每个时代,都不会亏待会学习的人。
大家好,我是 yes。
HTTP 协议在当今的互联网可谓是随处可见,一直默默的在背后支持着网络世界的运行,对于我们程序员来说 HTTP 更是熟悉不过。
平日里我们都说架构是演进的,需求推动着技术的迭代、更新和进步,对于 HTTP 协议来说也是如此。
不知你是否有想过 HTTP 协议是如何诞生的,一开始是怎样的,又是怎么一步一步发展到今天的 HTTP/3 ?
其中经历了哪些不为人知的秘密?
今天我就想和大家一起来看一看 HTTP 的演进之路,来看看它是如何从一个小宝宝成长为现在统治互联网的存在。
不过在此之前,我们先简单的看看互联网的始祖-阿帕网的一段小历史,还是很有趣的。
互联网的始祖-阿帕网
在 1950 年代,通信研究者们认识到不同计算机用户和网络之间的需要通信,这促使了分布式网络、排队论和封包交互的研究。
在1958 年2月7日,美国国防部长尼尔 · 麦克尔罗伊发布了国防部 5105.15 号指令,建立了高级研究计划局(ARPA) 。

ARPA 的核心机构之一 IPTO(信息处理处)赞助的一项研究导致了阿帕网的开发。
我们来看看这段历史。
在 1962 年,ARPA 的主任聘请约瑟夫·利克莱德担任 IPTO 的第一任主任,他是最早预见到现代交互计算及其在各种应用的人之一。
IPTO 资助了先进的计算机和网络技术的研究,并委托十三个研究小组对人机交互和分布式系统相关技术进行研究。每个小组获得的预算是正常研究补助金的三十至四十倍。
这就是财大气粗啊,研究人员肯定是干劲十足!
在 1963 年利克莱德资助了一个名为 MAC 的研究项目,该项目旨在探索在分时计算机上建立社区的可能性。
这个项目对 IPTO 和更广泛的研究界产生了持久的影响,成为广泛联网的原型。
并且利克莱德的全球网络愿景极大地影响了他在 IPTO 的继任者们。
1964 年利克莱德跳槽到了 IBM,第二任主任萨瑟兰上线,他创建了革命性的 Sketchpad 程序,用于存储计算机显示器的内存,在 1965 年他与麻省理工学院的劳伦斯 · 罗伯茨签订了 IPTO 合同,以进一步发展计算机网络技术。
随后,罗伯茨和托马斯 · 梅里尔在麻省理工学院的 TX-2 计算机和加利福尼亚的 Q-32 计算机之间,通过拨号电话连接实现了第一个数据包交换。
1966 年第三任主任鲍勃 · 泰勒上任,他深受利克莱德的影响,巧的是泰勒和利克莱德一样也是个心理声学家。

在泰勒的 IPTO 办公室里有三个不同的终端连接到三个不同的研究站点,他意识到这种架构将严重限制他扩展访问多个站点的能力。
于是他想着把一个终端连接到一个可以访问多个站点的网络上,并且从他在五角大楼的职位来说,他有这个能力去实现这个愿景。
美国国防部高级研究计划局局长查理 · 赫茨菲尔德向泰勒承诺,如果 IPTO 能够组织起来,他将提供 100 万美元用于建立一个分布式通信网络。
泰勒一听舒服了,然后他对罗伯茨的工作印象很深刻,邀请他加入并领导这项工作,然后罗伯茨却不乐意。
泰勒不高兴了,于是要求赫茨菲尔德让林肯实验室的主任向罗伯茨施压,要求他重新考虑,这最终促使罗伯茨缓和了态度,于1966年12月加入 IPTO 担任首席科学家。

在 1968 年6月3日,罗伯茨向泰勒描述了建立阿帕网的计划,18 天后,也就是 6 月 21 日,泰勒批准了这个计划,14 个月后阿帕网建立。
当阿帕网顺利发展时,泰勒于 1969 年9月将 IPTO 的管理权移交给罗伯茨。
随后罗伯茨离开 ARPA 成为 Telenet 的 CEO ,而利克莱德再次回到 IPTO 担任董事,以完成该组织的生命周期。
至此,这段历史暂告一段落,可以看到阿帕网之父罗伯茨还是被施压的才接受这项任务,最终创建了阿帕网,互联网的始祖。
也多亏了利克莱德的远见和砸钱促进了技术的发展,ARPA 不仅成为网络诞生地,同样也是电脑图形、平行过程、计算机模拟飞行等重要成果的诞生地。
历史就是这么的巧合和有趣。
互联网的历史
在 1973 年 ARPA 网扩展成互联网,第一批接入的有英国和挪威计算机,逐渐地成为网络连接的骨干。
1974 年 ARPA 的罗伯特·卡恩和斯坦福的文顿·瑟夫提出TCP/IP 协议。
1986 年,美国国家科学基金会(National Science Foundation,NSF)建立了大学之间互联的骨干网络 NSFNET ,这是互联网历史上重要的一步,NSFNET 成为新的骨干,1990 年 ARPANET 退役。
在 1990 年 ,蒂姆·伯纳斯-李(下文我就称李老) 创建了运行万维网所需的所有工具:超文本传输协议(HTTP)、超文本标记语言(HTML)、第一个网页浏览器、第一个网页服务器和第一个网站。

至此,互联网开启了快速发展之路,HTTP 也开始了它的伟大征途。
还有很多有趣的历史,比如第一次浏览器大战等等,之后有机会再谈,今天我们的主角是 HTTP。
接下来我们就看看 HTTP 各大版本的演进,来看看它是如何成长到今天这个样子的。
HTTP / 0.9 时代
在 1989 年,李老发表了一篇论文,文中提出了三项现在看来很平常的三个概念。
- URI,统一资源标识符,作为互联网上的唯一标识。
- HTML,超文本标记语言,描述超文本。
- HTTP ,超文本传输协议,传输超文本。
随后李老就付之于行动,把这些都搞出来了,称之为万维网(World Wide Web)。
那时候是互联网初期,计算机的处理能力包括网速等等都很弱,所以 HTTP 也逃脱不了那个时代的约束,因此设计的非常简单,而且也是纯文本格式。
李老当时的想法是文档存在服务器里面,我们只需要从服务器获取文档,因此只有 “GET”,也不需要啥请求头,并且拿完了就结束了,因此请求响应之后连接就断了。
这就是为什么 HTTP 设计为文本协议,并且一开始只有“GET”、响应之后连接就断了的原因了。
在我们现在看来这协议太简陋了,但是在当时这是互联网发展的一大步!一个东西从无到有是最困难的。
这时候的 HTTP 还没有版本号的,之所以称之为 HTTP / 0.9 是后人加上去了,为了区别之后的版本。
HTTP 1.0 时代
人们的需求是无止尽的,随着图像和音频的发展,浏览器也在不断的进步予以支持。
在 1995 年又开发出了 Apache,简化了 HTTP 服务器的搭建,越来越多的人用上了互联网,这也促进了 HTTP 协议的修改。
需求促使添加各种特性来满足用户的需求,经过了一系列的草案 HTTP/1.0 于 1996 年正式发布。
Dave Raggett 在1995年领导了 HTTP 工作组,他希望通过扩展操作、扩展协商、更丰富的元信息以及与安全协议相关的安全协议来扩展协议,这种安全协议通过添加额外的方法和头字段来提高效率。

所以在 HTTP/1.0 版本主要增加以下几点:
- 增加了 HEAD、POST 等新方法。
- 增加了响应状态码。
- 引入了头部,即请求头和响应头。
- 在请求中加入了 HTTP 版本号。
- 引入了 Content-Type ,使得传输的数据不再限于文本。
可以看到引入了新的方法,填充了操作的语义,像 HEAD 还可以只拿元信息不必传输全部内容,提高某些场景下的效率。
引入的响应状态码让请求方可以得知服务端的情况,可以区分请求出错的原因,不会一头雾水。
引入了头部,使得请求和响应更加的灵活,把控制数据和业务实体进行了拆分,也是一种解耦。
新增了版本号表明这是一种工程化的象征,说明走上了正途,毕竟没版本号无法管理。
引入了 Content-Type,支持传输不同类型的数据,丰富了协议的载体,充实了用户的眼球。
但是那时候 HTTP/1.0 还不是标准,没有实际的约束力,各方势力不吃这一套,大白话就是你算老几。
HTTP 1.1 时代
HTTP/1.1 版本在 1997 的 RFC 2068 中首次被记录,从 1995 年至 1999 年间的第一次浏览器大战,极大的推动了 Web 的发展。
随着发展 HTTP/1.0 演进成了 HTTP/1.1,并且在 1999 年废弃了之前的 RFC 2068,发布了 RFC 2616。
从版本号可以得知这是一个小版本的更新,更新主要是因为 HTTP/1.0 很大的性能问题,就是每请求一个资源都得新建一个 TCP 连接,而且只能串行请求。
所以在 HTTP/1.1 版本主要增加以下几点:
- 新增了连接管理即 keepalive ,允许持久连接。
- 支持 pipeline,无需等待前面的请求响应,即可发送第二次请求。
- 允许响应数据分块(chunked),即响应的时候不标明Content-Length,客户端就无法断开连接,直到收到服务端的 EOF ,利于传输大文件。
- 新增缓存的控制和管理。
- 加入了 Host 头,用在你一台机子部署了多个主机,然后多个域名解析又是同一个 IP,此时加入了 Host 头就可以判断你到底是要访问哪个主机。
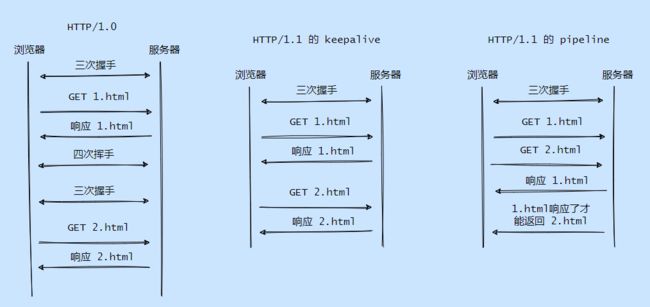
可以看到浏览器大战推进了 Web 的发展,也暴露出 HTTP/1.0 的不足之处,毕竟网络带宽等等都在进步,总不能让协议限制了硬件的发展。
因此提出了 HTTP/1.1 ,主要是为了解决性能的问题,包括支持持久连接、pipeline、缓存管理等等,也添加了一些特性。
再后来到 2014 年对 HTTP/1.1 又做了一次修订,因为其太过庞大和复杂,因此进行了拆分,弄成了六份小文档 RFC7230 - RFC7235
这时候 HTTP/1.1 已经成了标准,其实标准往往是在各大强力竞争对手相对稳定之后建立的,因为标准意味着统一,统一就不用费劲心思去兼容各种玩意。
只有强大的势力才能定标准,当你足够强大的时候你也可以定标准,去挑战老标准。
HTTP 2 时代
随着 HTTP/1.1 的发布,互联网也开始了爆发式的增长,这种增长暴露出 HTTP 的不足,主要还是性能问题,而 HTTP/1.1 无动于衷。
这就是人的惰性,也符合平日里我们对产品的演进,当你足够强大又安逸的时候,任何的改动你是不想理会的。
别用咯。

这时候 Google 看不下去了,你不搞是吧?我自己搞我的,我自己和我自己玩,我用户群体大,我有 Chrome,我服务多了去了。
Google 推出了 SPDY 协议,凭借着它全球的占有率超过了 60% 的底气,2012年7月,开发 SPDY 的小组公开表示,它正在努力实现标准化。
HTTP 坐不住了,之后互联网标准化组织以 SPDY 为基础开始制定新版本的 HTTP 协议,最终在 2015 年发布了 HTTP/2。
HTTP/2 版本主要增加以下几点:
- 是二进制协议,不再是纯文本。
- 支持一个 TCP 连接发起多请求,移除了 pipeline。
- 利用 HPACK 压缩头部,减少数据传输量。
- 允许服务端主动推送数据。
从文本到二进制其实简化了整齐的复杂性,解析数据的开销更小,数据更加紧凑,减少了网络的延迟,提升了整体的吞吐量。

支持一个 TCP 连接发起多请求,即支持多路复用,像 HTTP/1.1 pipeline 还是有阻塞的情况,需要等前面的一个响应返回了后面的才能返回。
而多路复用就是完全异步化,这减少了整体的往返时间(RTT),解决了 HTTP 队头阻塞问题,也规避了 TCP 慢启动带来的影响。
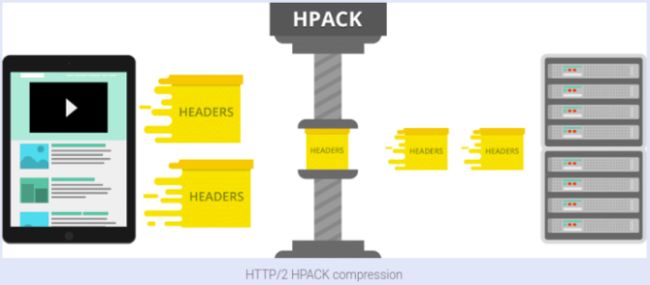
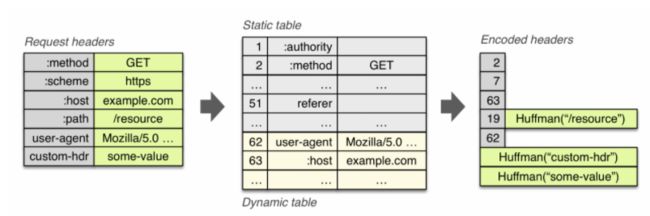
HPACK 压缩头部,采用了静态表、动态表和哈夫曼编码,在客户端和服务器都维护请求头的列表,所以只需要增量和压缩过的头部信息,服务端拿到之后组装一下就能得到完整的头部信息。
形象一点就是如下图所示:
再具体一点就是下图这样:
服务端主动推送数据,这个其实就是减少了请求的次数,比如客户端请求 1.html,我把 1.html 需要的 js 和 css 也一块送过去,省的之后客户端再请求我要 js ,我要这个 css。
可以看到 HTTP/2 的整体演进都是往性能优化的角度发展,因为此时的性能就是痛点,任何东西的演进都是哪里痛医哪里。
当然有一些例外,比如一些意外,或者就是“闲的蛋疼”的那种捯饬。
这次推进属于用户揭竿而起为之,你再不给我升级我自己搞了,我有着资本,你自己掂量。
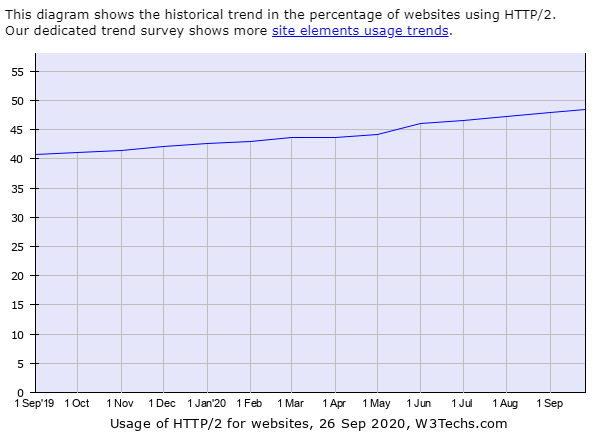
最终结果是好的,Google 后来放弃了 SPDY ,拥抱标准,而 HTTP/1.1 这个历史包袱太重了,所以 HTTP/2 到现在也只有大致一半的网站使用它。
HTTP 3 时代
这 HTTP/2 还没捂热, HTTP/3 怎么就来了?
这次又是 Google,它自己突破自己,主要也是源自于痛点,这次的痛点来自于 HTTP 依赖的 TCP。
TCP 是面向可靠的、有序的传输协议,因此会有失败重传和按序机制,而 HTTP/2 是所有流共享一个 TCP 连接,所以会有 TCP 层面的队头阻塞,当发生重传时会影响多个请求响应。
并且 TCP 是基于四元组(源IP,源端口,目标IP,目标端口)来确定连接的,而在移动网络的情况下 IP 地址会频繁的换,这会导致反复的建连。
还有 TCP 与 TLS 的叠加握手,增加了延时。
问题就出在 TCP 身上,所以 Google 就把目光瞄向了 UDP。
UDP 我们知道是无连接的,不管什么顺序,也不管你什么丢包,而 TCP 我在之前的文章说的很清楚了TCP疑难杂症解析不了解的同学可以去看看。
简单的说就是 TCP 太无私了,或者说太保守了,现在需要一种更激进的做法。
那怎么搞? TCP 改不动我就换!然后把 TCP 可靠、有序的功能提到应用层来实现,因此 Google 就研究出了 QUIC 协议。

QUIC 层来实现自己的丢包重传和拥塞控制,还有出于安全的考虑我们都会用 HTTPS ,所以需要多次握手。
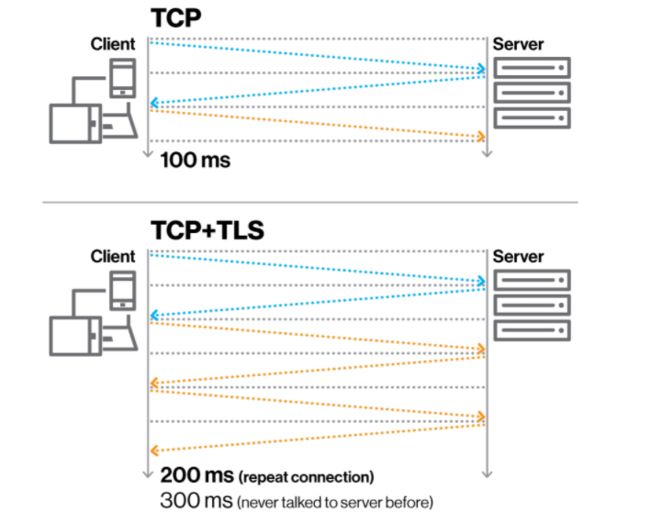
上面我也已经提到了关于四元组的情况,所以在移动互联网时代这握手的消耗就更加放大了,于是 QUIC 引入了个叫 Connection ID 来标识一个链接,所以切换网络之后可以复用这个连接,达到 0 RTT 就能开始传输。
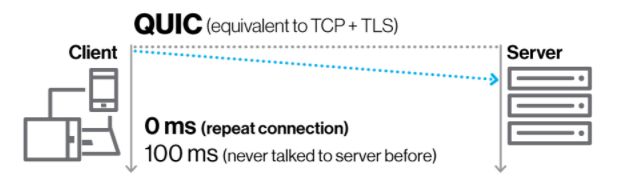
注意上图是在已经和服务端握过手之后的,由于网络切换等原因才有 0 RTT ,也就是 Connection ID 在之前生成过了。
如果是第一次建连还是需要多次握手的,我们来看一下简化的握手对比图。
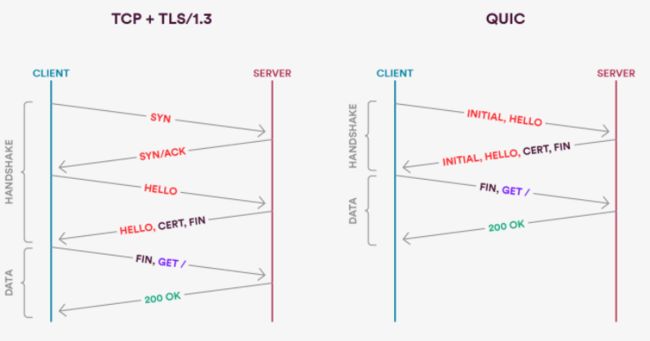
所以所谓的 0RTT 是在之前已经建连的情况下。
当然还有 HTTP/2 提到的 HPACK,这个是依赖 TCP 的可靠、有序传输的,于是 QUIC 得搞了个 QPACK,也采用了静态表、动态表和哈夫曼编码。
它丰富了 HTTP/2 的静态表,从 61 项加到了 98 项。
上面提到的动态表,是用来存储未包含在静态表中的头部项,假设动态表还未收到,后面来解头部的时候肯定要被阻塞的。
所以 QPACK 就另开一条路,在单向的 Stream 里传输动态表的编解码,单向传输好了,接受端到才能开始解码,也就是说还没好你就先别管,防止做一半卡住了。
那还有前面提到的 TCP 队头阻塞, QUIC 是怎么解决的呢?毕竟它也要保证有序和可靠啊。
因为 TCP 不认识每个流分别是哪个请求的,所以它只能全部阻塞住,而 QUIC 知道,因此比如请求 A 丢包了,我就把 A 卡住了就行,请求 B 完全可以全部放行,丝毫不受影响。
可以看到基于 UDP 的 QUIC 还是很强大的,而且人家用户多,在 2018 年,互联网标准化组织 IETF 提议将 HTTP over QUIC 更名为 HTTP/3 并获得批准。
可以看到需求又推动技术的进步,由于 TCP 自身机制的限制,我们的目光已经往 UDP 上靠了,那 TCP 会不会成为历史呢?
我们拭目以待。
最后
今天我们大致过了一遍 HTTP 发展的历史和它的演进之路,可以看到技术是源于需求,需求推动着技术的发展。
本质上就是人的惰性,只有痛了才会成长。
而且标准其实也是巨头们为了他们的利益推动的,不过标准确实能减轻对接的开销,统一而方便。
当然就 HTTP 来说还是有很多内容的,有很多细节,很多算法,比如拿 Connection ID 来说,不同的四元组你如何保证请求一定会转发到之前的服务器上?
所以今天我只是浅显的谈了谈大致的演进,具体的实现还是得靠各位自己摸索,或者之后有机会我再写一些。
不过相对于这些实现细节我更感兴趣的是历史的演进,这能让我从时代背景等一些约束来得知,为什么这东西一开始是这么设计的,从而更深刻的理解这玩意。
而且历史还是很有趣的,不是么?
我是 yes,从一点点到亿点点,我们下篇见。
巨人的肩膀
https://www.livinginternet.com/i/ii_ipto.htm
https://jacobianengineering.com/blog/2016/11/1543/
https://w3techs.com/technologies/details/ce-http2
https://www.verizondigitalmedia.com/blog/how-quic-speeds-up-all-web-applications/
https://www.oreilly.com/content/http2-a-new-excerpt/
https://www.darpa.mil/about-us/timeline/dod-establishes-arpa
https://en.wikipedia.org/wiki/ARPANET
https://en.wikipedia.org/wiki/Internet
深入剖析HTTP/3协议 ,陶辉
透视HTTP协议 ,罗剑锋