-
一、正则表达式
正则表达式(regular expression)是由一些特定字符以及组合所组成的字符串表达式,用来对目标字符串进行过滤操作。目前,大部分操作系统(Linux、UNIX、Windows 等)和程序设计语言(Visual Basic、C#、Python、Java、C++、Objective-C、Swift、PHP、JavaScrip、Ruby等)均支持正则表达式的应用。
正则表达式的常见基本符号:如下基本符号 含义 解释 d 数字 D为非数字 w 单词字符(大小写字母和数字) W为非单词字符 . 单个字符 代表除换行以外的任意单个字符。例如:'a.c'可代表'abc'、'acc'等等,三位 ? 多个字符,非贪婪模式符 匹配一个字符0次或1次 * 多个字符 匹配一个字符0次或无数次 + 多个字符 匹配一个字符1次或无数次 | 或 分隔符之间 “或”的逻辑关系,例如:'[P|p]ython'能匹配出'Python'或'python' ^ 开始 引导字符串开始的特征 $ 结尾 引导字符串结尾的特征 \ 转义 为其后面的符号转义,但为避免与Python字符串本身的转义相混淆,建议正则表达式以 r 前缀 统一转义,例如: '\d'可表示为r'd'[ ] 界定单个字符 --- () 界定一个整体 --- {} 重复次数 --- 正则表达式就是用这些基本的符号字符,以单个字符、字符集合、字符范围、字符间的组合等形式组成模板,然后用这个模板与所搜索的字符传进行匹配。利用正则表达式对字符串的匹配通常分为精确匹配和贪婪匹配两种。
-
1.1、精准匹配
在正则表达式中,如果直接给出字符,则为精确匹配。
(1) 数字和字符
用'\d'可以匹配一个数字,用'\w' 可以匹配一个字符(包括数字)。例如:'11\d'可匹配'114',但不能匹配 '11A' '\d\d\d' 可匹配 '021' '\w\w\d' 可匹配 'sp3'(2) 任意单个字符
用'.'可以匹配任意单个字符,例如:'py.'可以匹配'py2'、'py3'、'py!'等。
(3) 多个字符
用'*'表示任意个字符(包括0个),用'+'表示至少1个字符,用'?'表示0个或1个字符,用 '{n}'表示n个字符,用'{n,m}'表示n-m个字符,例如,在正则表达式'd{3}\s+\d{3,8}'中,'\d{3}'匹配3位数字,'\s'匹配一个空格,而'\s+'表示至少有一个空格(包括制表位空格),'\d{3,8}'表示3~8位数字。这样,该正则表达式即可匹配带区号并以任意个空格隔开的电话号码。
(4) 字符范围
用'[ ]'表示字符范围,1组方括号只能表示1个字符,例如,'[0-9a-zA-Z_]'可匹配1个数字、字母或下划线。'P|p'可匹配'P'或'p','[P|p]ython'可匹配'Python'或'python'。
(5) 开头和结尾
用'^'表示行的开头,用'^\d'表示必须以数字开头。用'$'表示行的结束,用'\d$'表示必须以数字结束。例如:'py'可以匹配'python',但加上表示开头和结尾的符号,'^py$'就只能匹配整行完整的'py',而对于'python'则无法匹配了。
(6) 特殊字符
特殊字符通常指非字母、非数字字符。例如,换行符'\n'回车符'\r'、空白符'\s'、制表符'\t'等。为避免与语法表达式中的符号的歧义,要用''转义或加r前缀统一转义。建议使用r前缀,就可以不用考虑转义的问题了。例如常见的用'-'隔开区号的电话号码,可以用正则表达式'\d{3}-\d{3,8}'匹配。
(7) 汉字
匹配汉字的正则表达式为:'[\u4e00-\u9fa5]'。支持Unicode编码的系统中,也可以用汉字精确的匹配。 1.2、贪婪匹配
贪婪匹配是一种尽可能多地匹配字符的匹配模式。例如:'[0-9a-zA-Z]+'可匹配至少一个数字、字母或者下划线组成的字符串,如:'a'、'0_9'、'name'等。
贪婪匹配是正则表达式默认的匹配方式,但在实际应用中有时并不能满足精准匹配需求。
用'?'可将前面的字符匹配从贪婪匹配转变为精准匹配,即尽可能减少重复匹配。'{m,n}?'表示对前一个字符重复m~n次,并且取尽可能少重复。例如:在匹配字符串'aaaaaa'时,'a{2,4}'取上限可匹配4个'a',但'a{2,4}?'取下限只匹配两个'a'。
-
-
二、re模块的内置函数
Python处理正则表达式的标准库是re。使用re的一般顺序是,首先用import re 引用,然后用 re.compile()函数将正则表达式字符串编译成正则表达式对象,再利用re提供的内置函数对字符串进行匹配、搜索、替换 、切分和分组等操作。re.compile()函数通常包括pattern(正则表达式)和flag(匹配模式,可选)参数。
flag的常见取值如下:
re.I:忽略大小写
re.L:使用当前本地化语言字符集中定义的\w、\W、\b、\B、\s、\S(用于多语言操作系统)。
re.M:多行模式,使'^'和'$'作用于每行的开始和结尾。
re.S:用'.'所匹配的任意字符包括换行符。
re.U: 使用Unicode字符集中定义的\w、\W、\b、\B、\s、\S、\d、\D。
re.X:忽略空格,并允许用'#'添加注释。
例如,创建正则表达式对象p:p = re.compile('''[0-9a-zA-Z\_] # 匹配1个数字、字母或下划线 AA? # 后面跟A或AA (0*)$ # 由若干个0结尾 ''',re.I|re.X) # 忽略大小写、忽略空格并允许当中整行加注释-
2.1、匹配与搜索
匹配与搜索函数常有match()、search()和findall(),它们的作用和用法相似,通常有两种使用方法。
(1)、作为正则表达式编译对象p的方法使用:p.match(string[,pos[endpos]]) search(string[,pos[endpos]]) findall(string[,pos[endpos]])若非指定,则pos和endpos的默认值分别为0和len(string),即从头到尾。
(2)、不使用正则表达式编译对象而直接调用:p.match(pattern,string[,flag]) search(pattern,string[, flag]) findall(pattern,string[, flag])上面三个方法若没有成功匹配均返回None,所不同的是,match()用于起始位置匹配,search()搜索整个字符串的所有匹配,若成功匹配则用 span()方法返回匹配起始和终止位置元组,findall()以列表形式返回全部能匹配的字串。
例如:re.match('abc','abcdef')匹配成功,如果用re.match('abc','abcdef').span() 可返回位置元组(0,3),而re.match('abc','xyzabcdef')则不能匹配成功,返回 none,导致span()报错。
而re.serch('abc','abcdef')和re.serch('abc','xyzabcdef')均能匹配成功,用span()方法可分别返回(0,3)和(3,6)。
最后:re.findall('abc','xyzabcxyzabc.abc')的返回结果为['abc','abc','abc']。
例如:假定某 E-mail 地址由三部分构成:英文字母或数字(110个字符)、“@”、英文字母或数字(110个字符)、“.”,最后以com或org结束,其正则表达式为:^[a-zA-Z0-9]{1,10}@[a-zA-Z0-9]{1,10}.(com|org)$。输入E-mail地址的测试字符串,忽略大小写,输出判断是否符合设定的规则。import re p = re.compile('^[a-zA-Z0-9]{1,10}@[a-zA-Z0-9]{1,10}.(com|org)$',re.I) while True: s=input("请输入测试E-mail地址(输入 '0' 退出程序): \n") if s=='0': break m=p.match(s) if m: print('%s 符合规则' %s) else: print('%s 不符合规则' %s) 下面是结果 请输入测试E-mail地址(输入 '0' 退出程序): [email protected] [email protected] 符合规则 请输入测试E-mail地址(输入 '0' 退出程序): [email protected] [email protected] 不符合规则 请输入测试E-mail地址(输入 '0' 退出程序): -
2.2、切分与分组
(1)、切分
在实际应用中,常遇到来自不同数据源用不同分割符号隔开的字符数据,隔开的符号可能是一个或多个空格、制表符、英文逗号、英文分号等,利用正则表达式和split()函数可将其方便地进行切分,并以字符串列表返回结果。其通式为:re.split(pattern,string[,maxsplit])其中,除前面已经出现的pattern和string外,可选参数maxsplit为最大切分次数。
例如:分隔符是一个或多个空格、制表符、英文逗号、英文分号的正则表达式为'[\s\t\,\;]+',测试字符串为“abc def,;123 456,xyz”,用re.split('[\s\t\,\;]+','abc def,;123 456,xyz')可返回列表['abc','def','123','456','xyz']。
(2)、分组
当正则表达式是由多个括号组合而成的符合形式时,用group()函数,可将 re.match()或re.search()函数成功匹配的返回对象按正则表达式的分组提取子字符串。例如,表示电话号码的正则表达式'^(\d{3})-(\d{3,8})$'由区号和本地号码两个分组组合而成,用group()可以直接从匹配的字符串中提取出区号和本地号码:m=re.search('^(\d{3})-(\d{3,8})$','021-81870936') m.group() # 返回匹配的字符串 '021-81870936' m.group(0) # 返回原始的字符串 '021-81870936' m.group(1) # 返回第1个字符串 '021' m.group(2) # 返回第2个字符串 '81870936' -
2.3、替换
用re库中的 sub() 和 subn()函数,可将正则表达式所匹配的字符串内容替换为指定字符串的内容,并返回替换后的字符串。这两个函数用法一样,只是sub()返回的是替换后的新字符串,而subn()是以元组类型返回新字符串和替换次数。通式如下:
re.sub(pattern,repl,string[,count,flags]) re.subn(pattern,repl,string[,count,flags])其中,repl 为拟替换字符串。
例子:用正则表达式将字符串 s 中连续的3位数字替换为“xxx”。import re p=re.compile('[\d]{3}') s='1234abcd123DFE22225BCDF' print(p.sub('xxx',s)) print(p.subn('xxx',s))其运行结果为:
xxx4abcdxxxDFExxx25BCDF ('xxx4abcdxxxDFExxx25BCDF', 3)
-
-
三、正则表达式的应用:简单爬虫
网络爬虫是指按照一定规则自动抓取网络信息的程序或脚本。运用Python的内置urllib库结合正则表达式应用,可简单实现对静态网页信息的自动下载。下面以自动抓取静态网页面:
http://www.lenovo.com.cn中的JPG图片素材为例进行说明。
用Safari浏览器访问该主页,右击选择下载文件链接,其中的图片素材是以:“_src="http://...//...//.../.jpg"”形式实现连接。下载好的文件链接我用Sublime打开的,内置的urllib库中的urllib。request.urlopen(url)函数可以实现对静态网页的访问,读取网页的html源码。根据网页所用的编码形式(如图上,本例为UTF-8)用decode()解码(本例为decode('UTF-8'))。
为实现自动爬取素材,根据源码中呈现的素材链接形式,形成素材链接的正则表达式reg=r'_src=".*?\.jpg'其中
'.*?'为非贪婪匹配的任意网址,只要以'_src='"开头、以'.jpg'"结束,就可以匹配。用imgre=re.compile(reg)生成正则表达式匹配对象,imgre=findall(html)可获取所有匹配的字符串的列表,调试的时候可以先用 print() 函数输出该列表进行尝试。用字符串切片(本例为url[6:-1])可获取JPG图片素材的完整链接。
用循环语句逐个通过 urllib.request.urlretrieve()函数下载图片素材,并自动编号保存在指定位置,如下:
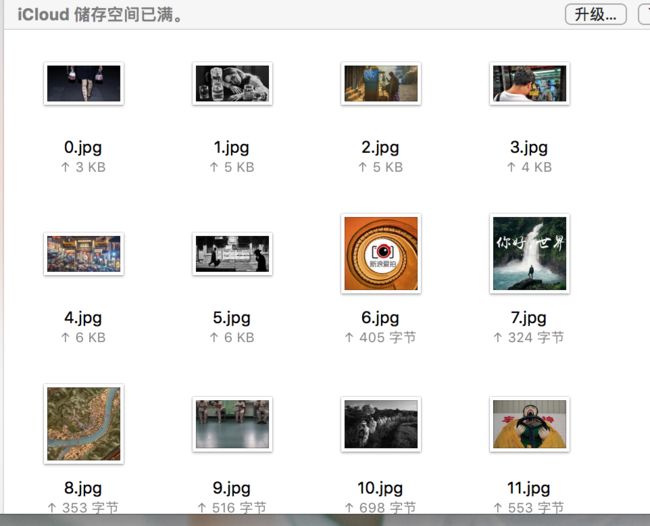 爬取图片素材结果
爬取图片素材结果import urllib.request import re def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html def getImg(html): reg = 'src="(.+?\.jpg)" alt=' imgre = re.compile(reg) # 将html编码转换成UTF-8,不然会出错 html = html.decode('utf-8') imglist = re.findall(imgre, html) x = 0 for imgurl in imglist: urllib.request.urlretrieve(imgurl, '/Users/wangchong/Desktop/newImage/%s.jpg'%x) x += 1 return imglist html = getHtml("http://photo.sina.com.cn") # https://www.lenovo.com.cn # http://photo.sina.com.cn print(getImg(html))需要说明的是,这里所介绍的简单爬虫只是利用正则表达式的一个简单的应用,只适用于直接静态网页。而对于转移 URL的网页、地址中带有中文的网页、检测浏览器类型的网页和网页动态等复杂爬取需求,要进一步深入应用 Python的urllib等库方可实现。