parent字典和depth字典中,由于每个节点值唯一,所以字典的key就是节点值。
这里的遍历用先序遍历,遍历函数dfs传递三个参数:当前节点root、该节点的父亲节点 par 以及该节点的深度level
def isCousins2(self, root, x, y):
"""
用parent和depth保存每个节点的父节点和深度
遍历函数dfs,传递参数当前节点, 父节点和深度
"""
parent = {
}
depth = {
}
def dfs(root, par, level):
if not root:
return
# 保存该节点的深度和父亲节点
parent[root.val] = par
depth[root.val] = level
dfs(root.left, root, level+1)
dfs(root.right, root, level+1)
dfs(root, None, 0)
return depth[x] == depth[y] and parent[x] != parent[y]
方法二 层序遍历每取节点就判断其左右孩子
因为堂兄弟节点是在同一层的,所以层序遍历时,我们把队列中节点取出时,直接判断该节点的左右孩子是否是查询节点,如果是的话直接return false。同时还要记录当前这层是否有查询节点,用counter去记录值等于x或y的节点的个数,判断个数是否等于2。等于2的话说明这两个节点在同一层,并且父节点不同。
def isCousins(self, root, x, y):
"""
:type root: TreeNode
:type x: int
:type y: int
:rtype: bool
"""
if not root:
return False
if not root.left and not root.right:
return False
q = [root]
while q:
count = len(q) # 代表当前层的节点个数
counter = 0 # 记录该层,出现=x或=y的节点个数
for i in range(count):
node = q.pop(0)
# 在这一层中,该节点的左右孩子节点刚好满足,那么直接返回false
if node.left and node.right and \
((node.left.val == x and node.right.val == y) or \
(node.left.val == y and node.right.val == x)):
return False
# 统计这一层中,等于x/y的节点个数
if node.val == x or node.val == y:
counter += 1
if counter == 2:
return True
if node.left:
q.append(node.left)
if node.right:
q.append(node.right)
543. 二叉树的直径
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
示例 :
给定二叉树
1
/ \
2 3
/ \
4 5
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
注意:两结点之间的路径长度是以它们之间边的数目表示。
思路:
对于给定的示例,我们可以知道:当root是路径的转折点时,最长路径就是root的「左子树的高度路径」和「右子树的高度路径」的拼接,那么最长路径直径就是maxDepth(root.left) + maxDepth(root.right)。但是这边要注意,不是说对于给定的示例,直接返回这个值就行了,而是需要对树中的每个节点都计算一遍左右子树高度和,最后取最大的。因为最长路径完全有可能出现在左子树中(满二叉树的例子)。
所以算法中我们需要定义全局变量ans,在maxDepth函数中求出左右子树高度之后去更新ans
def diameterOfBinaryTree(self, root):
"""
自底向上,后续遍历
:type root: TreeNode
:rtype: int
"""
self.ans = -1
def maxDepth(root):
if not root:
return 0
# 求出左右子树的高度
leftd = maxDepth(root.left)
rightd = maxDepth(root.rightd)
# 更新最大直径为左右子树高度和
self.ans = max(self.ans, leftd + rightd)
return max(leftd + rightd) + 1
maxDepth(root)
return self.ans
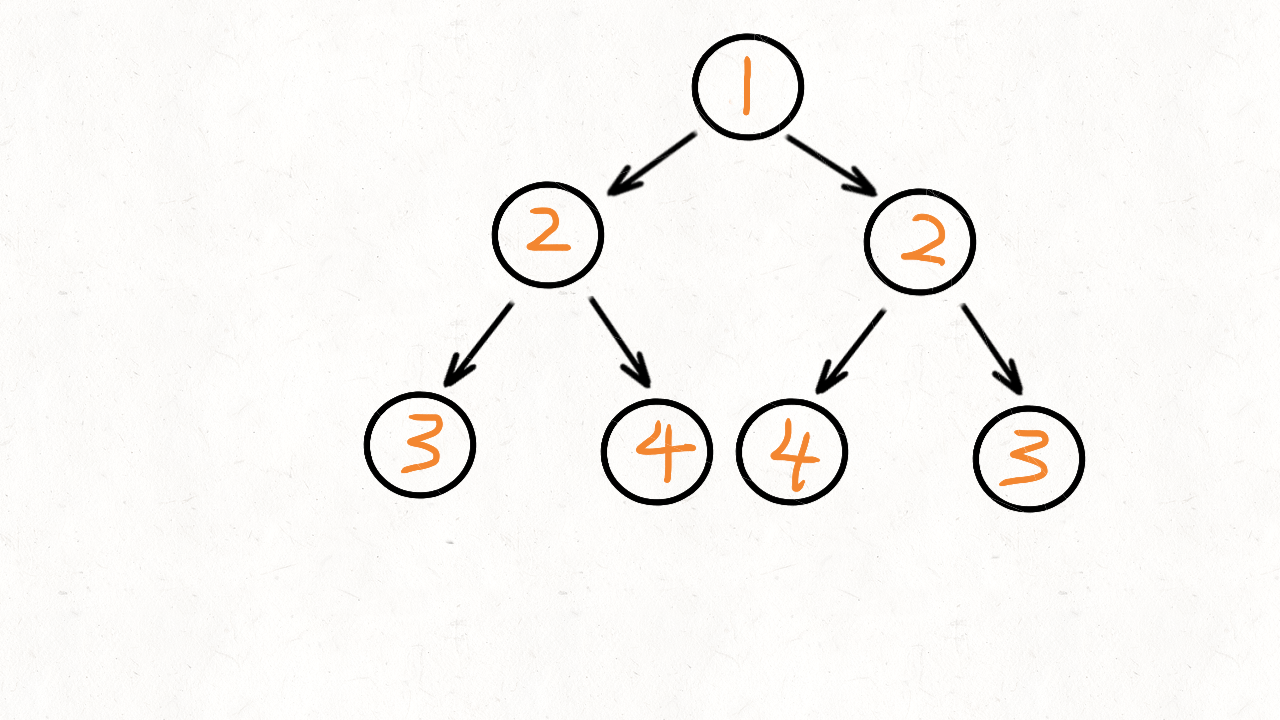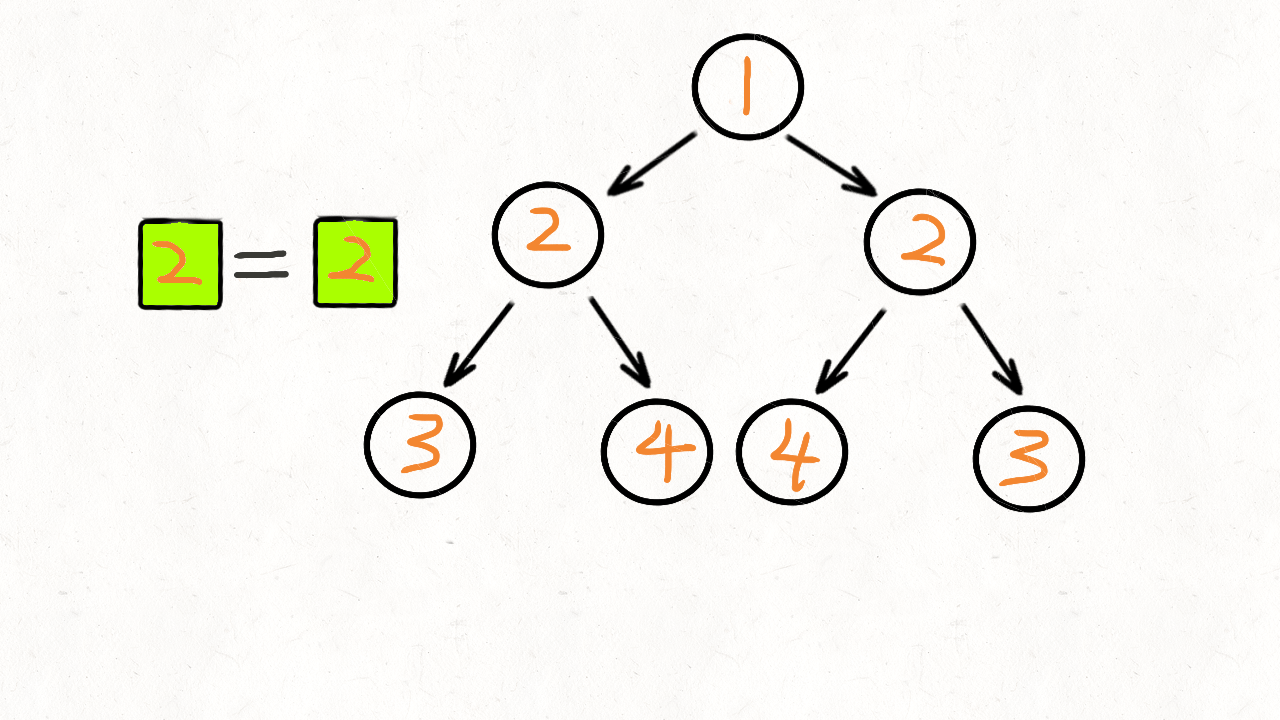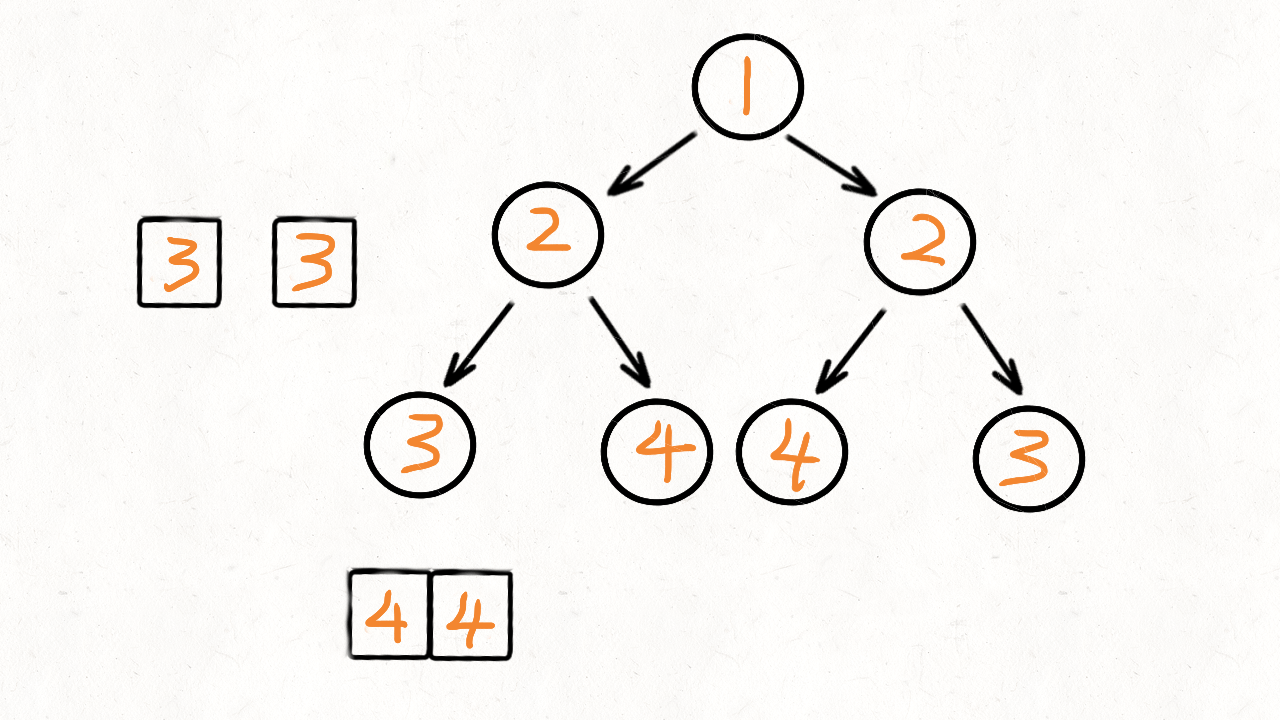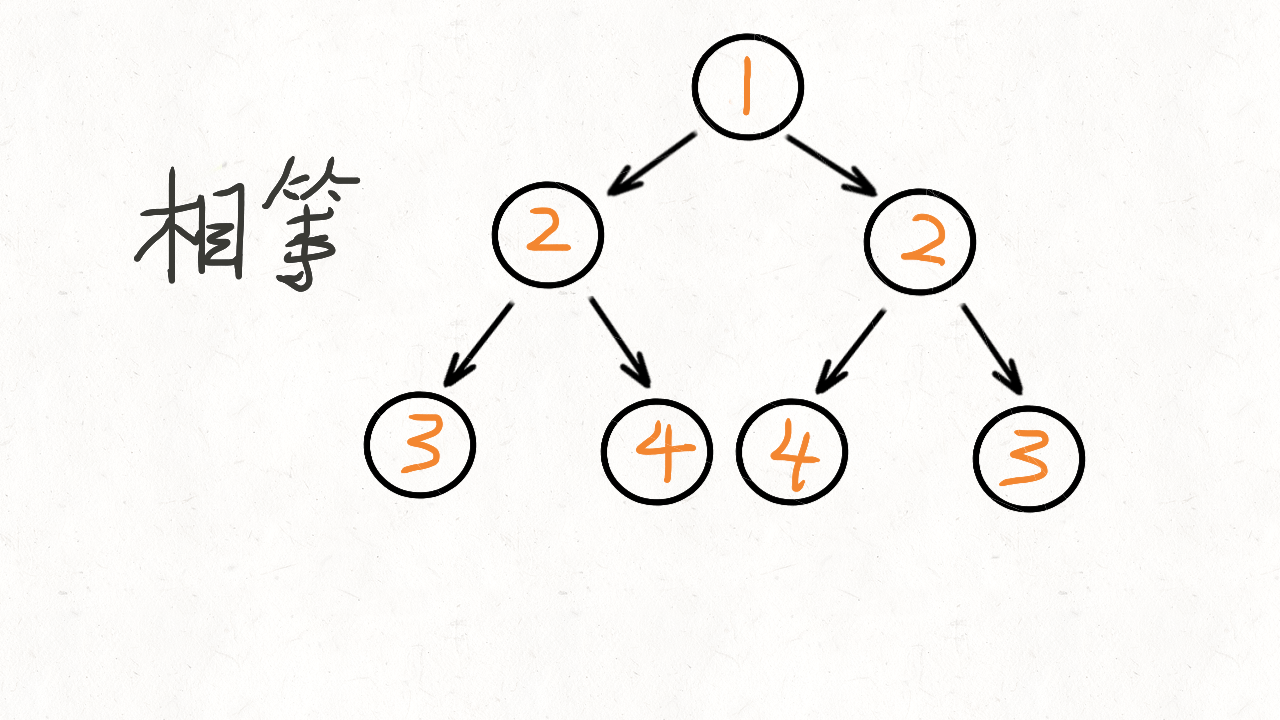
101. 对称二叉树
给定一个二叉树,检查它是否是镜像对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
思路:
方法一 递归
对于给定示例,判断是否为对称,就是需要判断根节点的左右子树是否对称。
那么判断左右子树是否对称,进一步划分成子问题:左子树的右子树和右子树的左子树是否对称,以及右子树的左子树和左子树的右子树是否对称。
所以构建递归函数helper(t1, t2)判断t1和t2是否对称:
- 如果
t1,t2都为空,对称 - 如果
t1,t2一个为空,一个不为空,不对称 - 判断
t1.val==t2.val,递归判断t1的左子树和t2的右子树,以及t1的右子树和t2的左子树是否对称。返回「相与」结果
def isSymmetric(self, root):
"""
1. 递归的判断,即判断左子树和右子树是否对称
"""
if not root:
return True
def helper(t1, t2):
"""
判断t1和t2是否镜像对称
"""
# 1. 都为空
if not t1 and not t2:
return True
# 2.有一个为空,另一个不为空
if not t1 or not t2:
return False
# 3. 根节点值是否相等,递归判断左子树和右子树,右子树和左子树是否对称
return t1.val == t2.val and helper(t1.left, t2.right) and helper(t1.right, t2.left)
return helper(root.left, root.right)
方法二 队列
递归方法中,判断两棵树是否对称,首先看根节点值是否相等;其次判断左子树和右子树,以及右子树和左子树是否对称。
使用队列的话,思路是每次从队列中取出两个节点,分别为left和right,首先判断值是否相等;其次将left的左子树和right的右子树压入队列,再将left的右子树和right的左子树压入队列。初始队列是[root.left, root.right]
def isSymmetric2(self, root):
"""
队列判断,每次从队列中取两个进行比较。
然后把第一个元素的左子树和第二个元素的右子树压入
然后把第一个元素的右子树和第二个元素的左子树压入
"""
if not root:
return True
if not root.left and not root.right:
return True
q = [root.left, root.right]
while q:
left = q.pop(0)
right = q.pop(0)
# 判断left right两个节点是否对称
if not left and not right:
continue
if not left or not right:
return False
if left.val != root.val:
return False
# 更新队列
q.append(left.left)
q.append(right.right)
q.append(left.right)
q.append(right.left)
return True
951. 翻转等价二叉树
我们可以为二叉树 T 定义一个翻转操作,如下所示:选择任意节点,然后交换它的左子树和右子树。
只要经过一定次数的翻转操作后,能使 X 等于 Y,我们就称二叉树 X 翻转等价于二叉树 Y。
编写一个判断两个二叉树是否是翻转等价的函数。这些树由根节点 root1 和 root2 给出。
示例: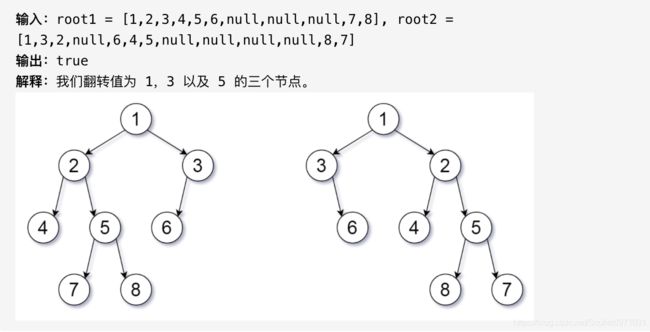
思路:
自顶向下先序遍历思路。
- 如果 r o o t 1 root1 root1, r o o t 2 root2 root2都为空,返回true
- 如果 r o o t 1 root1 root1, r o o t 2 root2 root2有一个不为空,返回false
- 如果 r o o t 1. v a l ! = r o o t 2. v a l root1.val != root2.val root1.val!=root2.val,直接返回false
- 如果 r o o t 1 root1 root1的左右子树没有翻转得到 r o o t 2 root2 root2,那么就递归比较 r o o t 1. l e f t root1.left root1.left、 r o o t 2. l e f t root2.left root2.left和 r o o t 1. r i g h t root1.right root1.right、 r o o t 2. r i g h t root2.right root2.right,两者取「与」
- 如果 r o o t 1 root1 root1的左右子树翻转之后得到 r o o t 2 root2 root2,那么就递归比较 r o o t 1. l e f t root1.left root1.left、 r o o t 2. r i g h t root2.right root2.right和 r o o t 1. r i g h t root1.right root1.right、 r o o t 2. l e f t root2.left root2.left,两者取「与」
def flipEquiv(self, root1, root2):
"""
:type root1: TreeNode
:type root2: TreeNode
:rtype: bool
"""
if not root1 and not root2:
return True
if not root1 or not root2:
return False
if root1.val != root2.val:
return False
return self.flipEquiv(root1.left, root2.left) and self.flipEquiv(root1.right, root2.right) or \
self.flipEquiv(root1.left, root2.right) and self.flipEquiv(root1.right, root2.left)
662. 二叉树最大宽度
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
示例 1:
输入:
1
/ \
3 2
/ \ \
5 3 9
输出: 4
解释: 最大值出现在树的第 3 层,宽度为 4 (5,3,null,9)。
示例 2:
输入:
1
/
3
/ \
5 3
输出: 2
解释: 最大值出现在树的第 3 层,宽度为 2 (5,3)。
示例 3:
输入:
1
/ \
3 2
/
5
输出: 2
解释: 最大值出现在树的第 2 层,宽度为 2 (3,2)。
示例 4:
输入:
1
/ \
3 2
/ \
5 9
/ \
6 7
输出: 8
解释: 最大值出现在树的第 4 层,宽度为 8 (6,null,null,null,null,null,null,7)。
思路:
注意宽度的定义是当前层的最左节点和最右节点的距离,包括中间的空节点。所以我们很自然的想到给每个节点赋予一个「pos」属性,代表当前节点在该层的编号。如果我们走向左子树,那么 position -> position * 2,如果我们走向右子树,那么position -> positon * 2 + 1。
用层序遍历,队列中的每个节点是(node, pos),每一层的第一个节点的pos和最后一个节点的pos的差就是当前层的宽度。
def widthOfBinaryTree(self, root):
"""
:type root: TreeNode
:rtype: int
"""
if not root:
return 0
q = [(root, 0)] # (node, pos)
ans = -1
while q:
pos_arr = [] # 记录当前层所有节点的位置
for i in range(len(q)):
node, pos = q.pop(0)
pos_arr.append(pos)
if node.left:
q.append((node.left, pos * 2))
if node.right:
q.append((node.right, pos * 2 + 1))
# 当前层的最后一个节点的位置 - 第一个节点的位置
ans = max(ans, pos_arr[-1] - pos_arr[0] + 1)
return ans
1104. 二叉树寻路
在一棵无限的二叉树上,每个节点都有两个子节点,树中的节点 逐行 依次按 “之” 字形进行标记。
如下图所示,在奇数行(即,第一行、第三行、第五行……)中,按从左到右的顺序进行标记;
而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
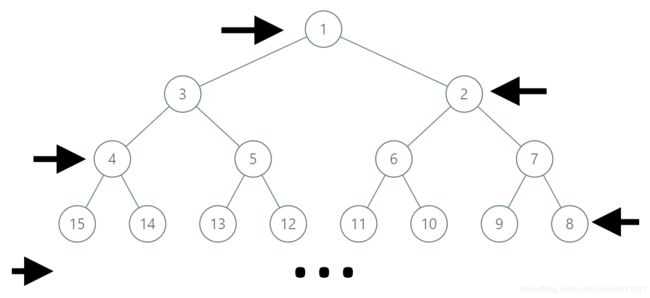
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label节点的路径,该路径是由途经的节点标号所组成的。
示例 1:
输入:label = 14
输出:[1,3,4,14]
示例 2:
输入:label = 26
输出:[1,2,6,10,26]
思路:
这道题实际上考察的是满二叉树的数学性质。
如果是按照正常顺序构造二叉树,理应是
1
2 3
4 5 6 7
8 9 10 11 12 13 14 15
....
因为题目给出的是个完全二叉树,下一层的节点是当前层的2倍。
假设 l a b e l = 14 label = 14 label=14,顺序构造的上一层 l a b e l / 2 = 7 label / 2 = 7 label/2=7
但是按照原图来看理应是 4 4 4才符合结果 。
假设 l a b e l = 11 label = 11 label=11,顺序构造的上一层 l a b e l / 2 = 5 label / 2 = 5 label/2=5
但是按照原图来看理应是 6 6 6才符合结果。
此时可以看到按照之行排列的计算结果是顺序排列的「对称点」
示例:label = 14:
4 + 7 = 14 / 2 + X 4+7=14/2+X 4+7=14/2+X
4 + 7 4+7 4+7是第三层的左右之和,此时 l a b e l / 2 = 7 label/2 = 7 label/2=7,另一个位置的值是 4 4 4的时候是其对称点。 X X X指推理到上一层的 l a b e l label label
那么现在只要知道了当前在哪一层,就能根据完全二叉树的性质求出上一层左右之和,进而推出上一层的 l a b e l label label。其中 l e f t , r i g h t left,right left,right分别指上一层的最左和最右节点编号。
l e f t + r i g h t = l a b e l / 2 + X left+right=label/2 + X left+right=label/2+X
对于完全二叉树,第 N N N层的节点数量为 2 N − 1 2^{N-1} 2N−1,最左边节点是 2 N − 1 2^{N-1} 2N−1,最右边节点是 2 N − 1 2^N-1 2N−1。由 l a b e l label label,可以通过 N = l o g 2 ( l a b e l ) N=log_2(label) N=log2(label) 求出当前节点层数的上一层。求出 N N N之后,那么就可以得到 l e f t , r i g h t left,right left,right。
根据这个公式,由 l a b e l label label一直推出 X X X,即上层的 l a b e l label label,直到为1为止。
def pathInZigZagTree(self, label):
"""
:type label: int
:rtype: List[int]
"""
import math
res = []
while label != 1:
res.insert(0, label)
N = int(math.log2(label)) # N代表当前节点的层数-1
X = math.pow(2, N-1) + math.pow(2, N) - 1 - label // 2
label = int(X)
res.insert(0, 1)
return res
面试题 04.10. 检查子树
检查子树。你有两棵非常大的二叉树:T1,有几万个节点;T2,有几万个节点。设计一个算法,判断 T2 是否为 T1 的子树。
如果 T1 有这么一个节点 n,其子树与 T2 一模一样,则 T2 为 T1 的子树,也就是说,从节点 n 处把树砍断,得到的树与 T2 完全相同。
示例1:
输入:t1 = [1, 2, 3], t2 = [2]
输出:true
示例2:
输入:t1 = [1, null, 2, 4], t2 = [3, 2]
输出:false
思路:
对于给定示例t1,t2,判断t2是否为t1的子树。基本思路是遍历树的每个节点,判断以该节点作为根节点的树是否与t2相同。那么分解子问题为:
- 判断
t2是否和以t1为根节点的树相同。 - 递归判断
t2是否是以t1的左孩子为根节点的树的子树。 - 递归判断
t3是否是以t1的右孩子为根节点的树的子树。
def checkSubTree(self, t1, t2):
"""
:type t1: TreeNode
:type t2: TreeNode
:rtype: bool
"""
def isSame(t1, t2):
"""
判断两棵树是否相同
"""
if not t1 and not t2:
return True
if not t1 or not t2:
return False
return t1.val == t2.val and isSame(t1.left, t2.left) and isSame(t1.right, t2.right)
if not t1:
return not t2
# 遍历t1的每个节点,判断以该节点为根节点的树和t2是否相同
return isSame(t1, t2) or self.checkSubTree(t1.left, t2) or self.checkSubTree(t1.right, t2)
剑指 Offer 26. 树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例 1:
输入:A = [1,2,3], B = [3,1]
输出:false
示例 2:
输入:A = [3,4,5,1,2], B = [4,1]
输出:true
思路:
这道题是判断 B B B是否包含在 A A A中,那么如果 B B B包含在 A A A中,那么子结构的根节点可能是 A A A中任意一个节点。因此,判断树 B B B是否是树 A A A的子结构,需完成以下两步:
- 先序遍历树 A A A 中的每个节点 n A n_A nA(对应函数
isSubStructure(A, B)) - 判断树 A A A 中 以 n A n_A nA为根节点的子树 是否包含树 B B B 。(对应函数
contains(A, B))
contains(A, B)函数: 判断树 A A A 中是否包含树 B B B,其中根节点要对齐,也就是说要从根节点开始匹配。
1. 终止条件:
- 当节点 B B B为空,说明树 B B B已经匹配完成,返回
true - 当节点 A A A为空,说明树 A A A已经空了,但是 B B B还没匹配完毕,返回
false - 当节点 A A A和 B B B的值不同,匹配失败,返回
false
2. 返回值
- 判断 A A A 和 B B B 的左子节点是否相等,即
contains(A.left, B.left); - 判断 A A A 和 B B B 的右子节点是否相等,即
contains(A.right, B.right);
isSubStructure(A, B)函数:
-
特例处理: 当 树 A A A 为空 或 树 B B B 为空 时,直接返回
false; -
返回值: 若树 B B B 是树 A A A 的子结构,则必满足以下三种情况之一,因此用或
or连接;- 以 节点 A A A 为根节点的子树 包含树 B B B ,对应
contains(A, B); - 树 B B B 是 树 A A A 左子树 的子结构,对应
isSubStructure(A.left, B); - 树 B B B 是 树 A A A 右子树 的子结构,对应
isSubStructure(A.right, B);
- 以 节点 A A A 为根节点的子树 包含树 B B B ,对应
以上 2. 3. 实质上是在对树 A A A 做 先序遍历 。
时间复杂度 O ( M N ) O(MN) O(MN): 其中 M , N M,N M,N分别为树 A A A和 树 B B B的节点数量;先序遍历树 A A A 占用 O ( M ) O(M) O(M) ,每次调用 contains(A, B)判断占用 O ( N ) O(N) O(N) 。
空间复杂度 O ( M ) O(M) O(M) : 当树 A A A 和树 B B B 都退化为链表时,递归调用深度最大。当 M ≤ N M \leq N M≤N 时,遍历树 A A A 与递归判断的总递归深度为 M M M ;当 M > N M>N M>N 时,最差情况为遍历至树 A A A 叶子节点,此时总递归深度为 M M M。
def isSubStructure(self, A, B):
"""
:type A: TreeNode
:type B: TreeNode
:rtype: bool
"""
def contains(t1, t2):
"""
判断t2是否是t1的子树
"""
# 1.当t2为空,说明t2中节点已经全部匹配完毕
if not t2:
return True
# 2. 当t1为空,说明t2中节点还没匹配完毕而t1已经空了
if not t1:
return False
return t1.val == t2.val and contains(t1.left, t2.left) and contains(t1.right, t2.right)
# 有一个树为空,直接返回
if not A or not B:
return False
return contains(A, B) or self.isSubStructure(A.left, B) or self.isSubStructure(A.right, B)
1367. 二叉树中的列表
给你一棵以 root 为根的二叉树和一个 head 为第一个节点的链表。
如果在二叉树中,存在一条一直向下的路径,且每个点的数值恰好一一对应以 head 为首的链表中每个节点的值,那么请你返回 True ,否则返回 False 。
一直向下的路径的意思是:从树中某个节点开始,一直连续向下的路径。
示例 1:
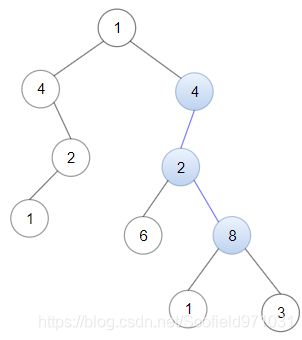
输入:head = [4,2,8], root = [1,4,4,null,2,2,null,1,null,6,8,null,null,null,null,1,3]
输出:true
解释:树中蓝色的节点构成了与链表对应的子路径。
思路:
基本思路同上题,只不过基本子问题变成:判断以root为根节点的树是否存在一条以根节点开始,与链表head匹配的路径。
def isSubPath(self, head, root):
"""
:type head: ListNode
:type root: TreeNode
:rtype: bool
"""
def dfs(node, head):
"""
从node开始匹配head链表,返回匹配是否成功
"""
# 1. 链表为空,说明匹配完毕
if not head:
return True
# 2. 根节点为空,链表不为空,匹配失败
if not node:
return False
# 3. 根节点值和链表头结点值不等
if node.val != head.val:
return False
return dfs(node.left, head.next) or dfs(node.right, head.next)
if not root:
return False
return dfs(root, head) or self.isSubPath(head, root.left) or self.isSubPath(head, root.right)
时间复杂度:最坏情况下需要对所有节点进行匹配。假设一共有 n n n 个节点,对于一个节点为根的子树,如果它是满二叉树,且每次匹配均为到链表的最后一个节点的时候匹配失败,那么一共被匹配到的节点数为 2 l e n + 1 2^{len+1} 2len+1,即这个节点为根的子树往下 l e n len len层的满二叉树的节点数,其中 l e n len len为链表的长度,而二叉树总节点数最多 n n n 个,所以枚举节点最多匹配 m i n ( 2 l e n + 1 , n ) min(2^{len+1},n) min(2len+1,n)次,最坏情况下需要 O ( n ∗ m i n ( 2 l e n + 1 , n ) ) O(n* min(2^{len+1},n)) O(n∗min(2len+1,n))的时间复杂度。
空间复杂度:由于递归函数在递归过程中需要为每一层递归函数分配栈空间,所以这里需要额外的空间且该空间取决于递归的深度。考虑枚举一个节点为起点递归判断所需的空间,假设该节点在第 x x x 层,即递归枚举时已经用了 O ( x ) O(x) O(x)的空间,这个节点再往下匹配链表长度 y y y 层节点时需要使用 O ( y ) O(y) O(y)的空间,所以一共需要 O ( x + y ) O(x+y) O(x+y)的空间,而 x + y x+y x+y 必然不会超过树的高度,所以最后的空间复杂度为树的高度,即 O ( h e i g h t ) O(height) O(height) , h e i g h t height height 为树的高度。
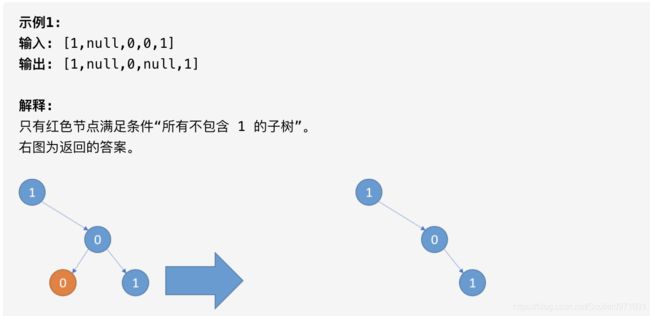
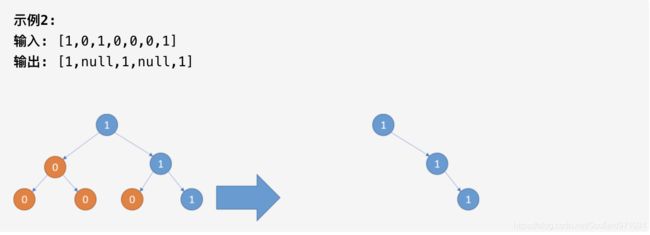
814. 二叉树剪枝
给定二叉树根结点 root ,此外树的每个结点的值要么是 0,要么是 1。
返回移除了所有不包含 1 的子树的原二叉树。
( 节点 X 的子树为 X 本身,以及所有 X 的后代。)
思路:
很显然,需要遍历树中所有节点,查看以当前节点为根节点的子树是否为「全0子树」,如果是的话需要返回None给它的父亲节点,也就是说同时修剪。所以用自底向上的后序遍历方法:
- 判断当前节点
root的左子树是否为「全0子树」,如果是的话,将左子树更新为None - 判断当前节点
root的右子树是否为「全0子树」,如果是的话,将右子树更新为None - 如果当前节点
root.val=1,返回false - 如果左子树和右子树有一个为「全0子树」,就返回
false
def pruneTree(self, root):
"""
:type root: TreeNode
:rtype: TreeNode
"""
if not root:
return None
def containsOne(root):
"""
判断root为根节点的树是否包含1,同时去除全0子树
"""
if not root:
return False
# 先判断左右子树是否包含1
a1 = containsOne(root.left)
a2 = containsOne(root.right)
# 不包含1的话,直接返回给父亲节点None
if not a1:
root.left = None
if not a2:
root.right = None
return root.val == 1 or (a1 or a2)
containsOne(root)
return root
226. 翻转二叉树
翻转一棵二叉树。
示例:
输入:
4
/ \
2 7
/ \ / \
1 3 6 9
输出:
4
/ \
7 2
/ \ / \
9 6 3 1
思路:
方法一 递归
对于给定示例,修改root的右子树为翻转后的左子树,左子树为翻转后的右子树。
但要注意不能这么写,因这么写的话,下面一行的root.left是已经修改后的,不能做到交换。
root.left = self.invertTree(root.right)
root.right = self.invertTree(root.left)
正确的写法是需要保存下来翻转后的左右子树,然后再修改根节点的指向
def invertTree(self, root):
"""
:type root: TreeNode
:rtype: TreeNode
"""
if not root:
return None
# 需要保存下来翻转后的左右子树
invert_right = self.invertTree(root.right)
invert_left = self.invertTree(root.left)
# 更新根节点的指向
root.left = invert_right
root.right = invert_left
return root
方法二 队列
其实如果要做到镜像翻转,只要能够遍历到每个节点,然后将节点的左右孩子互换即可。所以我们可以借助层序遍历的队列实现方法,每次从队列中取出一个节点,然后交换这个节点的左右孩子即可。交换的话使用tmp_node进行置换即可。
def invertTree2(self, root):
"""
队列,层序遍历思路
每次取出一个节点,交换它的左右节点之后,再压入队列
"""
if not root:
return None
q = [root]
while q:
node = q.pop(0)
# 交换左右孩子节点
tmp_node = node.left
node.left = node.right
node.right = tmp_node
if node.left:
q.append(node.left)
if node.right:
q.append(node.right)
return root
654. 最大二叉树
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
二叉树的根是数组中的最大元素。
左子树是通过数组中最大值左边部分构造出的最大二叉树。
右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :
输入:[3,2,1,6,0,5]
输出:返回下面这棵树的根节点:
6
/ \
3 5
\ /
2 0
\
1
思路:
递归构建树,首先从数组中找到最大值以及最大值的下标,然后递归构建树即可
def constructMaximumBinaryTree(self, nums):
"""
:type nums: List[int]
:rtype: TreeNode
"""
if len(nums) < 1:
return None
if len(nums) == 1:
return TreeNode(nums[0])
root_val = max(nums)
root_idx = nums.index(root_val)
root = TreeNode(root_val)
root.left = self.constructMaximumBinaryTree(nums[:root_idx])
root.right = self.constructMaximumBinaryTree(nums[root_idx+1:])
return root
剑指 Offer 07. 重建二叉树
输入某二叉树的前序遍历和中序遍历的结果,请重建该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
例如,给出
前序遍历 preorder = [3,9,20,15,7]
中序遍历 inorder = [9,3,15,20,7]
返回如下的二叉树:
3
/ \
9 20
/ \
15 7
思路:
根据前序序列得到根节点的值,再到中序序列中找到根节点的位置,得到左右子树的长度,然后递归求解左右子树
def buildTree(self, preorder, inorder):
"""
:type preorder: List[int]
:type inorder: List[int]
:rtype: TreeNode
"""
if len(preorder) == 0:
return None
root_val = preorder[0]
root_idx = inorder.index(root_val)
root = TreeNode(root_val)
left_len = root_idx
right_len = len(inorder) - root_idx
root.left = self.buildTree(preorder[1:1+left_len], inorder[:root_idx])
root.right = self.buildTree(preorder[1+left_len:], inorder[root_idx+1:])
return root
968. 监控二叉树
给定一个二叉树,我们在树的节点上安装摄像头。
节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
计算监控树的所有节点所需的最小摄像头数量。
示例 1:
输入:[0,0,null,0,0]
输出:1
解释:如图所示,一台摄像头足以监控所有节点。
示例 2:
输入:[0,0,null,0,null,0,null,null,0]
输出:2
解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置之一。
思路:
方法一 动态规划
首先明确,每个节点会有如下三种状态:
- 状态0 :未被覆盖或待覆盖
- 状态1:已被覆盖,但无监控
- 状态2:该处有监控
思路就是自底向上,用后序遍历思路首先得出左右孩子节点的状态,然后根据左右孩子的状态决定根节点的状态,具体来说:
- 如果左右孩子有一个未被覆盖,那么该节点就需要放置监控,返回状态2
- 如果左右孩子都已被覆盖,但无监控,那么该节点是处于未被覆盖的状态,返回状态0
- 如果左右孩子有一处放置监控,那么该节点是已被覆盖的状态,返回状态1
注意最后当根节点的状态是0的时候,答案还要加1
def minCameraCover(self, root):
"""
每个节点有如下三个状态
状态0:未被覆盖
状态1:被覆盖,且该节点处无监控
状态2:该节点处有监控
"""
self.ans = 0
def dfs(root):
"""
后续遍历,用left right的状态来确定root的状态
"""
# 1. 空节点,直接置为状态1,认为已经被覆盖
if not root:
return 1
# 后续遍历,得到左右孩子节点的状态
left = dfs(root.left)
right = dfs(root.right)
# (left, right)一共有3^2=9种状态组合,其实可以穷举
# 2. 左右孩子节点有一个未被覆盖,则该节点需要放监控
if left == 0 or right == 0:
self.ans += 1
return 2
# 3. 左右孩子节点都被覆盖,但无监控,那么该节点是未被覆盖的状态
if left == 1 and right == 1:
return 0
# 4. 左右孩子节点有一个放了监控,那么该节点已被覆盖
if left + right >= 3:
return 1
# 如果根节点状态是未被覆盖,那么根节点需要放置监控
if dfs(root) == 0:
self.ans += 1
return self.ans
方法二 贪心算法
于其试图从上到下覆盖每个节点,不如尝试从上到下覆盖它——考虑新放置一个具有最深节点的相机,a年后沿着树向上移动。
如果节点的子节点被覆盖,且该节点具有父节点,则最好的情况是将摄像机放置在父节点上。
算法:
如果一个节点有孩子节点且没有被摄像机覆盖,则我们需要放置一个摄像机在该节点。此外,如果一个节点没有父节点且没有被覆盖,则必须放置一个摄像机在该节点。
def minCameraCover2(self, root):
"""
贪心,从下往上去覆盖放监控——后续遍历
如果该节点的孩子节点都未被覆盖,那么需要在该处放监控
"""
covered = {
None} # 初始放入空节点None
self.ans = 0
def dfs(root, par=None):
"""
后续遍历,传入参数父亲节点
"""
if not root:
return
dfs(root.left, root)
dfs(root.right, root)
# 处理根节点
if not par and root not in covered:
self.ans += 1
covered.update({
par, root, root.left, root.right})
# 两个孩子有一个没被覆盖,那么就需要在该节点处放置监控
elif root.left not in covered or root.right not in covered:
self.ans += 1
covered.update({
par, root, root.left, root.right})
dfs(root, None)
return self.ans