
一 原型模式引入
原型模式作为创建型模式的最后一种,它并没有涉及到很多的内容,我们来看一下
首先举一个生活上的例子,例如我们要出版一本书,其中有一些信息字段,例如书名价格等等
public class Book {
private String name; // 姓名
private int price; // 价格
private Partner partner; // 合作伙伴
// 省略构造函数、get set、toString 等
}引用类型 Partner 也很简单
public class Partner{
private String name;
// 省略构造函数、get set、toString 等
}(一) 直接 new
书籍出版肯定不能只出一本,如何大批量生产呢?
有人或许想到,像下面这样每一次都重新 new(甚至写个 for 循环),咱先不说大量 new 的效率问题,首先每次一都需要重新给新对象复制,这不就像,我每刊印一本书,就得重新写一次吗???
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一个合作伙伴类型
Partner partner = new Partner("张三");
// 带参赋值
Book bookA = new Book("理想二旬不止", 66, partner);
Book bookB = new Book("理想二旬不止", 66, partner);
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}有的同学还或许想到了,先把 A 创建出来,然后再赋值给 B、C ..... 等等,但是这种方式其实是传递引用而不是传值,这就好比在 C 和 B 上写着,内容详情请看 A
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一个合作伙伴类型
Partner partner = new Partner("张三");
// 带参赋值
Book bookA = new Book("理想二旬不止", 66, partner);
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
// 引用赋值
Book bookB = bookA;
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}这两样显然是不行的,我们正常的思路是,作者只需要写一次书籍内容,先刊印一本,如果能行,就照着这个样本进行大批量同彩复印,而上面的传引用方法也显然不合适,这就需要用到Java克隆
(二) 浅克隆
用到克隆,首先就对 Book 类进行处理
- 首先实现 Cloneable 接口
- 接着重写 clone 方法
public class Book implements Cloneable{
private String name; // 姓名
private int price; // 价格
private Partner partner; // 合作伙伴
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
// 省略构造函数、get set、toString 等
}
再来测试一下
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一个合作伙伴类型
Partner partner = new Partner("张三");
// 带参赋值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}执行结果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=张三}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=张三}}
B: 1163157884
结果非常明显,书籍信息是一致的,但是内存地址是不一样的,也就是说确实克隆成功了,打印其 hashCode 发现两者并不相同,说明不止指向同一个,也是满足我们要求的
到这里并没有结束,你会发现还是有问题,当你刊印的过程中修改一些值的内容的时候,你看看效果
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一个合作伙伴类型
Partner partner = new Partner("张三");
// 带参赋值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
// 修改数据
partner.setName("李四");
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}执行结果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
B: 1163157884
???这不对啊,B 明明是先克隆 A 的,为什么我在克隆后,修改了 A 中一个的值,但是B也变化了啊
这就是典型的浅克隆,在 Book 类,当字段是引用类型,例如 Partner 这个合作伙伴类,就是我们自定义的类,这种情况复制引用不赋值引用的对象,因此,原始对象和复制后的这个Partner对象是引用同一个对象的
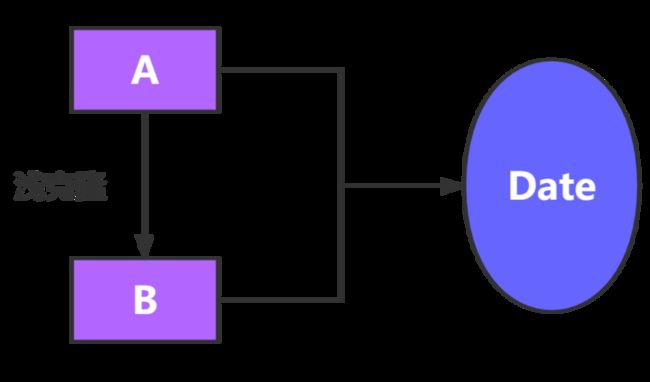
(三) 深克隆
如何解决上面的问题呢,我们需要重新重写 clone 的内容,同时在引用类型中也实现浅克隆
(1) 被引用类型实现浅克隆
全代码如下
public class Partner implements Cloneable {
private String name;
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
// 省略构造函数、get set、toString 等
}(2) 修改引用类 cloen 方法
public class Book implements Cloneable{
private String name; // 姓名
private int price; // 价格
private Partner partner; // 合作伙伴
@Override
protected Object clone() throws CloneNotSupportedException {
Object clone = super.clone();
Book book = (Book) clone;
book.partner =(Partner) this.partner.clone();
return clone;
}
// 省略构造函数、get set、toString 等
}测试一下
public class Test {
public static void main(String[] args) throws CloneNotSupportedException {
// 初始化一个合作伙伴类型
Partner partner = new Partner("张三");
// 带参赋值
Book bookA = new Book("理想二旬不止", 66, partner);
// B 克隆 A
Book bookB = (Book) bookA.clone();
// 修改数据
partner.setName("李四");
System.out.println("A: " + bookA.toString());
System.out.println("A: " + bookA.hashCode());
System.out.println("B: " + bookB.toString());
System.out.println("B: " + bookB.hashCode());
}
}执行效果
A: Book{name='理想二旬不止', price=66, partner=Partner{name=李四}}
A: 460141958
B: Book{name='理想二旬不止', price=66, partner=Partner{name=张三}}
B: 1163157884
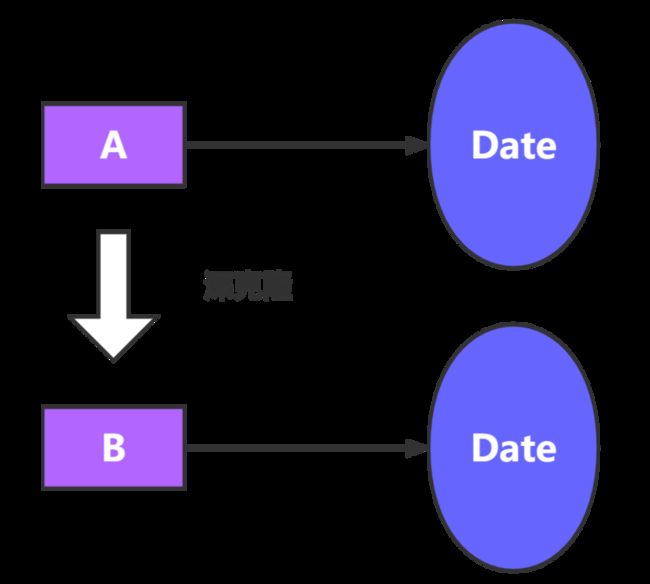
可以看到,B 克隆 A 后,修改 A 中 合作伙伴 的值,没有受到影响,这也就是我们一开头想要实现的效果了

二 原型模式理论
(一) 什么是原型模式
在一些程序中,或许需要创建大量相同或者相似的对象,在构造函数的执行比较缓慢的时候,多次通过传统的构造函数创建对象,就会复杂且耗资源,同时创建时的细节也一样暴露了出来
原型模式就可以帮助我们解决这一问题
定义:原型模式,甩原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象
(二) 结构
根据结构图简单说一下其中的角色:
- 抽象原型类(Prototype):规定了具体原型对象必须实现的接口
- 具体原型类(ConcretePrototype):实现 clone 方法,即一个克隆自身的操作
- 访问类(Client):使用具体原型类中的 clone 方法克隆自身,从而创建一个新的对象
(三) 两种模式
根据上面的例子也可以看出来了,原型模式分为浅克隆和深克隆
- 浅克隆:创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址
- 深克隆:创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。
(四) 优缺点
优点:
- Java 原型模式基于内存二进制流复制,比直接 new 的性能会更好一些
- 可以利用深克隆保存对象状态,存一份旧的(克隆出来),在对其修改,可以充当一个撤销功能
缺点:
- 需要配置 clone 方法,改造时需要对已有类进行修改,违背 “开闭原则”
如果对象间存在多重嵌套引用时,每一层都需要实现克隆
- 例如上例中,Book 中实现深克隆,Partner 中实现浅克隆,所以要注意深浅克隆运用得当