商业智能工具KNIME
KNIME是基于Eclipse环境的开源商业智能工具。KNIME开发环境如图一. 从图中可以看出KNIME是通过工作流来控制数据的集成、清洗、转换、过滤,再到统计、数据挖掘,最后是数据的可视化。整个开发都在可视化的环境下进行,通过简单的拖曳和设置就可以完成一个流程的开发。通过KNIME的白皮书得知KNIME的全称是The Konstanz Information Miner。它的设计目的是用于教学、研究以及协同工作的平台。
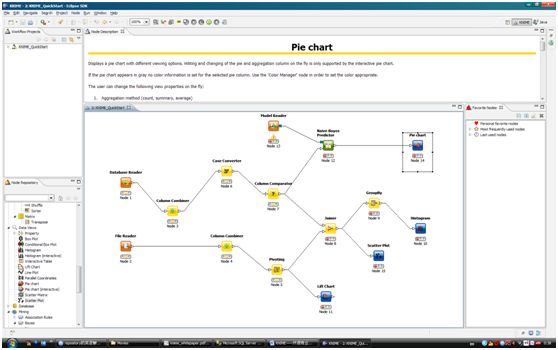
图一:KNIME开发环境
KNIME架构特点
KNIME被设计成一种模块化的、易于扩展的框架。它的处理单元和数据容器之间没有依赖性,这使得它们更加适应分布式环境及独立开发。另外,对KNIME进行扩展也是比较容易的事情。开发人员可以很轻松地扩展KNIME的各种类型的结点、视图等。
在KNIME中,数据分析流程由一系列结点及连接结点的边组成。待处理的数据或模型在结点之间进行传递。每个结点都有一个或多个输入端和输出端。数据或模型从结点的输入端进入经结点处理后从结点的输出端输出(如图二)。所有在结点之间传递的数据流都被封装成DataTable对象。为了处理大数据量,KNIME允许只保留部分数据在内存中处理,以此来提高处理效率。
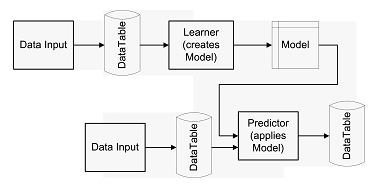
图二:结点处理模型
结点是KNIME中主要的处理单元。Node类封装了所有的处理功能,如果要开发用户自定义的结点,就要实现一个NodeModel类、一个或多个NodeView类。当然,如果定自义结点没有对话框和视图,也可以不用实现NodeModel和NodeView类。结点的扩展是基于MVC设计模式的。此外,每个结点的输入端口和输出端口都是有编号的,如果有多个端口,这些端口的索引都是从0开始。
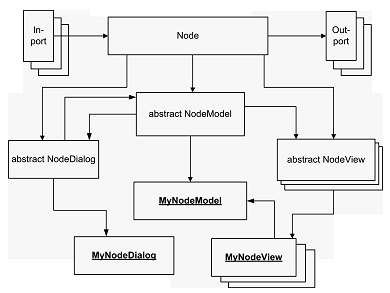
图三:KNIME结点结构
KNIME提供了大量的结点,这些结点包含不同的功能,包括IO操作、数据处理、数据转换以及数据挖掘、机器学习和可视化组件。其中,IO操作可以从文件系统读写数据;数据处理包括数据行和数据列过滤、分区以及抽样、排序、合并等;数据转换包括缺失值替换、矩阵转换等;数据挖掘算法包括KMEANS、决策树、回归、关联规则等方法。处理完成后,可以通过各种各样的图形将其展示出来,包括散点图、直方图、饼图、折线图等。
前面已经提到KNIME提供了一种易于扩展的架构。如果要开发新的结点,要扩展三个抽象类:
NodeModel: 这个类是扩展结点最主要的一个类,所有关键的处理工作都在这个类中完成。继承这个抽象类要实现三个方法:configure(), execute()和reset()。第一个方法用于接收输入端口进来的信息并创建相应的输出端的定义。第二个方法用于处理输入数据并创建用于输出的数据表或模型。最后一个方法用于重置所有操作并丢弃所有中间结果。
NodeDialog: 这个类用于指定结点的对话框。每个结点都有一个对话框用于设置结点处理功能的所有参数。
NodeView: 这个类可以重写多次用于实现不同类型的视图,用于对应不同的模型。
在所有的类被重写以后还需要实现一个NodeFactory用于创建新的实例。
以上就是关于商业智能工具KNIME的一些信息。在看完KNIME的白皮书后我也去用了一下KNIME,的确是很好上手。很快就可以设计出一个完整的处理流程。大家不妨也去试试,一定会很有意思的。如果可以多了解一些类似的工具或框架,那么在制定项目的技术路线的时候会有更多的选择。