Hubble.net 搜索引擎分析四
4.Hubble.Net查询过程
Hubble.net的查询过程为:首先在数据库中,通过列的match查询得到所需的原始数据。在通过倒排索引对象获取索引词的位置信息。最后组合(加亮)返回。
现已Hubble.net中的Dome项目为例子来说明Hubble.net的查询过程。如下模型图:
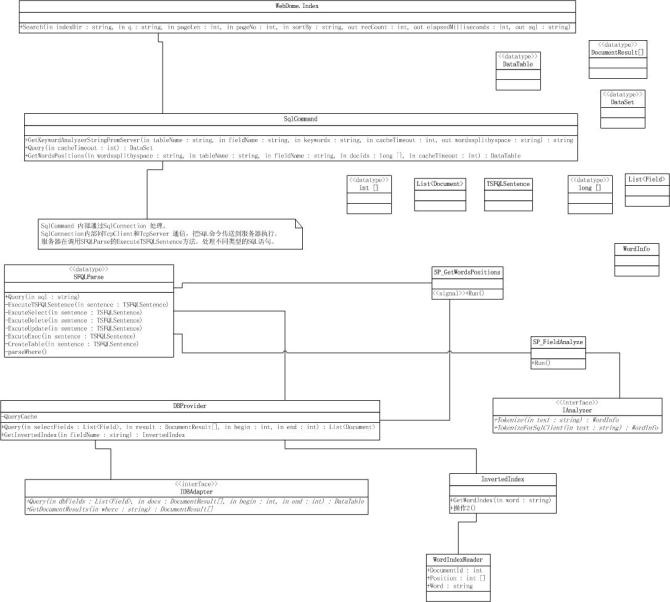
1.用户通过WebDome.Index.Search()方法查询数据。传递需要的参数:查询条件、索引目录、每页记录数、当前页数。返回查询时间、内部解析后的条件。
2.Search()方法内部,
1.>首先调用SqlCommand.GetKeywordAnalyzerStringFromServer()进行分词,GetKeywordAnalyzerStringFromServer()内部调用SP_FieldAnalyze存储过程,通过TCP达到服务器,最终调用SP_FieldAnalyze内的Run方法,最后调用IAnalyzer.Tokenize()分词。并返回结果。
2.>根据返回的分词构造SQL查询语句并调用SqlCommand.Query()查询数据。
A.Query()方法内部调用_SqlConnection. QuerySql()方法把SQL语句发送到服务器。并把返回的结果缓存起来。
B.服务器接受到SQL语句后,首先解析SQL语句生成List<TSFQLSentence>列表,并判断TSFQLSentence类型,根据不同的类型执行不同的方法,这儿调用ExcuteSelect()方法。
C. ExcuteSelect方法内部,首先判断Process data cache 获取程序集缓存。如果没有,在判断dbProvider.QueryCache 是否超时。如果超时,就查询数据库,根据SQL where条件查询DocId。
D.根据查询列和记录ID列表,调用dbProvider.Query()方法查询列值。而Query方法内部在调用IDBAdapter.Query()查询数据库值,并初始化文档列值,且返回。
3.> 根据文档ID列表和分词,调用SqlCommand.GetWordsPositions()方法获取词语在文档中的位置信息。GetWordsPositions方法调用SP_GetWordsPositions存储过程,并发送到服务器,服务器解析后调用SP_GetWordsPositions.Run方法。Run方法内部调用dbProvider.GetInvertedIndex()获取倒排索引对象,在通过invertedIndex.GetWordIndex()获取词语的阅读器,读取本词语关联的文档索引位置信息。
4.>根据以上返回的结果构造最后的结果,返回给用户。
注:Search()方法中构造的SQLselect between {0} to {1} * from News where content match {2} or title^2 match {2} order by。Where部分采用的是数据库全文搜素。然后在根据查询得到的文档ID和分词结果,查询分词对应文档中的位置信息。不知道这样是否好。我想应该是根据分词查询文档ID,然后在求各词语的并集,最后在根据文档ID获取原始信息。因为内存中已经有了词语的索引信息(文档ID,文档中的位置等)。