学Redis都需要知道的底层数据结构
前言
Redis肯定大家都已经耳熟能详了,主要用作缓存中间件,这篇博客主要介绍一下其底层的实现机制。在学习了数组和链表之后,线性表这边就只剩下一个跳跃表(SkipList)还没登场了。跳跃表正是大名鼎鼎的Redis底层实现的基础,因此学好跳跃表必能对Redis有着更加深入的理解。本篇博客先不讲代码实现,而是着重介绍跳跃表的思想和性能分析。
常规线性表结构的缺陷
我们之前学习过了数组和链表,这里我们来回顾一下,分析分析它们的性能。首先实际应用的场景是这样的:我们需要往表当中插入或者删除一个数据项。无论对于数组还是链表来说,都需要两步:1.找到指定位置,我们称为查询;2.插入或删除元素。
对于数组来讲,如果我们指定了插入的位置,那么至少说数组查询的时间复杂度为O(1),但插入和删除都会导致后面元素的移动,时间复杂度为O(n)。对于链表来讲,虽然能够保证插入和删除时时间复杂度只有O(1),但是在这之前的查询操作也是O(n)。
综合来看,无论是数组还是链表,其时间复杂度都为O(n),那么还有没有办法进一步减小时间复杂度呢?上一次我们介绍了二分查找(戳这里如何写好二分查找?),提到了其有序的特点使得查找的时间复杂度降到了O(logn),那如果我们结合二分查找和链表来做呢?那么首先一个问题是,要使得链表变得有序,每次插入平均都需要遍历n/2个元素,这样时间复杂度就上去了。因此,光靠简单的组合并不能有效减小时间复杂度,我们需要对原始的结构进行一些改动。
跳跃表结构
根据上面的分析,也就是说我们需要一种数据结构,能够做到插入、删除和查找任意值的时间复杂度都能低于O(n)。接下来介绍的跳跃表结构,就能很好的解决这样的问题。
首先,跳跃表是由链表拓展而来的,但是同时它存放的元素也是有序排列的。为了能够减少插入和删除的时间,使用多层索引查找的方式。在算法导论这本书中还提到说跳跃表算是一种平衡树结构,也确实在复杂度等方面和二叉树方面有着相似的性质。
具体是什么样子的呢?我们画个图来解释。
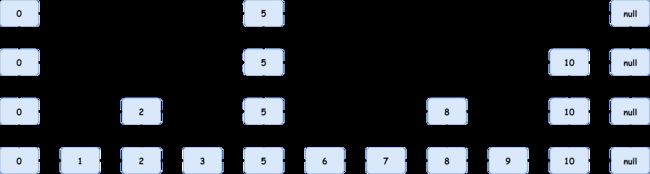
上面的示例图表示一个具有四层的跳跃表结构。从图中可以总结出一些性质:
- 跳跃表的最底层包含了所有元素,而每个结点中有一定几率出现在上层,我们称结点向上生长为晋升。
- 只有下层的每一层都有某个元素的结点,该元素结点才有可能继续晋升。
- 链表的第一个元素结点往往是每层都存在的。
- 整个链表每一层都是有序的,从小到大排列。
查找和构建
如何进行查找呢?首先这个跳跃表的头结点应该是指向的第一个元素结点的最高层,接着开始遍历最高层链表,如果访问的结点元素值小于查询值就继续遍历,如果访问结点元素值大于了查询值则下降到下一层链表中来查找,这时起始位置为刚刚访问结点的前一个结点。或者如果已经到了该层链表的尾部,那么下降到下一层的对应结点开始遍历。接着重复上面的过程,直到查找到最后的值;或者在最底层仍然没有查找到,说明该元素不存在。
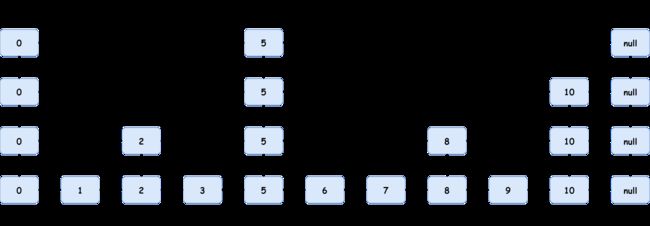
那么如何构建这样一个跳跃表呢?也就是说,如何插入一个新的结点呢?首先,由于跳跃表是有序的,那么插入会先查询到不大于该结点的最后一个结点位置后准备插入,插入的过程其实和链表就是一样的。只不过跳跃表的每个结点需要事先确定晋升多少层。为了保证高效的查找性能,那么上层的结点就不能过多,同时理想状态下能够均匀分布开来。因此,可以采取类似投掷硬币的随机方式来决定是否晋升,这种晋升方式有1/2的概率成功。当结点每一次想再向上晋升时,都通过这种随机的方式判断,如果晋升成功,那么就决定是否再一次晋升,直到晋升失败,此时决定了该结点的最终层数。再将每一层结点和每一层链表连接起来就可以了。
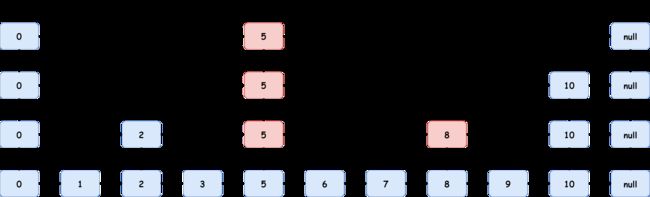
从整个跳跃链表的构建和查询方式来看,每个结点层数每次是否晋升完全随机,那么从数学期望的角度来看,理想的情况是每一层相邻两个结点中有一个会向上晋升,那么在最高层除了最大和最小值就应该只有中间值了,而接下来的每一层会增加左右半部分的中间值,因此整个结构查询起来类似于二分查找。
如果要删除跳跃表中的一个结点,那么直接删除所有层中的该结点即可,也就是说在每一层链表中删除目标结点。具体的操作将专门在一篇博客中解析。
复杂度分析
看起来好像跳跃表似乎查找插入是要快一些,但是它可是有多层链表的啊,所以可能就会有人说,这是不是拿空间换时间的呢?看起来好像确实空间增加了不少,但是具体是怎样的我们还是要通过数学来证明。
空间复杂度分析
首先来看跳跃表的高度,也就是跳跃表的层数。对底层一个结点来说,它会向上增长的概率为1/2,则到第m层向上增长的概率为1/2m;n个元素,则在m层结点数目的期望为Em = n/2m;最后一层结点数Em = 1,m = log2n即为层数的期望。故其高度期待为 Eh = O(log n)。
再来看总的结点个数,也就是空间复杂度。对于每层的结点数期望:第一层n,第二层n/2,第三层n/22,…,直到 n/2logn=1。所以,总空间需求:
S = n + n/2 + n/22 + … + n/2logn < n(1 + 1/2 + 1/22 + … + 1/2∞) =2n
因此他的空间复杂度为 2n = O(n)。
时间复杂度分析
时间复杂度的分析是有点困难的,这里给出一些思路来:
查找
首先来看查找,上面提到了,跳跃表的查询类似于二分查找,因此通过二分查找的方式来分析:
二分查找每次排除掉一半的不适合值,所以对于n个元素的情况:
一次二分剩下:n/2;
两次二分剩下:n/22 = n/4;
m次二分剩下:n/2m;
在最坏情况下是在排除到只剩下最后一个值之后得到结果,即n/2m=1;
解得:m=log2 n。即时间复杂度为O(log n)。
除了上面的二分查找之外,还可以使用归纳法来分析:由于理想结构下同一层相邻两结点会有一个在上层,因此在一层搜索的结点数应该不会大于3,以最坏打算则每一层搜索结点数都为3。上面分析得到表的高度为 log2n,则总的搜索数为3 log2n,即O(log n)。
插入/删除
插入和删除时,分为查找和操作两部分。查找过程时间复杂度为O(log n),而操作部分与表的高度成正比,因此也是O(log n),最终即为O(log n)。
总结
这篇博客主要介绍了一下跳跃表的结构和思想,并且从数学角度做了复杂度分析,证明了其在空间复杂度不变的情况下大大提高了操作的效率。但是这样一个结构应该如何去实现它呢?之后有一篇博客将会专门介绍程序编写。