如何在图数据库中训练图卷积网络模型
在图数据库中训练GCN模型,可以利用图数据库的分布式计算框架现实应用中大型图的可扩展解决方案
什么是图卷积网络?
典型的前馈神经网络将每个数据点的特征作为输入并输出预测。利用训练数据集中每个数据点的特征和标签来训练神经网络。这种框架已被证明在多种应用中非常有效,例如面部识别,手写识别,对象检测,在这些应用中数据点之间不存在明确的关系。但是,在某些使用情况下,当v(i)与v(i)之间的关系不仅仅可以由数据点v(i)的特征确定,还可以由其他数据点v(j)的特征确定。 j)给出。例如,期刊论文的主题(例如计算机科学,物理学或生物学)可以根据论文中出现的单词的频率来推断。另一方面,在预测论文主题时,论文中的参考文献也可以提供参考。在此示例中,我们不仅知道每个单独数据点的特征(词频),而且还知道数据点之间的关系(引文关系)。那么,如何将它们结合起来以提高预测的准确性呢?
通过应用图卷积网络(GCN),单个数据点及其连接的数据点的特征将被组合并馈入神经网络。 让我们再次以论文分类问题为例。 在引文图中(图1),每论文都用引文图中的顶点表示。 顶点之间的边缘代表引用关系。 为了简单起见,将边缘视为未定向。 每篇论文及其特征向量分别表示为v_i和x_i。 遵循Kipf和Welling [1]的GCN模型,我们可以使用具有一个隐藏层的神经网络通过以下步骤来预测论文的主题:

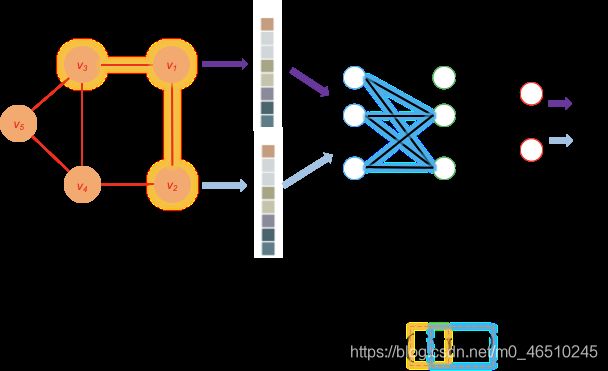
图1.图卷积网络的体系结构。每个顶点vi在引用图中代表一个论文。xi是vi的特征向量。W(0)和W(1)是3层神经网络的权重矩阵。 ,D和I分别是细分矩阵,out度矩阵和恒等矩阵。水平和垂直传播分别以橙色和蓝色突出显示。
在上述工作流程中,步骤1和步骤4执行水平传播,其中每个顶点的信息都传播到它的邻居。 第2步和第5步执行垂直传播,其中每一层的信息都传播到下一层。 (见图1)对于具有多个隐藏层的GCN,水平和垂直传播将进行多次迭代。 值得注意的是,每次执行水平传播时,顶点信息都会在图中进一步单跳传播。 在此示例中,水平传播执行了两次(步骤2和4),因此每个顶点的预测不仅取决于其自身的特征,而且还取决于距其2跳距离内的所有顶点的特征。 另外,由于权重矩阵W(0)和W(1)由所有顶点共享,因此神经网络的大小不必随图的大小而增加,这使此方法可伸缩。
为什么需要GCN的图形数据库
通过合并每个顶点的图形特征,GCN可以以低标签率实现高精度。在Kipf和Welling的工作中[1],使用图形中5%的标记顶点(实体)可以获得80%的精度。考虑到整个图在传播过程中需要参与计算,训练GCN模型的空间复杂度为O(E + V * N + M),其中E和V是图中的边和顶点数量N是每个顶点的特征数量,M是神经网络的大小。
对于工业应用,图可以具有数亿个顶点和数十亿条边,这意味着在模型训练期间,邻接矩阵A,特征矩阵X和其他中间变量(图1)都可能消耗数TB的内存。可以通过在图数据库(GDB)中训练GCN来解决这种挑战,在该数据库中,图可以分布在多节点群集中并部分存储在磁盘上。此外,首先将图结构的用户数据(例如社交图,消费图和移动图)存储在数据库管理系统中。数据库内模型训练还避免了将图形数据从DBMS导出到其他机器学习平台,从而更好地支持了不断发展的训练数据的连续模型更新。
如何在图形数据库中训练GCN模型
在本节中,我们将在TigerGraph云上(免费试用)提供一个图数据库,加载一个引用图,并在数据库中训练GCN模型。按照以下步骤操作,您将在15分钟内得到一个论文分类模型。
我们使用GraphStudio作为入门的工具,我们使用CORA数据集(https://relational.fit.cvut.cz/dataset/CORA)
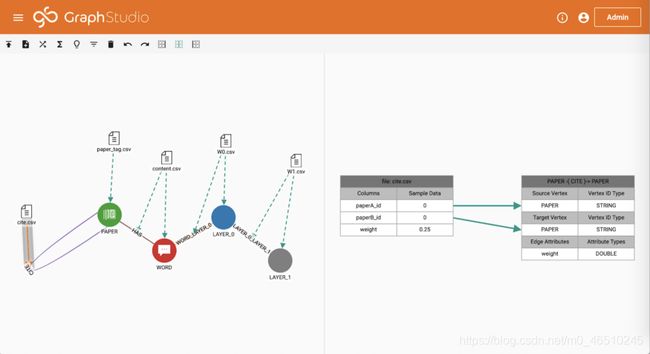
Cora数据集包含三个文件:
cite.csv具有三列,paperA_id,paperB_id和weight。 前两列用于在论文之间创建CITE边缘。 查询将在以下步骤中更新CITE边缘上的权重,因此不需要加载最后一列。 应该注意的是,该入门工具包中的文件在每篇论文中都添加了自链接,以简化查询的实现。 这与Kipf和Welling [1]的方法是一致的。
paper_tag.csv具有两列,paper_id和class_label。 该文件中的每一行都将用于创建一个PAPER顶点,其中包含从文件填充的论文ID和论文类别。
content.csv具有三列,paper_id,word_id和weight。 前两列用于在论文和文字之间创建HAS边缘。 HAS边缘将用于存储稀疏词袋特征向量。 查询将在以下步骤中更新HAS边缘上的权重,因此不需要加载最后一列。
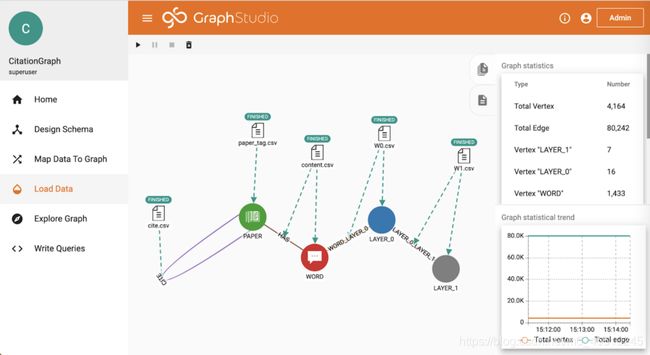
转到“加载数据”页面,然后单击“开始/继续加载”。 加载完成后,您可以在右侧看到图形统计信息。 Cora数据集包含2708篇论文,1433个不同的单词(特征向量的维数)和7986个引用关系。 每篇论文都用7种不同类别中的1种标记。
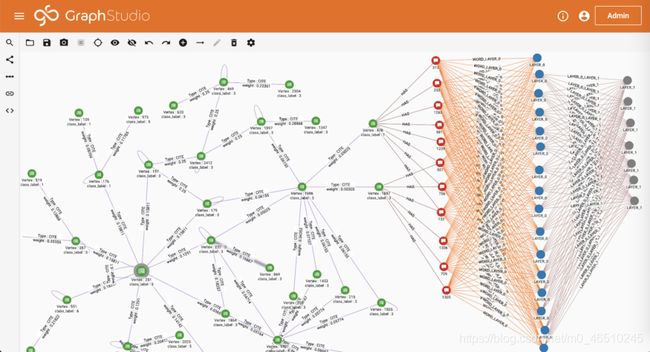
在“浏览图”页面中,您可以看到我们刚刚在引用图的顶部创建了一个神经网络。 引用图中的每篇论文都连接到多个单词。 因此,HAS边缘上的权重形成一个稀疏特征向量。 1433个不同的词连接到隐藏层中的16个神经元,而隐藏层连接到输出层中的7个神经元(代表7个不同的类)。
在“写查询”页面中,您将找到GCN所需的查询已添加到数据库中。 查询使用TigerGraph的查询语言GSQL编写。 单击“安装所有查询”以将所有GSQL查询编译为C ++代码。 您也可以在此页面上看到自述查询。 请按照以下步骤训练GCN。
运行初始化查询
此查询首先通过将论文i和j之间的权重分配为e_ij = 1 /(d_i * d_j)来归一化CITE边缘上的权重,其中d_i,d_j是论文i和论文j的CITE输出度。 其次,通过将论文p和单词w之间的权重分配为e_pw = 1 / dp来归一化HAS边缘上的权重,其中dp是论文w的HAS出度。 第三,它对140、500和1000个论文顶点进行采样,以进行测试,验证和训练。
运行weight_initialization查询
该查询使用Glorot和Bengio [2]的方法初始化神经网络的权重。该神经网络在输入层中有1433个神经元对应于词汇的大小,在隐藏层中有16个神经元,在输出层中有7个神经元,对应于论文的7类。
运行训练查询
该查询使用与Kipf和Welling [1]中使用的相同的超参数训练图卷积神经网络。具体而言,使用第一层的交叉熵损失,dropout和L2正则化(5e-4)评估模型。 Adam优化器已在此查询中实现,并且批次梯度下降用于训练。查询结束后,将显示在训练和验证数据上评估的损失以及在测试数据上评估的预测准确性。如训练查询的输出所示,经过5个训练轮次后,准确性达到53.2%。可以将轮次数设置为查询输入,以提高准确性。

运行预测查询
该查询将训练完成的GCN应用于图表中的所有论文,并可视化结果。

GSQL查询概述
在上一节中,我们将深入探讨这些查询,以了解TigerGraph的大规模并行处理框架如何支持训练GCN。 简而言之,TigerGraph将每个顶点视为可以存储,发送和处理信息的计算单元。 我们将在查询中选择一些语句,以说明如何执行GSQL语句。
SELECT语句:
我们先来看一下查询初始化。 第一行将初始化包含图形中所有PAPER顶点的顶点集Papers。 在下一个SELECT语句中,我们将从顶点集Papers开始,并遍历所有CITE边。 对于每个边缘(由e表示),其边缘权重是根据其源顶点(由s表示)和目标顶点(由t表示)的平行度来计算的。

ACCUM和POST-ACCUM
现在,让我们看一下查询训练。 正如我们在上一节中讨论的那样,水平传播是我们从每个顶点向相邻顶点发送信息的地方,这是通过ACCUM之后的行完成的。 它将每个目标顶点的特征向量(称为t。@ z_0)计算为其源顶点的特征向量(称为s.zeta_0)并按e.weight加权。 下一个POST-ACCUM块进行垂直传播。 它首先将ReLU激活函数和辍学正则化应用于每个顶点上的特征向量。 然后,它将隐藏层要素(称为s.z_z_0)传播到输出层。 同样,TigerGraph将针对边和顶点并行化ACCUM和POST-ACCUM块中的计算。

用户定义的功能
激活函数用C ++实现,并导入到TigerGraph用户定义的函数库中。 下面是ReLU函数(ReLU_ArrayAccum)的实现

结论
在图数据库中训练GCN模型利用了图数据库的分布式计算框架。 它是现实应用中大型图的可扩展解决方案。 在本文中,我们将说明GCN如何将每个节点的特征与图特征结合起来以提高图中的节点分类的准确性。 我们还展示了使用TigerGraph云服务在引文图上训练GCN模型的分步示例。
引用
[1] Thomas. N. Kipf and Max Welling, ICLR (2017)
[2] Glorot and Bengio, AISTATS (2010)
作者:Changran Liu
deephub翻译组