HDFS分布式文件系统
Hadoop文件系统使用分布式文件系统设计开发。它是运行在普通硬件。不像其他的分布式系统,HDFS是高度容错以及使用低成本的硬件设计。
HDFS拥有超大型的数据量,并提供更轻松地访问。为了存储这些庞大的数据,这些文件都存储在多台机器。这些文件都存储以冗余的方式来拯救系统免受可能的数据损失,在发生故障时。 HDFS也使得可用于并行处理的应用程序。
HDFS的特点
- 它适用于在分布式存储和处理。
- Hadoop提供的命令接口与HDFS进行交互。
- 名称节点和数据节点的帮助用户内置的服务器能够轻松地检查集群的状态。
- 流式访问文件系统数据。
- HDFS提供了文件的权限和验证。
HDFS架构
下面给出是Hadoop的文件系统的体系结构。
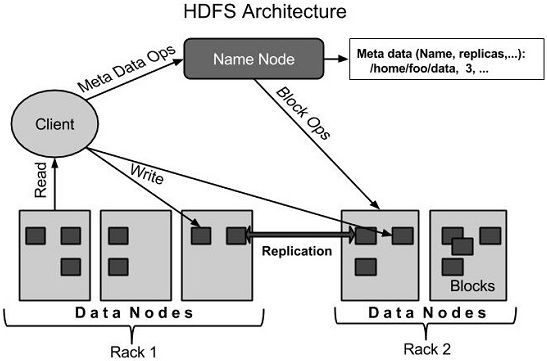
HDFS遵循主从架构,它具有以下元素。
名称节点 - Namenode
名称节点是包含GNU/Linux操作系统和软件名称节点的普通硬件。它是一个可以在商品硬件上运行的软件。具有名称节点系统作为主服务器,它执行以下任务:
- 管理文件系统命名空间。
- 规范客户端对文件的访问。
- 它也执行文件系统操作,如重命名,关闭和打开的文件和目录。
数据节点 - Datanode
Datanode具有GNU/Linux操作系统和软件Datanode的普通硬件。对于集群中的每个节点(普通硬件/系统),有一个数据节点。这些节点管理数据存储在它们的系统。
- 数据节点上的文件系统执行的读写操作,根据客户的请求。
- 还根据名称节点的指令执行操作,如块的创建,删除和复制。
块
一般用户数据存储在HDFS文件。在一个文件系统中的文件将被划分为一个或多个段和/或存储在个人数据的节点。这些文件段被称为块。换句话说,数据的HDFS可以读取或写入的最小量被称为一个块。缺省的块大小为64MB,但它可以增加按需要在HDFS配置来改变。
数据库备份
数据的备份类型根据其自身的特性主要分为以下几组
完全备份
部分备份
完全备份指的是备份整个数据集( 即整个数据库 )、部分备份指的是备份部分数据集(例如: 只备份一个表)
而部分备份又分为以下两种
增量备份
差异备份
增量备份指的是备份自上一次备份以来(增量或完全)以来变化的数据; 特点: 节约空间、还原麻烦
差异备份指的是备份自上一次完全备份以来变化的数据 特点: 浪费空间、还原比增量备份简单

MySQL备份数据的方式
在MySQl中我们备份数据一般有几种方式
热备份
温备份
冷备份
热备份指的是当数据库进行备份时, 数据库的读写操作均不是受影响
温备份指的是当数据库进行备份时, 数据库的读操作可以执行, 但是不能执行写操作
冷备份指的是当数据库进行备份时, 数据库不能进行读写操作, 即数据库要下线
MySQL中进行不同方式的备份还要考虑存储引擎是否支持
MyISAM
热备 ×
温备 √
冷备 √
InnoDB
热备 √
温备 √
冷备 √
我们在考虑完数据在备份时, 数据库的运行状态之后还需要考虑对于MySQL数据库中数据的备份方式
物理备份
逻辑备份
物理备份一般就是通过tar,cp等命令直接打包复制数据库的数据文件达到备份的效果
逻辑备份一般就是通过特定工具从数据库中导出数据并另存备份(逻辑备份会丢失数据精度)
备份需要考虑的问题
一般情况下, 我们需要备份的数据分为以下几种
数据
二进制日志, InnoDB事务日志
代码(存储过程、存储函数、触发器、事件调度器)
服务器配置文件
备份工具
这里我们列举出常用的几种备份工具
mysqldump : 逻辑备份工具, 适用于所有的存储引擎, 支持温备、完全备份、部分备份、对于InnoDB存储引擎支持热备
cp, tar 等归档复制工具: 物理备份工具, 适用于所有的存储引擎, 冷备、完全备份、部分备份
lvm2 snapshot: 几乎热备, 借助文件系统管理工具进行备份
mysqlhotcopy: 名不副实的的一个工具, 几乎冷备, 仅支持MyISAM存储引擎
xtrabackup: 一款非常强大的InnoDB/XtraDB热备工具, 支持完全备份、增量备份, 由percona提供
设计合适的备份策略
针对不同的场景下, 我们应该制定不同的备份策略对数据库进行备份, 一般情况下, 备份策略一般为以下三种
直接cp,tar复制数据库文件
mysqldump+复制BIN LOGS
lvm2快照+复制BIN LOGS
xtrabackup
以上的几种解决方案分别针对于不同的场景
如果数据量较小, 可以使用第一种方式, 直接复制数据库文件
如果数据量还行, 可以使用第二种方式, 先使用mysqldump对数据库进行完全备份, 然后定期备份BINARY LOG达到增量备份的效果
如果数据量一般, 而又不过分影响业务运行, 可以使用第三种方式, 使用lvm2的快照对数据文件进行备份, 而后定期备份BINARY LOG达到增量备份的效果
如果数据量很大, 而又不过分影响业务运行, 可以使用第四种方式, 使用xtrabackup进行完全备份后, 定期使用xtrabackup进行增量备份或差异备份)
数据库主从同步数据延迟问题
mysql 用主从同步的方法进行读写分离,减轻主服务器的压力的做法现在在业内做的非常普遍。 主从同步基本上能做到实时同步

在配置好了, 主从同步以后, 主服务器会把更新语句写入binlog, 从服务器的IO 线程(这里要注意, 5.6.3 之前的IO线程仅有一个,5.6.3之后的有多线程去读了,速度自然也就加快了)回去读取主服务器的binlog 并且写到从服务器的Relay log 里面,然后从服务器的 的SQL thread 会一个一个执行 relay log 里面的sql , 进行数据恢复
-
主从同步的延迟的原因
一个服务器开放N个链接给客户端来连接的,这样有会有大并发的更新操作, 但是从服务器的里面读取binlog 的线程仅有一个, 当某个SQL在从服务器上执行的时间稍长 或者由于某个SQL要进行锁表就会导致,主服务器的SQL大量积压,未被同步到从服务器里。这就导致了主从不一致, 也就是主从延迟。
-
主从同步延迟的解决办法
实际上主从同步延迟根本没有什么一招制敌的办法, 因为所有的SQL必须都要在从服务器里面执行一遍,但是主服务器如果不断的有更新操作源源不断的写入, 那么一旦有延迟产生, 那么延迟加重的可能性就会原来越大。 当然可以做一些缓解的措施。
因为主服务器要负责更新操作, 他对安全性的要求比从服务器高, 所有有些设置可以修改,比如sync_binlog=1,innodb_flush_log_at_trx_commit = 1 之类的设置,而slave则不需要这么高的数据安全,完全可以讲sync_binlog设置为0或者关闭binlog,innodb_flushlog, innodb_flush_log_at_trx_commit 也 可以设置为0来提高sql的执行效率 这个能很大程度上提高效率。另外就是使用比主库更好的硬件设备作为slave。
就是把一台从服务器当度作为备份使用, 而不提供查询, 那边他的负载下来了, 执行relay log 里面的SQL效率自然就高了。
增加从服务器,这个目的还是分散读的压力, 从而降低服务器负载。
-
判断主从延迟的方法
MySQL提供了从服务器状态命令,可以通过 show slave status 进行查看, 比如可以看看Seconds_Behind_Master参数的值来判断,是否有发生主从延时。
其值有这么几种:
NULL - 表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes.
0 - 该值为零,是我们极为渴望看到的情况,表示主从复制状态正常