引言
在与实现了语音合成、语义分析、机器翻译等算法的后端交互时,页面可以设计成更为人性化、亲切的方式。我们采用类似于聊天对话的实现,效果如下:
- 智能客服(输入文本,返回引擎处理后的文本结果)
- 语音合成(输入文本,返回文本以及合成的音频)

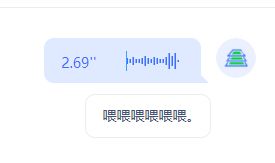
如上图所示,返回文本后,再返回合成出的音频。
音频按钮嵌在对话气泡中,可以点击播放。
- 语音识别(在页面录制语音发送,页面实时展示识别出的文本结果)
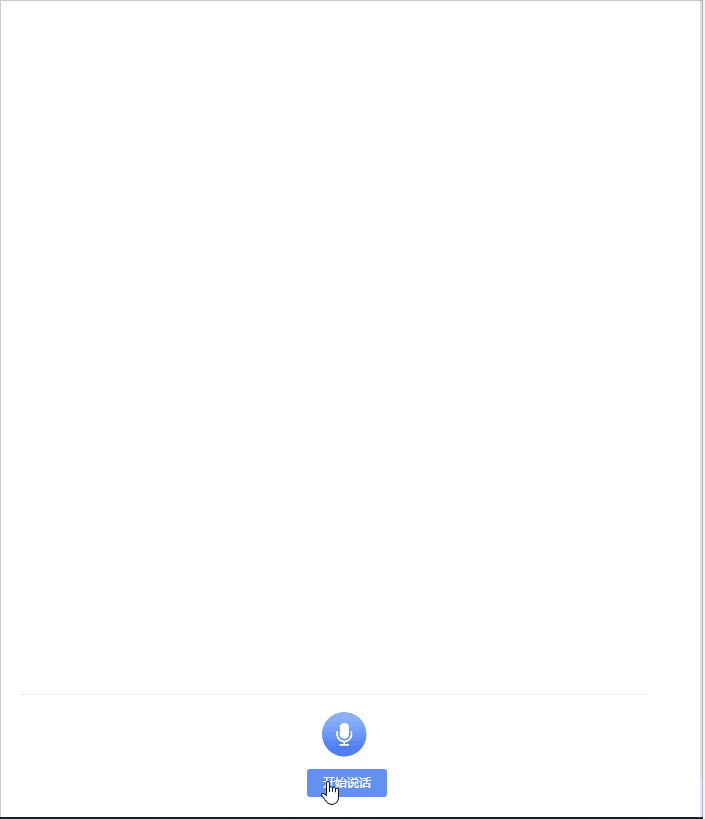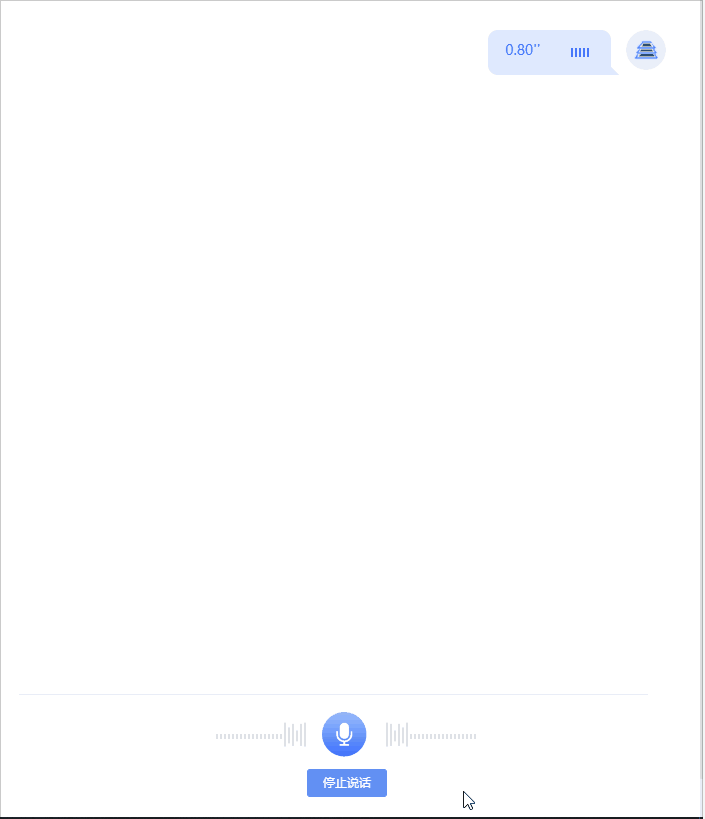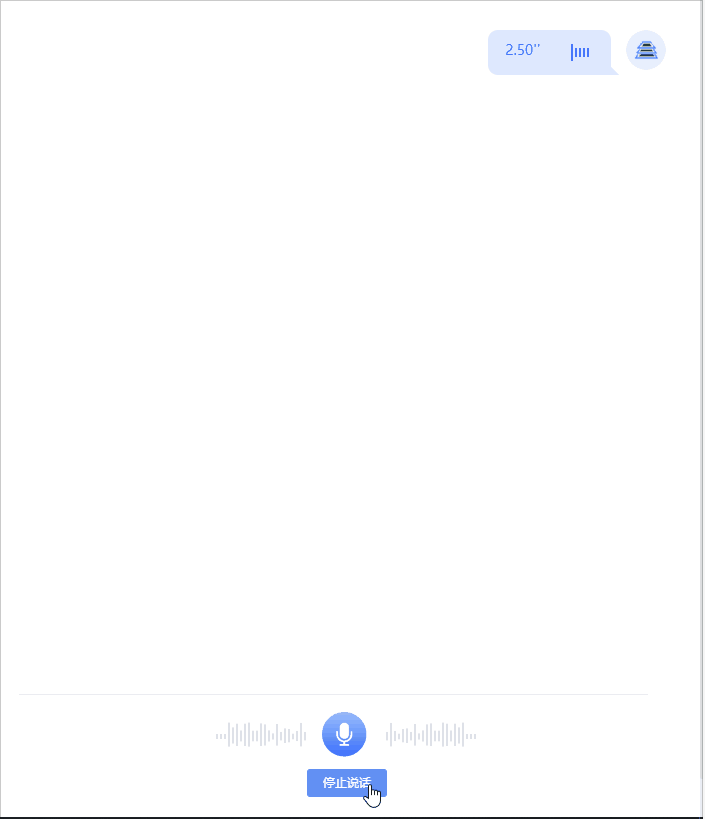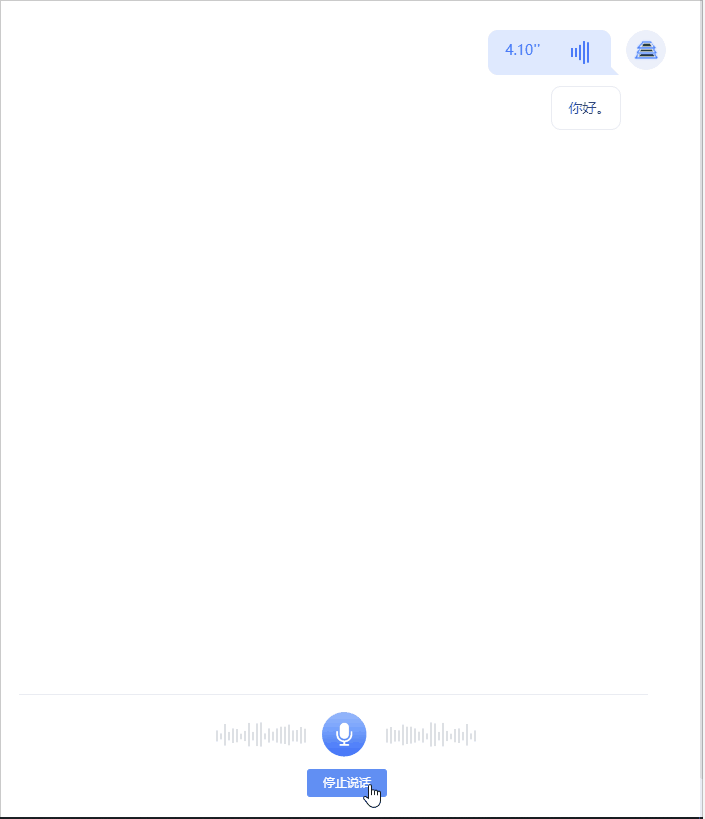
实现功能及技术要点
1、基于WebSocket实现对话流
页面与后端的交互是实时互动的,所以采用WebSocket协议,而不是HTTP请求,这样后端推送回的消息可以实时显示在页面上。
WebSocket的返回是队列的、无序的,在后续处理中我们也需要注意这一点,在后文中会说到。
2、调用设备麦克风进行音频录制和转码加头,基于WebAudio、WaveSurferJS等实现音频处理和绘制
3、基于Vue的响应式页面实现
4、CSS3 + Canvas + JS 交互效果优化
- 录制音频CSS动画效果
- 聊天记录自动滚动
下面给出部分实现代码。
集成WebSocket
我们的聊天组件是页面侧边打开的抽屉(el-drawer),Vue组件会在打开时创建,关闭时销毁。在组件中引入WebSocket,并管理它的开、关、消息接收和发送,使它的生命周期与组件一致(打开窗口时创建ws连接,关闭窗口时关闭连接,避免与后台连接过多。)
created(){
if (typeof WebSocket === 'undefined') {
alert('您的浏览器不支持socket')
} else {
// 实例化socket
this.socket = new WebSocket(this.socketServerPath)
// 监听socket连接
this.socket.onopen = this.open
// 监听socket错误信息
this.socket.onerror = this.error
// 监听socket消息
this.socket.onmessage = this.onMessage
this.socket.onclose = this.close
}
}
destroyed(){
this.socket.close()
}
如上,将WebSocket的事件绑定到JS方法中,可以在对应方法中实现对数据的接收和发送。
打开浏览器控制台,选中指定的标签,便于对WebSocket连接进行监控和查看。
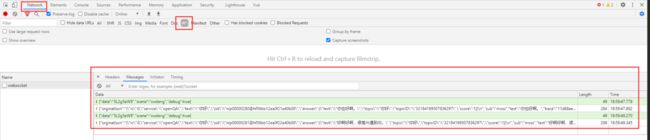
音频录制采集
从浏览器端音频和视频采集基于网页即时通信(Web Real-Time
Communication,简称WebRTC) 的API。通过WebRTC的getUserMedia实现,获取一个MediaStream对象,将该对象关联到AudioContext即可获得音频。
可参考RecorderJS的实现: https://github.com/mattdiamond/Recorderjs/blob/master/examples/example_simple_exportwav.html
if (navigator.getUserMedia) {
navigator.getUserMedia(
{ audio: true }, // 只启用音频
function(stream) {
var context = new(window.webkitAudioContext || window.AudioContext)()
var audioInput = context.createMediaStreamSource(stream)
var recorder = new Recorder(audioInput)
},
function(error) {
switch (error.code || error.name) {
case 'PERMISSION_DENIED':
case 'PermissionDeniedError':
throwError('用户拒绝提供信息。')
break
case 'NOT_SUPPORTED_ERROR':
case 'NotSupportedError':
throwError('浏览器不支持硬件设备。')
break
case 'MANDATORY_UNSATISFIED_ERROR':
case 'MandatoryUnsatisfiedError':
throwError('无法发现指定的硬件设备。')
break
default:
throwError('无法打开麦克风。异常信息:' + (error.code || error.name))
break
}
}
)
} else {
throwError('当前浏览器不支持录音功能。')
}
注意: 若navigator.getUserMedia获取到的是undefined,是Chrome浏览器的安全策略导致的,需要通过https请求或配置浏览器,配置地址: chrome://flags/#unsafely-treat-insecure-origin-as-secure
浏览器采集到的音频为PCM格式(PCM (脉冲编码调制 Pulse Code Modulation)),需要对音频加头才能在页面上进行播放。注意加头时采样率、采样频率、声道数量等必须与采样时相同,不然加完头后的音频无法解码。参考查看https://github.com/mattdiamond/Recorderjs/blob/master/src/recorder.js中exportWav方法。
业务中对接的语音识别引擎为实时转写引擎,即:不是录制完成后再发送,而是一边录制一边进行编码并发送。
使用onaudioprocess方法监听语音的输入:
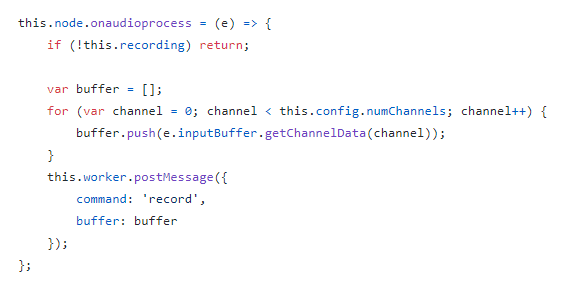
参考这个实现,我们可以在每次监听到有数据写入时,从buffer中获取到录制到的数据,并进行编码、压缩,再通过WebSocket发送。
Vue组件设计和业务实现
分析页面业务逻辑,将代码拆分成两个组件:
ChatDialog.vue 聊天对话框页面,根据输入类型,分为文本输入、语音输入。
ChatRecord.vue聊天记录组件,根据发送方(自己或者系统)展示向左/向右的气泡,根据内容显示文本、音频等。ChatDialog是ChatRecord的父组件,遍历ChatDialog中的chatList对象(Array),将chatList中的项注入到ChatRecord中。