更多精彩文章,请关注xhJaver,京东工程师和你一起成长
volatile 简介
一般用来修饰共享变量,保证可见性和可以禁止指令重排
- 多线程操作同一个变量的时候,某一个线程修改完,其他线程可以立即看到修改的值,保证了共享变量的可见性
- 禁止指令重排,保证了代码执行的有序性
- 不保证原子性,例如常见的i++
(但是对单次读或者写保证原子性)
可见性代码示例
以下代码建议使用PC端来查看,复制黏贴直接运行,都有详细注释
我们来写个代码测试一下,多线程修改共享变量时究竟需不需要用volatile修饰变量
- 首先,我们创建一个任务类
public class Task implements Runnable{
@Override
public void run() {
System.out.println("这是"+Thread.currentThread().getName()+"线程开始,flag是 "+Demo.flag);
//当共享变量是true时,就一直卡在这里,不输出下面那句话
// 当flag是false时,输出下面这句话
while (Demo.flag){
}
System.out.println("这是"+Thread.currentThread().getName()+"线程结束,flag是 "+Demo.flag);
}
} 2.其次,我们创建个测试类
class Demo {
//共享变量,还没用volatile修饰
public static boolean flag = true ;
public static void main(String[] args) throws InterruptedException {
System.out.println("这是"+Thread.currentThread().getName()+"线程开始,flag是 "+flag);
//开启刚才线程
new Thread(new Task()).start();
try {
//沉睡一秒,确保刚才的线程已经跑到了while循环
//要不然还没跑到while循环,主线程就将flag变为false
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
//改变共享变量flag转为false
flag = false;
System.out.println("这是"+Thread.currentThread().getName()+"线程结束,flag是 "+flag);
}
}3.我们查看一下输出结果

可见,程序并没有结束,他卡在了这里,为什么卡在了这里呢,就是因为我们在主线程修改了共享变量flag为false,但是另一个线程没有感知到,这个变量的修改对另一个线程不可见
- 如果要是用volatile变量修饰的话,结果就变成了下面这个样子
public static volatile boolean flag = true

可见,这次主线程修改的变量被另一个线程所感知到了,保证了变量的可见性
可见性原理分析
那么,神奇的 volatile 底层到底做了什么呢,你的改变,逃不过他的法眼?为什么不用他修饰变量的话,变量的改变其他线程就看不见?
回答此问题的时候首先,我们需要了解一下JMM(Java内存模型)
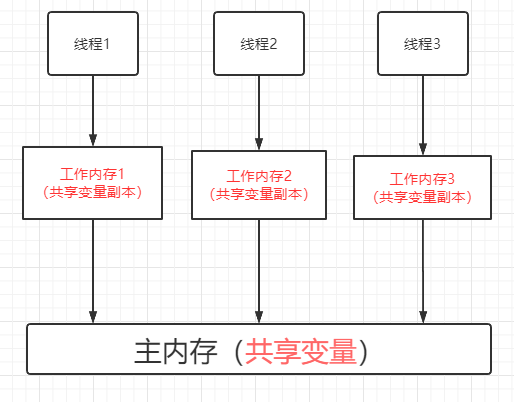
注: 本地内存是JMM的一种抽象,并不是真实存在的,本地内存它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化之后的一个数据存放位置
由此我们可以分析出来,主线程修改了变量,但是其他线程不知道,有两种情况
- 主线程修改的变量还没有来得及刷新到主内存中,另一个线程读取的还是以前的变量
- 主线程修改的变量刷新到了主内存中,但是其他线程读取的还是本地的副本
当我们用
volatile关键字修饰共享变量时就可以做到以下两点- 当线程修改变量时,会强制刷新到主内存中
- 当线程读取变量时,会强制从主内存读取变量并且刷新到工作内存中
指令重排
- 何为指令重排?
为了提高程序运行效率,编译器和cpu会对代码执行的顺序进行重排列,可这有时候会带来很多问题
我们来看下代码
//指令重排测试
public class Demo2 {
private Integer number = 10;
private boolean flag = false;
private Integer result = 0;
public void write(){
this.flag = true; // L1
this.number = 20; // L2
}
public void reader(){
while (this.flag){ // L3
this.result = this.number + 1; // L4
}
}
}假如说我们有A、B两个线程 他们分别执行write()方法和 reader()方法,执行的顺序有可能如下图所示 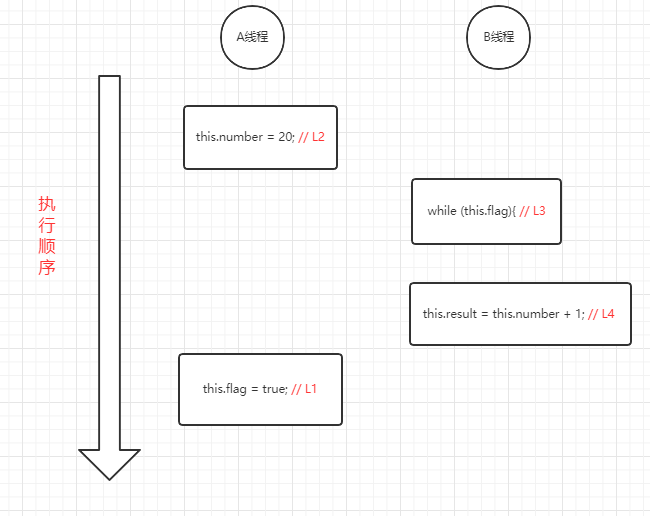
- 问题分析: 如图可见,A线程的L2和L1的执行顺序重排序了,如果要是这样执行的话,当A执行完L2时,B开始执行L3,可是这个时候flag还是为false,那么L4就执行不了了,所以result的值还是初始值0,没有被改变为21,导致程序执行错误
这个时候,我们就可以用volatile关键字来解决这个问题,很简单,只需
private volatile Integer number = 10;
- 这个时候L1就一定在L2前面执行
A线程在修改number变量为20的时候,就确保这句代码的前面的代码一定在此行代码之前执行,在number处插入了 内存屏障 ,为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排
内存屏障
内存屏障又是什么呢?一共有四种内存屏障类型,他们分别是
LoadLoad屏障:
- Load1 LoadLoad Load2 确保Load1的数据的装载先于Load2及所有后续装载指令的装载
LoadStore屏障:
- Load1 LoadStore Store2 确保Load1的数据的装载先于Store2及所有后续存储指令的存储
StoreLoad屏障:
- Store1 StoreLoad Load2 确保Store1的数据对其他处理器可见(刷新到内存)先于Load2及所有后续的装载指令的装载
StoreStore屏障:
- Store1 StoreStore Store2 确保Store1数据对其他处理器可见(刷新到内存)先于Store2及所有后续存储指令的存储
> StoreLoad 是一个全能型的屏障,同时具有其他3个屏障的效果。执行该屏障的花销比较昂贵,因为处理器通常要把当前的写缓冲区的内容全部刷新到内存中(Buffer Fully Flush)
- 装载load 就是读 int a = load1 ( load1的装载)
- 存储store就是写 store1 = 5 ( store1的存储)
volatile与内存屏障
那么volatile和这四种内存屏障又有什么关系呢,具体是怎么插入的呢?
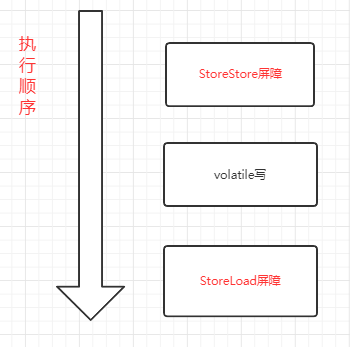
volatile写 (前后都插入屏障)
- 前面插入一个StoreStore屏障
- 后面插入一个StoreLoad屏障
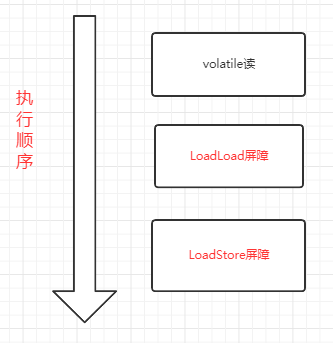
volatile读(只在后面插入屏障)
- 后面插入一个LoadLoad屏障
- 后面插入一个LoadStore屏障
官方提供的表格是这样的 
我们此时回过头来在看我们的那个程序
this.flag = true; // L1
this.number = 20; // L2由于number被volatile修饰了,L2这句话是volatile写,那么加入屏障后就应该是这个样子
this.flag = true; // L1
// StoreStore 确保flag数据对其他处理器可见(刷新到内存)先于number及所有后续存储指令的存储
this.number = 20; // L2
// StoreLoad 确保number数据对其他处理器可见(刷新到内存)先于所有后续存储指令的装载所以L1,L2的执行顺序不被重排序
ps:总部四号楼真是越来越好了,奖励自己一杯奶茶

更多精彩,请关注公众号xhJaver,京东工程师和你一起成长