小结
主要讲述pinterest在Related Pins这个场景的演进过程。pinterest的总保存RP占比从10%涨到了40%。Related Pins Save Propensity,是他们主要的优化目标。Related Pins leverages this human-curated content to provide personalized recommendations of pins based on a given query pin
系统总览
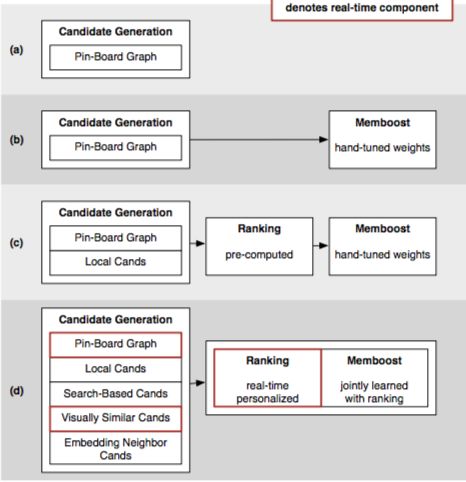
一共分为三块、候选产生、memboost和rank,注意看三者在系统中的先后顺序
- 候选
规模从10亿到1000 - memboost
memorizes past engagement on specific query and result pairs. -
rank
maximize our target engagement metric of Save Propensity
 图片.png
图片.png
候选演进过程
最早候选主要是基于pins在boards中的共现,后来引入memboost和ltr之后,候选的问题从precision慢慢往recall的方向靠拢,加入了更多新的候选来源
board共现
1)用mapreduce来计算两个pin在boards中的共现,同时基于分类和文本的匹配程度来进行相关性加权,有两个问题a)长尾问题;b)更多的依赖基础信息的相关性得分
2)随机游走Pixie。a)使用一些规则去掉了一些高相关和低相关的节点;b)参考了twitter的游走方法,超过10w次的随机游走的结果聚合,每次都重设概率
3)优缺点
优点是recall还不错,缺点1)board有时宽泛了,而且board的内容容易随着用户的兴趣转义而变化;2)board有时太狭义了,比如whiskey和cocktail有时候在不同的board中session共现
用户在时序上的行为串联可以解决board太宽泛和狭窄的问题
Pin2Vec is a learned embedding of the N most popular (head) pins in a d-dimensional space, with the goal of mini- mizing the distance between pins that are saved in the same session.
we consider pins that are saved by the same user within a certain time window to be related (保存行为而不是点击行为!!),it captures a large amount of user behavior in a compact vector representation.补充候选
为了解决两大问题:1)the cold start problem: rare pins do not have a lot of candidates because they do not appear on many boards.2)after we added ranking, we wanted to expand our candidate sets in the cases where diversity of results would lead to more engagement.
1)基于搜索的候选
We generate candidates by leveraging Pinterest’s text-based search, using the query pin’s annotations (words from the web link or description) as query tokens. Each popular search query is backed by a precomputed set of pins from Pinterest Search
2)视觉相似候选
a) If the query image is a near-duplicate, then we add the Related Pins recommendations for the duplicate image to the results.
b) use the Visual Search backend to return visually similar images, based on a nearest-neighbor lookup
- 区域候选
the content activation problem: rare pins do not show up as candidates because they do not appear on many boards.
we generate additional candidate sets segmented by locale for many of the above generation techniques
解决内容激活问题的方法还有gender-specific content or fresh content.
memboost演进过程
we built Memboost to memorize the best result pins for each query,Memboost as a whole introduces significant system com- plexity by adding feedback loops in the system。
1)使用clicks over expected clicks (COEC) 来解决位置和平台的偏差
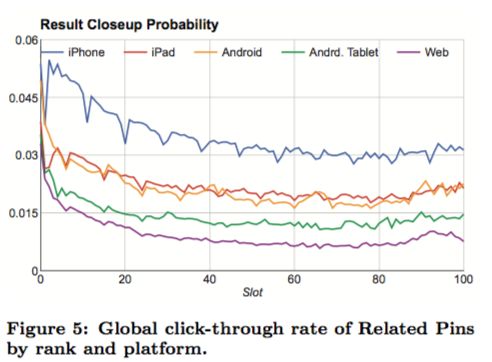
2)具体行为考虑到点击、长点击、关闭和保存,具体的计算方法为:
3)如果加入了new ranker或者时间推移或者系统改变,其实会对memboost这种历史累计的得分产生影响,解决方法是把memboost作为一个feature喂给ranker
4)memboost insertion主要是为了解决一些召回和排序不存在的优质内容进行回流
ranking演进过程
- 概览
假设ranking是未来最有可能提升效果的部分,第一个版本效果提升了30%。第一个版本只用了pin的原始数据,后面加上了Memboost and user data,包括用户的行为数据(最近搜索)。特征包括原始特征(主题、分类)、归一化特征(memboost)、one-hot编码特征、相关性特征(query和candidate的主题相关性)等等。
在实际线上使用中主要是有三个大的问题需要处理:
- 训练数据如何选择?用memboost分数还是独立session作为训练数据
- 学习目标用 pointwise 还是 pairwise?
- 模型类型用线性模型还是树模型
-
进化过程
 图片.png
图片.png
1). Memboost training data, relevance pair labels, pairwise loss, and linear RankSVM model
- pins (r1,rn),(rn,rrand) for each query, where r1,rn are the results with highest and lowest Memboost scores,
- respectively, for a given query. rrand is a randomly generated popular pin from Pinterest, added to stabilize the rankings, as suggested in [14].
- We reasoned that pins with low Memboost scores would still be more relevant than purely random pins
优点: - the training data was fairly clean
- we could use a much smaller corpus and train a model within minutes on a single machine.
缺点: - Memboost data inherently precludes personalization because it is aggregated over many users, losing the association with individual users and session context(很难模拟不同用户对结果不同的反应)
- only popular content had enough interaction for reliable Memboost data.
2). individual Related Pins sessions
logged session consists of the query pin, viewing user, and recent action context, and a list of result pins.
save > long click > click > closeup > impression only.
we trim the logged set of pins, taking each engaged pin as well as two pins immediately preceding it in rank order, under the assumption that the user probably saw the pins immediately preceding the pin they engaged with(只选连续出现的pair)
3). Moved to a RankNet GBDT Model
线性模型的缺点 - they force the score to depend linearly on each feature.
- cannot make use of features that only depend on the query and not the candidate pin, It is time consuming to engineer these feature crosses
树模型的优点 - allowing non-linear response to individual features,
- decision trees also inherently consider interactions between features, corresponding to the depth of the tree.
4). Moved to pointwise classification loss, binary labels, and logistic GBDT model - closeups and clicks seemed counterproductive since these actions may not reflect save propensity.
- We found that giving examples simple binary labels (“saved” or “not saved”) and reweighting positive examples to combat class imbalance proved effective at increasing save propensity.
- 模型偏差
the model that is currently deployed dramatically impacts the training examples produced for future models.
- the first ranking model, the logs reflected user’s engagement with results ranked only by the candidate generator
- Over the following months, the training data only reflected engagement with pins that were highly ranked by the existing model
- training pins no longer matched the distribution of pins ranked at serving time.
解决方法 - a small percentage of traffic for “unbiased data collection,show a random sample,randomly ordered without ranking,each user is served unranked pins on only a small random subset of queries.
- 成功的评测指标
迭代越快越好,线上的ab测试对于ranking的评价方法就是看保存率,但是online需要数天,所以离线测试就很重要了。
- sample individual Related Pins sessions, but choose a distinct range of dates that follows the training date range, and a slightly different sampling strategy
- For each session we rescore the pins that the user actually saw, using the models under test, then measure the agreement between the scores and the logged user behavior.
- We examined the directionality as well as the magnitude of the difference predicted by offline evaluation, and compared it to the actual experiment results.
- We found that PR AUC metrics are extremely predictive of closeups and clickthroughs in A/B experiments, but we had difficulty predicting the save behav- ior using offline evaluation
-
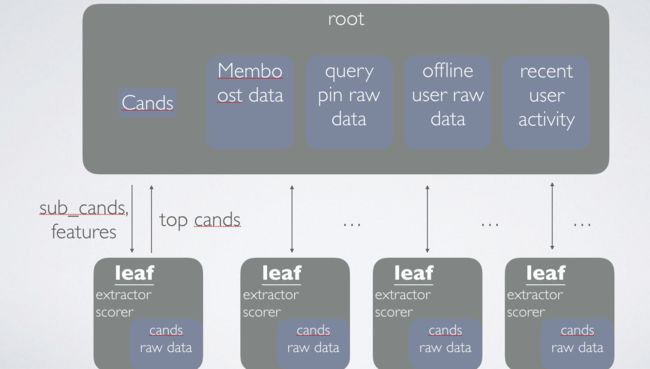
serving框架
离线与在线相结合
 图片.png
图片.png
ranking与memboost的关系
ranking和memboost理论上来说都是进行排序的,在pinterest的应用中,这俩模块也一直在。我们可以看到
- 第三阶段其实是ranking先pre-compute做一个粗排,然后用memboost进行微调(其实还有一种做法就是用memboost进行粗排再用ranking精排,不知道为什么pinterest为什么这么选择?)
- 第四阶段直接变成joint-learning了,memboost的分数变成了ranking的一个特征,进行联合训练。
挑战
- Changing Anything Changes Everything
inputs are never really independent,Improving another compo- nent may actually result in worse overall performance.
Our general solution is to jointly train/automate as much of the system as possible for each experiment.
- To avoid other changes resulting in hyperparameters becoming subop- timal, we implemented a parallelized system for automated hyperparameter tuning
- “Improvements” to the raw data can harm our results since our downstream model is trained on the old definition of the feature. Even if a bug is fixed
- changing or introducing a candidate generator can cause the ranker to become worse, since the training data distribution will no longer match the distribution of data ranked at serving time。Our current solution is to insert the new candidates into the training data collection for some time before running an experiment with a newly trained model.
- 内容冷启动
- We dive deeper into how we solved for content activation for the particular case of localization.
- SWAP:we check if there is a local alternative with the same image.
- BOOST: artificially promote them to a higher position in the result set.
- BLEND: producing a segmented corpus of pins for each language,blend local candidates into the results at various ratios.
TODO
pinterest的最新方向好像是GCN
参考资料和深入阅读
Pinterest推荐系统四年进化之路
Wtf: The who to follow service at twitter
Visual search at pinterest
Visual discovery at pinterest