DiDi Food中的智能补贴实战漫谈

桔妹导读:随着因果推断理论体系(Casual Inference)的建立和补充,智能营销/智能补贴近年来在业界有了越来越多的落地成果。滴滴的国际化外卖团队DiDi Food自2020年上半年起开始推进了智能补贴算法在业务场景内的实验和落地,离线和线上效果均取得了一定进展。本文将主要介绍DiDi Food对这个方向上一些探索和实践经验。
0.
目录

本文内容较长,主要会包括以下几点:
1. 差异化定价的经济学原理
2. 差异化定价在DiDi Food中的抓手
3. 补贴问题的定义
4. DiDi Food中智能补贴的架构与流程
5. 增量预估
6. 分发策略
7. 实验效果
8. 未来规划
9. 自问自答
1.
差异化定价的经济学原理
提起营销手段,第一个想到总会是差异化定价。而提起差异化定价,人们的第一印象往往是价格歧视等类似的负面印象。其实,差异化定价的本质还是在为消费者,用户和社会创造更多的价值。这背后是有着一套在收益管理学(Revenue Management)下最直观明了的经济学原理的。

举个例子,图中所示为某商品需求(Demand)随价格(Price)变化的趋势,其中该商品的成本为$5。简单计算可以得知在单一定价下,图中:
A:所示面积即为总利润
B:所示面积为消费者剩余(Consumer Surplus)
C:所示面积即为潜在收益空间
这里的消费者剩余是一个经济学上的概念,简单理解为消费者对于商品的价值评估减去商品价格,比如,一份黄焖鸡米饭,我认为它值20块钱,而它的标价是15块钱,那么20-15=5元就是消费者剩余。经济学中,一次交易只有在消费者剩余>=0的情况下才会发生。这里更深层的理解我们不去深究,简单一点我们可以将消费者剩余理解为游戏中的快乐度。一次交易中的消费者剩余越大,消费者对本次消费行为就容易觉得满意和高兴。从这个角度出发,消费者剩余本身也是商品交易行为为社会创造的价值的一部分。
那么当我们对该商品进行差异化定价,即增加了一个新的定价$7后,
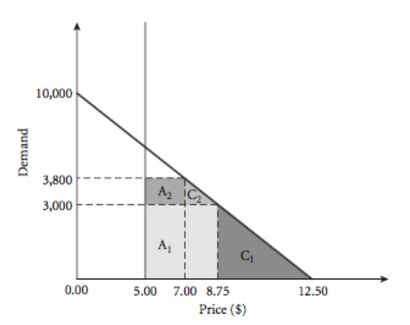
A2:所示面积即为增加的总利润
C2:所示面积即为增加的消费者剩余
通过差异化定价,整个交易的总利润(A1+A2>A)增加了,企业和平台可以利用多出的总利润提升自己的产品与服务质量,为用户创造更多的价值。与此同时,更多的用户买到了商品,享受到了服务,整个交易的消费者剩余(C1+C2>B)也增加了。
而这,也恰恰是对差异化定价产生的社会价值最直观的解释。
2.
差异化定价在DiDi Food中的抓手
DiDi Food作为国际化外卖平台,其用户面对的商品定价更多层面上是一系列服务和商品的综合定价:
P=Pi+Pd−Subsidyc
其中,Pi为菜品标价,Pd为配送费,Subsidyc为C侧补贴
这也为我们在商户侧(B),用户侧(C),骑手侧(D)三端进行差异化定价提供了抓手。

可以看到,在B侧,由于平台侧不可能拥有菜品的定价权,我们的差异化定价的选择相对比较单一并且过于间接,而且在本质上也无法达到差异化定价的目的。而在D侧,配送费的动态定价除了可以帮助平台调节供需外,其本身无疑也是一个比较有力的差异化定价的手段。但是它的使用却有着显而易见的约束,比如为了避免在配送费定价的时候产生所谓的“大数据杀熟”,我们一般不会使用用户维度的特征,而且在每一次动态调节的背后,都会有相应的价格Buffer层做调价缓冲。
因此,相对于B侧的间接影响和D侧的诸多约束,通过对用户发券进行补贴无疑是一种更为直接和更为有效的差异化定价手段。
3.
补贴问题的定义
与机器学习传统三大方向【推荐,搜索,广告】不同,补贴问题中最核心和最关键的一点是补贴这个行为需要付出【成本】。这个概念的引入使得我们必须要将对这部分【成本】的使用效率作为一个核心指标,也就是所谓的「ROI」。

也就是衡量增加的补贴【成本】所带来【增量】指标收益。
对于这个指标的优化,一个直观的解法就是随机AB实验,通过足够多的,设计逻辑严密的,随机性完美的AB实验,我们一定可以在这个指标的优化上取得令人满意的结果。但是这个方法在具体业务中的问题是它太过于奢侈了,无论是在预算还是在时间上。
因此,为了可以高效低廉地求解这个问题,我们可以将优化目标拆解为两个子问题:
预估干预的Action相比于没有干预时带来的【增量】
在存在多种干预【Action】和已预估了它们【增量】的情况下,如何为每个用户合理分配【Action】以期望达到全局最优
对于问题a:
与传统机器学习解决的问题不同,子问题a所面临的一个终极难题是,我们想要预估的这个【增量】在观察数据中是没有真值的。如果是一条被干预后的样本,我们只能观察到它被干预后的指标而无从得知它不被干预时的指标。同样,如果是一条未被干预的样本,在观察数据中我们也无法得知它被干预后的表现是怎样的。这也正是在因果推断理论中因果关系阶梯的第三层所提到【反事实 (Counterfactuals)】。而对这个“增量“预估的问题,业界也提出不少了的解法,我们会在之后尝试做出更详细的介绍。
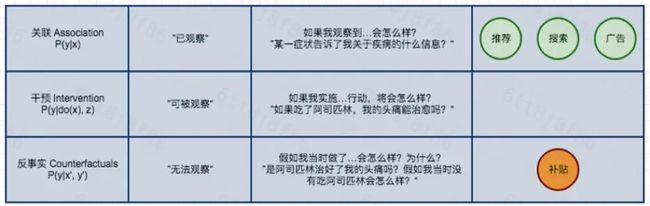
对于问题b:
熟悉运筹相关知识的同学很容易就可以看出这是一个比较经典的,在约束下求解全局最优的问题。从整数规划到Exploit&Explore到强化学习,在这个问题下可以探索的方向也有很多。这里也会在后面给出我们的一些实践。
4.
DiDi Food中智能补贴的架构与流程
在DiDi Food中,与智能补贴相关的工程架构如图:
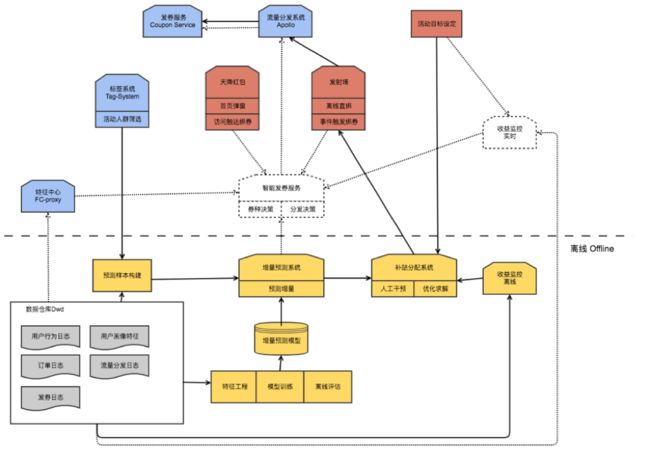
其中,虚线部分为正在规划和开发中的线上智能决策模块。而【增量预测】和【补贴分配】则是这个框架中最核心的部分,分别用于解决上面所拆分出的子问题a和b。
对于【增量预测】模块中使用的模型,更细节的训练和更新流程如下:
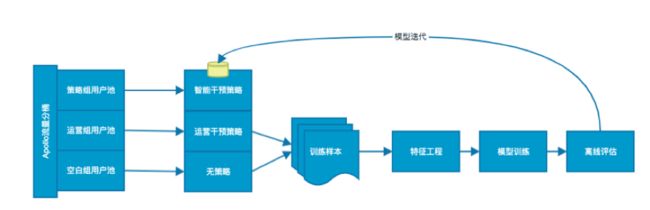
其中,在特征筛选方面:
由于我们所使用的部分候选模型并非是直接对【增量】进行建模,而是使用多种模型间接地近似这个【增量】。因此,我们无法如一般线性或者树模型一样直接产出所有特征对于最终输出【增量】的重要度。我们在实践中使用的方法是用一个新的LightGBM去拟合离线评估最优模型产出的【预测增量】,并用这个新模型的特征重要度来近似评估各个维度特征的重要性,以此来决策是否加入和剔除特征。选择LightGBM的原因是我们对于这个模型的精度并没有太高的要求,相反我们希望它能够比较快速地在训练流程中对新加入特征的给出反馈。LightGBM高效地训练速度和不需要过多特征工程的优点比较契合我们的需求。
另外,在样本构建方面,
从流程图中可以看到,在构建训练样本和离线评估测试样本时,我们剔除了那些被线上模型干预后的样本。
这是因为在理论上,我们是在三个假设的前提下去使用模型拟合一个在观察数据中并不存在的【增量】的。

其中,针对其中第二条假设,我们的个人理解是我们虽然允许有影响分配机制的特征存在,但是我们需要将这些特征也纳入我们的观察。在模型干预的数据样本中,影响干预分配机制的往往是模型产出的【预测增量】。这个特征我们没有也无法将其纳入我们的观察。因此,我们将这部分样本从训练和测试样本中剔除了。
这点在数据结果上也可以看出,对于同一个批次的样本,同一套参数同一套模型,评估样本中【干预后样本】的存在会导致离线评估的结果大相径庭,从而影响我们离线评估和判断模型优劣。
另外在同一个测试样本上,有该类【干预后样本】样本参与训练的模型的离线效果也出现了比较明显的下降。
*离线评估指标为AUUC,其介绍将会在后面给出
同样模型,评估样本中有无干预样本:


同样测试集,干预样本是否参与训练:

我们将在下一部分详细介绍增量预估中所使用的算法。
5.
增量预估
在营销补贴活动中,我们常常使用模型预测用户在有补贴下的交易意愿,并对交易意愿强的用户发放补贴,以促进用户完成交易行为。这中间,我们往往会忽略一个重要的问题,即用户在无补贴下的交易意愿。在有成本的补贴活动中,我们希望把补贴发给补贴敏感的用户,即我们希望发放的补贴能够真正撬动了原本不会产生交易行为的用户,从而达到差异化定价的目的。那么,在此基础上,我们可以根据用户是否有补贴和是否下单,将其划分为四种人群:
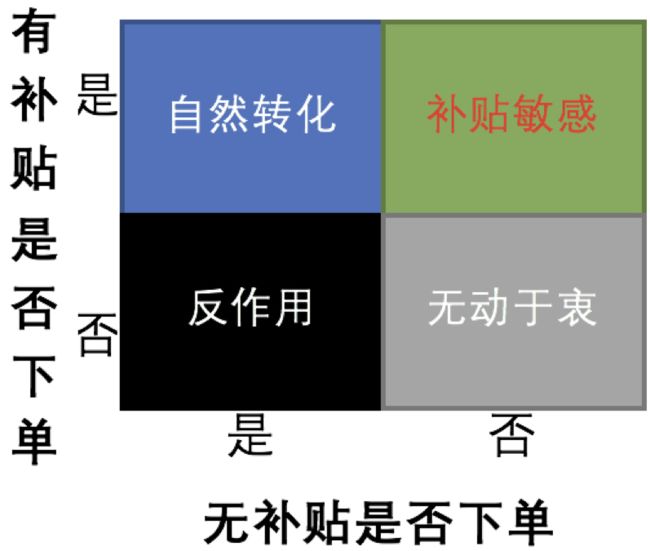
补贴敏感:
没有补贴就不下单,有补贴才会下单;补贴敏感人群。
自然转化:
有没有补贴都会下单;自然转化人群。
无动于衷:
有没有补贴都不会下单;
反作用:
无补贴时会下单,有补贴时反而不会下单;补贴活动带来反作用。
如之前所述,在补贴活动中,我们希望只触达【补贴敏感人群】。传统模型只预测交易意愿,无法预测因为补贴活动提升的交易意愿,也就无法很好的区分开来四种人群。为了能够获取因为补贴活动提升的交易意愿,我们引入了 Uplift Model。
Uplift Model 是对某种干预带来的【增量(Uplift)】进行建模的方法;它主要用于去预测补贴活动提升的交易意愿,也即前文描述的【增量(Uplift)】,并通过预测的结果去识别哪些用户能够真正为补贴活动所撬动。
设 W=1 表示有补贴,W=0表示无补贴,X 表示用户,Y=1 表示购买。则 Uplift Model 可表示为:
补贴活动提升的购买意愿 = P(Y = 1|X,W = 1) − P(Y = 1|X,W = 0)
根据其实现方法可分为两大类:Meta-Leaner 和 Tree-Base。
Meta-Learner 是基于传统分类和回归算法组合建模,间接去预测增量;常见的 Meta-Learn 算法有 Two Model(T-Learner),Single Model(S-Learner) ,X-Learner和R-Learner 等。
Tree-Base 则是通过树模型中节点分裂的算法思想,尝试去直接对增量建模,预测增量。
在下面的介绍中,![]() ,
,![]() 将分别表示对照组样本特征和 Label;
将分别表示对照组样本特征和 Label;![]() ,
,![]() 表示实验组样本特征和 Label。W ∈ {0, 1} 则表示用户是否属于实验组。
表示实验组样本特征和 Label。W ∈ {0, 1} 则表示用户是否属于实验组。
▍5.1 Meta-Learner
如同前面介绍的那样,Meta-Learn体系内的模型主要思想都是想通过一系列的基模型(base-learner)的组合,去近似拟合一个无法被观测到的【增量(Uplift)】。我们这里将会介绍主流的四个模型,Two-Model,Single-Model,X-Learner和R-Learner。
5.1.1 Two Model
Two Model 算法也称为差分模型,顾名思义就是利用两个模型的差值去近似用户的增量。这也是最符合直觉的一种思路。
具体模型构造流程是:
(1) 对实验组数据和对照组数据分别建立模型

(2) 用实验组模型 预测值减去对照组模型
预测值减去对照组模型 预测值去近似增量
预测值去近似增量
![]()
优点:
– 简单直观,易实现。
– 可直接使用现有分类算法。
缺点:
– 双模型存在误差累加。
– 间接计算增量,无法对模型进行优化。
5.1.2 Single Model
Single Model将与干预手段W有关的特征加入训练,只建立一个模型。这样做的好处是,相较于Two Model,我们可以减少模型较多带来的误差累加。
具体模型构造流程是:
(1) 在实验组和对照组样本特征中加入 W 有关的特征,将实验组和对照组的样本特征、Label 合并,训练一个模型![]() .
.
(2) 通过对用户W 特征赋值W=1和W=0计算用户增量![]() :
:

与 Two Model 相比,Single-Model也可以直接使用现有分类算法,同时也减少了 Two Model 带来的误差累积问题;另外,由于它利用了全量数据训练模型,因此也进一步提高了模型的泛化能力。但是,它依然是对增量间接建模,无法根据增量优化模型,并且也同样存在着模型精度问题。
优点:
– 简单直观,易实现。
– 可直接使用现有分类算法。
– 减少双模型误差累加。
– 训练样本增加,提高模型精度。
缺点:
– 间接计算增量,无法根据增量对模型进行优化.
5.1.3 X-Learner
X-Learner算法是在Two Model模型基础上提出的,基于利用观察到的样本结果去预估未观察到的样本结果的思想,对增量进行近似,同时还会对结果进行倾向性权重调整,以达到优化近似结果的目的。
具体模型构造流程是:
(1) 对实验组和对照组分别建立两个模型 和
和 :
:
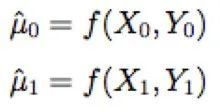
(2) 利用实验组模型预测对照组样本在实验组的转化率![]()
![]() 减去对照组Label
减去对照组Label![]() 得到对照组近似增量
得到对照组近似增量![]() ;
;
利用对照组模型![]() 预测实验组样本在对照组的转化率
预测实验组样本在对照组的转化率 实验组 Label
实验组 Label![]() 减去
减去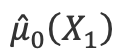 得到实验组近似增量
得到实验组近似增量![]() 。
。

(3) 对求得的实验组和对照组增量D1和D0建立两个模型![]() 和
和![]() 。
。
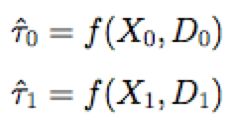
(4) 引入倾向性得分模型 e(x) 对结果进行加权,求得增量。
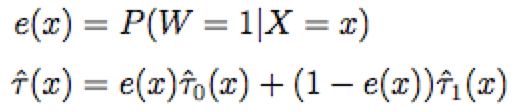
算法的优点之一是在步骤(3)中,我们得到了两个近似的增量值,并直接对其建模。如果我们本身对业务有足够的了解,知道增量的一些相关先验知识(线性/非线性等),那么这些先验知识是可以参与建模过程并帮助我们提升模型精度的。与此同时,在理论上,它也解决了对照组和实验组样本差别较大场景下预测增量精度问题,但它并没有说明多大差别才适用X-Learner,我们在实际应用中的离线评估部分,X-Learner虽然偶尔表现优异,但并没有持续显著优于其他模型。
优点:
–适合实验组和对照组样本数量差别较大场景。
– 对于增量的先验知识可以参与建模,并且引入权重系数,减少误差。
缺点:
– 多模型造成误差累加。
5.1.4 R-Learner
R Learner 算法思想不同于Two、Single和X-Learner。其核心思想是通过 Robinson’s transfomation 定义一个损失函数,然后通过最小化损失函数的方法达到对增量进行建模的目的。
(1) 训练倾向性得分模型 e(x)

(2) 通过CV方式对Label Y的期望m*建模
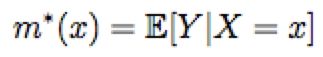
(3) 通过求得的e(x)和m*(x),优化如下损失函数
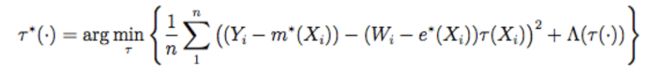
这一部分在实现时,我们可以看成是用带权重的X去拟合
 ,
,
训练中Xi的权重为

优点:
– 灵活且易于使用。
– 损失函数可以接深度网络等。
缺点:
– 模型精度依赖于m*(x), e*(x)的精度。
▍5.2 Tree-Based Model
传统机器学习模型中,树模型主要的思路就是通过对特征点进行分裂,将X划分到一个又一个subspace中,这与补贴场景下,希望找到某一小部分增量很高的用户的想法几乎是完美重合。因此,与meta-learner不同的是,uplift model下的树模型希望通过这样的分裂方式达到对增量直接建模的目的。

传统分类树模型是希望通过信息理论(information theory)中的信息熵等思想,用计算信息增益的方法去解决分类问题。而在uplift tree model中,其本质也还是想要通过衡量分裂前后的变量差值去决策是否分裂节点,不过这里的这个决策差值的计算方法不再是信息增益(information gain),而是不同的直接对增量uplift建模的计算方法,其中包括了利用分布散度对uplift建模和直接对uplift建模。
5.2.1 分布散度下的uplift tree
分布散度是用来度量两个概率分布之间差异性的值,当两个分布相同时,两个离散分布的散度为非负且等于零。我们可以把实验组和对照组理解为两个概率分布,然后利用分布散度作为非叶节点分裂标准,最大化实验组和对照组的样本类别分布之间的差异,减少样本不确定度。常见的分布散度有KL 散度 (Kullback-Leibler divergence)、欧式距离 (Squared Euclidean distance) 和卡方散度(Chi-squared divergence),在uplift model中,其具体计算方法如下:

除此以外,分布散度还有个特点:通过公式可以推导,当结点中对照组数据为空时,KL散度会退化为决策树分裂准则中的信息增益;欧式距离和卡方散度将会退化为基尼指数。而当结点中实验组数据为空时,欧式距离将会化为基尼指数。这也是该类分裂准则的优点之一。
其模型主要构造流程为:

算法的部分可能比较晦涩,我们可以举个例子简单描述这里所谓的分布散度的计算方法:

5.2.2对uplift直接建模的CTS Tree
MIT的Zhao Yan 等人在2017年提出了一种新的名为CTS的分裂准则去构建Uplift Tree。CTS algorithm是Contextual Treatment Selection的缩写。不同于分布散度,在该标准下,我们会直接最大化每个节点上实验组和对照组之间label期望的差值(可以理解为该节点上样本的Uplift值),并以此来分裂节点。
CTS树具体构造流程为:

相比于meta-learner,uplift下树模型由于往往是直接对uplift进行建模和利用特征直接对人群进行切分,因此模型精度往往比较高一些。但是在实际应用中,还是需要要注意树模型的收敛性以及它的泛化能力。
▍5.3 Uplift Model 模型评估
常用分类和回归算法,可以通过 AUC、准确率和 RMSE 等去评估模型的好坏。而由于Uplift Model 中不可能同时观察到同一用户在不同干预策略下的响应,即无法获取用户真实增量, 我们也就无法直接利用上述评价指标去衡量模型的好坏。因此,Uplift Model 通常都是通过划分十分位数来对齐实验组和对照组数据,去进行间接评估。常用的评估方 法有 Qini 曲线、AUUC 等。
5.3.1 Qini curve
Qini 曲线是衡量 Uplift Model 精度方法之一,通过计算曲线下的面积,类似 AUC 来评价模型的好坏。其计算流程如下
(1) 在测试集上,将实验组和对照组分别按照模型预测出的增量由高到底排序,根据用户数量占实验组和对照组用户数量的比例,将实验组和对照组分别划分为十份,分别是 Top10%, 20%, . . . , 100%。
(2) 计算Top10%,20%,...,100%的Qini系数,生成Qini曲线数据(Top10%,Q(Top10%)),
(...,...), (Top100%, Q(Top100%))。Qini 系数定义如下:

可以看出,Qini 系数分母是实验组和对照组的总样本量,如果实验组和对照组用户数量差别比较大,结果将变得不可靠。
5.3.2 AUUC
AUUC(Area Under the Uplift Curve) 的计算流程与 Qini 曲线的计算流程一样,计算前 10%、20%、. . . 、100% 的指标,绘制曲线,然后求曲线下的面积,衡量模型的好坏。不同是 AUUC 指标计算方法与 Qini 指标计算不同,AUUC 指标定义如下:

与 Qini 指标含义相同,当 i 取10% 时,![]() 表示实验组前 10% 用户数量,
表示实验组前 10% 用户数量,![]() 表示对照组前 10% 用户数量。可以看出,AUUC 指标计算方法可以避免实验组和对照组用户数量差别较大导致的指标不可靠问题。
表示对照组前 10% 用户数量。可以看出,AUUC 指标计算方法可以避免实验组和对照组用户数量差别较大导致的指标不可靠问题。
值得注意的是,当分桶时,对照组边界点预估出的增量与实验组边界点的预估值有较大差别时候,以上的两个评估指标似乎都显得不那么可靠了。因此在实际中,我们使用的往往是AUUC 另外的一种计算方法。

6.
分发策略
对增量预估完毕后,接下来就需要具体地为用户池中用户分配补贴券。在基于增量预估的基础上,我们尝试了两种分发策略:
▍6.1 贪心分配
很多时候,运营对于使用的券类别和每个券类别的预算分配都有比较大的限制和约束。在这样的约束下,我们的做法是按照券值面额从低到高,为每个券类别计算可支配数量,然后对用户池所有用户按照预估出的Uplift值和计算出的可发放数量倒排截断,并将分配完毕的用户从备选用户池中移除。这样一个用户如果在各种券类别下uplift都很高时,我们将会优先为他/她配置券值较低的补贴券。这样做法的好处是简洁明了实现简单,在人工干预较强的时候对于运营的可解释性也比较强。缺点当然就是在自由度更高情况下,显然不能达到全局最优。
▍6.2 整数规划
而当我们对于预算和券种的设置拥有了更多的自主权时,我们也尝试了在预算约束下的最大化求解,具体的求解公式如下:

可以看到,这是一个典型的整数规划求解问题。由于目前我们单次求解用户量级基本上还是在百万量级上,因此这个模块在线下的求解时间依然可控,相信随着业务更多的拓展,我们面临的最大挑战是还是在可控时间对这个公式的求解。
7.
实验效果
模型上线之后,我们在DiDi Food业务内两个不同的城市进行了不同目标约束下的AB实验,实验所有组别基于的用户群筛选条件一致,并经过Didi流量分发平台随机进入不同组别。空白组为实验期间不会受到干预的用户池,运营组为在实验期间由运营人工策略干预的用户池,策略组为实验期间策略模型分配干预的用户池。其中,空白组的存在主要是为了另外两组补贴策略计算ROI提供Base数据。
实验的主要目标分为两个方向,分别为与运营组人工策略相比,模型干预策略需要达到:
相同单量,更少补贴
相同补贴,更多单量
主要评价指标为:
ROI

补贴金额
单量

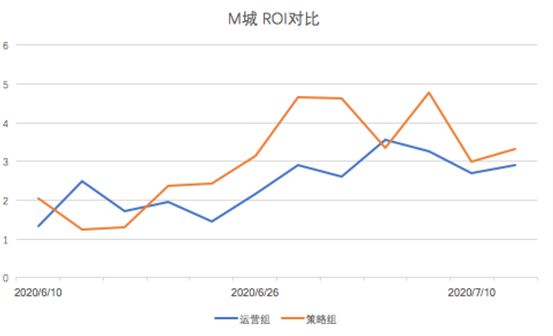

可以看出,模型干预策略相比线上baseline,各项指标均有显著优化。在目标【相同单量,更少补贴】下,它确实以单量的略微下降换来了补贴的大幅下降。而在目标【相同补贴,更多单量】下,我们补贴相差无几的同时,单量得到了大幅的提升。
8.
未来规划
我们在20年下半年的规划主要有4个方向:
如架构图中所说,我们会把离线的决策模块部分推至线上并引入更多的实时特征和接入更多的发券场景(首页天降红包,进店未下单等等),并将其直接包装为一个简单可解释的运营工具,使其能够提高Local运营效率的同时,解放运营在活动配置上消耗的时间和心力。
在增量预估模块,我们会持续迭代优化模型。在尝试引入更多维度,信息更丰富的特征的同时,与深度学习模型融合,提高模型精度。
在分配决策模块,我们会优化整数规划的求解速度并调研和尝试在这个方向上与强化学习理论结合的可能性。
当前框架下的算法策略几乎只是针对每一次活动希望求得全局的最优化。而在实际运营中,一个健康的补贴生态一定是去优化用户在其整个生命周期的收益的,所以对用户长期价值(LTV)的建模也是个值得规划和探索的方向。
9.
Q&A
▍Q1. 如何正确理解线上的业务指标ROI?
在解决补贴问题时,时常会困惑如何能合理地解释策略干预的结果,尤其是在与前线运营同学交流的时候。ROI固然是正确且合理的指标,但是我们可以设想这样一个场景,客单价为100,空白组GMV为1000,补贴为0,策略组发放了一个抵扣面额为10的券,最终核销了2张,GMV为1200,补贴为20。那么通过ROI计算公式可得,策略组ROI为200/20=10。与此同时,运营同学发放了一个抵扣面额为20的券,最终核销了10张,GMV为1800,补贴为200,那么运营组的ROI就是800/200=4。从钱效角度出发,当然是策略组干预策略更优秀,但是对于运营同学而言,这次活动确实是他们的策略带来了更多的GMV和单量。

而且,运营同学会自然想到的一个原因是因为策略组使用的券种抵扣额度更低,所以ROI会更高,而一旦有了这样的思路,整个过程就不可避免的走向了设计更为复杂且需要运营侧策略侧高度配合的实验。这与我们想高效低廉的解决这个问题就完全背道而驰了。
因此,我们在这个问题上最后的结论是,ROI是一个非常优秀的业务指标,但为了保证策略的可解释性,它不能作为唯一指标。我们锚定了运营同学更为关注的直接指标【规模:GMV,单量】【成本:补贴】,并通过加入约束条件和人工干预的手段,使其中一个维度与运营组策略对齐的同时,观察另一维度指标的提升,也既前面提到了两个大的目标方向【相同单量,更少补贴】和【相同补贴,更多单量】。也就是说,我们只会在【相同补贴】或者【相同单量/GMV】这样的条件下,才去谈论ROI。也只有在这样的情况下,ROI这个指标的说服力才会显得更加强大。
▍Q2. 如何理解离线指标AUUC?
AUUC是一个很重要且奇怪的指标。说重要,是因为它几乎是Uplift Model在离线阶段唯一一个直观的,可解释的评估模型优劣的指标。说奇怪,是因为它虽然本质上似乎借鉴了分类模型评价指标AUC的一些思想,但是习惯了AUC的算法工程师们在初次接触的时候一定会被它搞得有点迷糊。
作为在分类模型评估上的标杆,AUC的优秀不用过多赘述。其中最优秀的一点是它的评价结果稳定到可以超越模型和样本本身而成立,只要是分类问题,AUC0.5是随机线,0.6的模型还需要迭代一下找找提升的空间,0.6-0.8是模型上线的标准,而0.9以上的模型就需要考虑一下模型是否过拟合和是否有未知强相关特征参与了模型训练。一法抵万法,我们可以抛开特征,样本和模型构建的细节而直接套用这套准则。
然而这个特点对于AUUC就完全是奢望了。通过AUUC的公式可以看出,AUUC最终形成的指标的绝对值大小是取决于样本的大小的。也就是说,在一套测试样本上,我们的AUUC可能是0到1W,而换了一套样本,这个值可能就变成了0到100W。这使得不同测试样本之间模型的评估变为了不可能。也使得每次模型离线的迭代的前提必须是所有模型都使用同一套测试样本。当我们训练完一个新的模型,跑出一个40万的auuc,我们完全无从得知这个值背后代表着模型精度如何,我们只能拿出旧的模型在同样测试集上跑出auuc然后相互比较。这无疑让整个训练迭代过程变得更痛苦了一点。
我们也尝试了从多个角度去解决这个问题,希望在增量预估模型中建立一套类似auc的标准,但无一例外都没能成功。包括像AUC那样除以曲线的理论最大面积,但是看公式就可以知道,这个理论的最大面积其实就是样本个数的平方而这么一除之后得到的AUUC也失去了比较的价值了。
如图所示,即使不是理论的最大面积而是样本排序最优组合的最大面积,也依然超出了衡量的价值。


我们还尝试过使用AUC的近似计算方法(Pairwise)去近似计算AUUC,得到的结果虽然确保了在0-1区间内的离散性但仍然无法保证在所有情况下,他得出的模型优劣顺序与AUUC本身保持一致。
最后,我们也只能用“补贴问题本身就是与实验批次和样本强相关的问题”这个理由盖过对这个问题的纠结。但能否在增量预估模型中建立一套类似auc的标准,我们仍然认为这个问题是值得投入一点心力去探索的方向。
以上就是智能补贴算法在DiDi Food海外业务的一些介绍和实践总结,有任何问题欢迎随时联系我。
文献和其他参考资料:
- Robert Phillips. "Pricing and Revenue Optimization", pp. 75–94
- Susan Athey and Guido W Imbens. “Machine learning methods for estimating heterogeneous causal effects”. In: stat 1050.5 (2015), pp. 1–26.
- Donald P Green and Holger L Kern. “Modeling heterogeneous treatment effects in survey experiments withBayesian additive regression trees”. In: Public opinionquarterly 76.3 (2012), pp. 491–511.
- Pierre Gutierrez and Jean-Yves Gérardy. “Causal inference and uplift modelling: A review of the literature”. In: International Conference on Predictive Applications and APIs.2017, pp. 1–13.
- Behram Hansotia and Brad Rukstales. “Incremental value modeling”. In: Journal ofInteractive Marketing 16.3 (2002), p. 35.
- Sören R Künzel et al. “Metalearners for estimating heterogeneous treatment effects usingmachine learning”. In: Proceedings of the nationalacademy of sciences 116.10 (2019), pp. 4156–4165.
- Xinkun Nie and Stefan Wager. “Quasi-oracle estimation of heterogeneous treatment effects”. In: arXiv preprint arXiv:1712.04912 (2017).
- Piotr Rzepakowski and Szymon Jaroszewicz. “Decision trees for uplift modeling with single and multipletreatments”. In: Knowledge and Information Systems 32.2(2012), pp. 303–327.
- Yan Zhao, Xiao Fang, and David Simchi-Levi. “Uplift modeling with multiple treatments and general response types”. In: Proceedings of the 2017 SIAM International Conference on DataMining. SIAM. 2017, pp. 588–596.
- 滴滴AI说第35章,单明辉、杨晓庆:网约车精细化定价补贴介绍(二)
- 滴滴AI说第19章,汪飞:智能算法在补贴工具中的应用
团队介绍
▬
R lab 是滴滴17年底成立的一级部门,肩负不断探索滴滴边界孵化创新产品,R意为Rebuild,我们不创造用户需求,而通过独立思考,从第一性原理出发探究本质,重构一个个业务领域,创造新体验替换旧体验,为用户创造价值。目前主要业务为DiDi Food国际外卖业务及国内探索业务。目前DiDi Food业务已经开国墨西哥、巴西、日本,为当地用户提供优质服务。国内探索业务也在持续进行。
目前部门业务快速发展,急需各类人才,算法,服务端,测试,客户端,战略,产品,运营等,欢迎有兴趣的小伙伴加入。
投递简历至hr邮箱:[email protected]
作者介绍
▬
来自滴滴R-lab交易策略团队。主要负责DiDi Food智能增长算法策略和商户画像体系建设等相关工作。
来自滴滴R-lab交易策略团队。从事DiDi Food智能增长算法策略和商户画像等相关工作,负责用户增长模型建模,商户和菜品特征挖掘等相关项目的落地和优化。
延伸阅读
▬
内容编辑 | Charlotte & Teeo
联系我们 | [email protected]