简介:为什么要强调 书写规范 ?这其实并不关乎“美丑”,而是为了 更高的效率(代码阅读、开发、维护)与更方便的合作(全球通用的标准) 。如今,不管什么方向的同学都要进行“写代码”这项工作,可惜的是,很多朋友并没有意识到: 花费1小时了解代码书写规范,可以为自己节省 100+ 小时的写代码的时间。 代码规范的魅力在于 实实在在地简化问题 ,并不需要我们奉为圭臬或引起争论。本文我们主要以 python 为例,以 pep8 为主要参考资料,分三个层次进行讨论。
本文三个层次:
- 不注意这些,你写的根本不是代码
- 这些规范,实质是尊重程序的逻辑
- 一些我会忽略的规范,更多的思考
不注意这些,你写的根本不是代码
1/2 来看看我两年前的代码
import tkinter
import tkinter.messagebox
def message_box(error_content):
top = tkinter.Tk() # *********
top.withdraw() # ****实现主窗口隐藏
top.update() # *********需要update一下
txt=tkinter.messagebox.showinfo("提示",error_content)
top.destroy()
return txt上述是在用 python 的 tkinter 做一个桌面应用,看起来似乎没什么问题?大问题,比如项目逻辑/设计架构 的确难以通过这么几行代码看出来 ;但是,上面这几行代码的书写习惯,反映了一个人的思维不够成熟:
- 注释不需要
# ****这么书写,完全没必要 需要update一下这是废话,前面不就是update()函数吗?("提示",error_content)中间应该打空格txt=tkinter左右两边应该加空格
如果让现在的我来写,我会如下实现:
import tkinter
from tkinter import messagebox as msg
def show_message_box(error_content):
"""
Piper蛋窝:
输入错误信息,messagebox 显示信息
(皮一下:欢迎关注 Piper蛋窝~)
"""
tk = tkinter.Tk()
tk.withdraw()
tk.update()
txt = msg.showinfo("提示", error_content)
tk.destroy()
return txt如上:
- 我改掉了些小毛病,比如有没有空格等,但这其实不是重点
- 我把函数名从
message_box改为了show_message_box,因为message_box看起来像一个名词,并不是动词(去执行一项任务),在项目结构复杂后,我们可能有很多函数、类、实例,如果 不做动名词区分,我们自己都可能混淆,还要翻回源码进行查阅,浪费大量时间 - 我把注释(这个函数负责干什么)放在了
"""注释"""里,这样解释器与 InelliSense 会在我们调用时,做自动的说明,如下图

2/2 最基本的:缩进、命名与空间
朋友,如果你写代码时连 缩进、命名与空间 这三点都不会注意到,那恭喜你,这篇文章很有可能让你提升一个阶段。
我就见过刚刚学 c 的大一小朋友,在机房的 VC 6 里一个一个地敲下字符:
#include
int main()
{int a=5,b=7,c;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;} 很显然,这位小朋友的代码真的仅仅是“敲进电脑的字符”而已,ta心里完全没有程序的逻辑、层次。这代码是死的,不是活的。我仅仅加一些空格和回车,来解释, 为什么这些缩进、命名与空间让代码成为真正的代码 。
#include
int main()
{
int a = 5, b = 7, c;
printf("a = %d, b = %d, c = %d", a, b, c);
return 0;
} 如上:
- 我把
{}独立,并对其中代码块做了缩进,表示这些代码是函数main()内部的逻辑 - 我加了空格,如把
a=5变成了a = 5,是因为程序员也是人,也需要读看得清晰的东西 - 我在
#include与int main()间加了空行,因为这二者是两件事:前者负责引入io标准库,后者负责执行逻辑。 在写代码时,不要吝啬空行,来区分不同的逻辑与任务
上面的讨论是不是过于基础?下面我们以 python 以及其官方文档 pep 8 为例,来看看更多体现程序逻辑、增强代码可读性的官方建议。
如果下回有人再让你看ta写的“死代码”,你先把这篇文章扔给ta,让ta改好!
这些规范,实质是尊重程序的逻辑
1/4 缩进与空格:体现逻辑
Indentation 缩进
著名美剧《硅谷》里有个情节, 程序员会因为使用制表符还是空格吵得不可开交,似乎是一个原则性问题?
这当然只是玩笑。
在 python 中,推荐使用 4 个空格来进行缩进。我在打 kdd cup 是见过 2 个空格表示缩进的(官方 start toolkit 里)。我觉得这是无所谓的,关键是, 你要在项目里进行统一。
此外, 缩进是用来体现程序结构的,如果你的结构不是包含关系,仅仅是换行,那么也用 4 个空格缩进将很愚蠢。 如下。
# 推荐
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 或者
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 或者
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 或者
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)
# 愚蠢
foo = long_function_name(var_one, var_two,
var_three, var_four)
# 愚蠢
def long_function_name(
var_one, var_two, var_three,
var_four):
print(var_one)为什么?我们以最下面的 def long_function_name 为例,注意到了吗:
print(var_one)应该是def long_function_name的内部结构,因此必须比def long_function_name前多一个缩进- 但是
var_one, var_two, var_three这些参数是def long_function_name的一部分,与def long_function_name同级 - 函数参数与函数内部结构对齐,就很容易让人混淆
因此,你只需要 制造区分度 就可以。至于你是多加两个空格,还是减少两个,这个无所谓(除非你们组织做了特定的规定), 能让你和别人一眼看出逻辑结构就好 。
Should a line break before or after a binary operator?
此外, pep 8 还推荐了 operator 的位置,这个我以前真的没有注意到。
# No: operators sit far away from their operands
income = (gross_wages +
taxable_interest +
(dividends - qualified_dividends) -
ira_deduction -
student_loan_interest)
# Yes: easy to match operators with operands
income = (gross_wages
+ taxable_interest
+ (dividends - qualified_dividends)
- ira_deduction
- student_loan_interest)此外,为了防止编译错误,我会在换行时加上 \\ 表示将换行键转义。
income = (gross_wages \
+ taxable_interest \
+ (dividends - qualified_dividends) \
- ira_deduction \
- student_loan_interest)现在看来,可能这种情况下没有这个必要。
拒绝无意义的空格
Yes: spam(ham[1], {eggs: 2})
No: spam( ham[ 1 ], { eggs: 2 } )
Yes: if x == 4: print x, y; x, y = y, x
No: if x == 4 : print x , y ; x , y = y , x如上是 Pet Peeves 中的建议,很显然,过于松散的结构,也不利于我们阅读和看出逻辑。这是一种所有编程语言通用的习惯,值得养成。
函数变量省缺值
# Yes
def complex(real, imag=0.0):
return magic(r=real, i=imag)
# No
def complex(real, imag = 0.0):
return magic(r = real, i = imag)如上,在定义某个省缺值时,我们鼓励去掉 = 左右的空格。
# Yes
def munge(sep: AnyStr = None): ...
def munge(input: AnyStr, sep: AnyStr = None, limit=1000): ...
# No
def munge(input: AnyStr=None): ...
def munge(input: AnyStr, limit = 1000): ...但是,如上,值得注意的是,如果定义了函数的数据类型(如 AnyStr),则我们需要提醒开发者注意区分,不要去掉 = 左右的空格。
2/4 import
Yes: import os
import sys
No: import sys, os
# Yes
i = i + 1
submitted += 1
x = x*2 - 1
hypot2 = x*x + y*y
c = (a+b) * (a-b)
# No
i=i+1
submitted +=1
x = x * 2 - 1
hypot2 = x * x + y * y
c = (a + b) * (a - b)关于 import 的规范有几条,我这里着重强调一个新手可能都会有的“坏习惯”: 把毫不相干的库放在一个 import 下。
图什么呢?没有任何意义。比如上面,sys 其实与 os 没有任何包容关系,我们何必吝啬这一行 import 呢?且放在一起,不利于 formatter 帮我们整理书写。
3/4 变量、函数名称
选一个好的命名规则
不同的企业/组织,尤其是大型的企业,会有一套自己的命名规范。对于 java ,我记得大家最常用的应该是“驼峰”式命名:
public void printUserName(int index) {
...
}在 python ,鼓励各种通用形式的命名,如:
printUserNameprint_user_name
我觉得大家在 python 中最常用的是 下划线+小写 的形式。
在 pep 8 的 Descriptive: Naming Styles 有个标注,很搞笑:
Capitalized_Words_With_Underscores (ugly!)为什么说 Capitalized_Words_With_Underscores “丑”呢?
我觉得是 信息冗余 了:下划线或者大写首字母,都是用于间隔单词的,两个都使用,真的不简洁、不优雅。
“私有”变量
在 C++ 或者 java 中,我们都会接触到 private 这类概念。初学者可能会一头雾水:为什么变量要分为私有的、公共的、受保护的?
python 让初学者避开了这部分可能产生的费解,但是又没有去掉私有变量等功能,我觉得这正是 pythonic 的体现。 而且,现在的语言都有此趋势,比如 go ,限制首字母大小写区分变量私有共有,简洁优雅,又统一了社区开发规范。
对于 python ,我们在变量前加了两个下划线,则其变为私有了。私有变量为了项目的规范与安全,不能被外部调用,我写了一段程序如下。
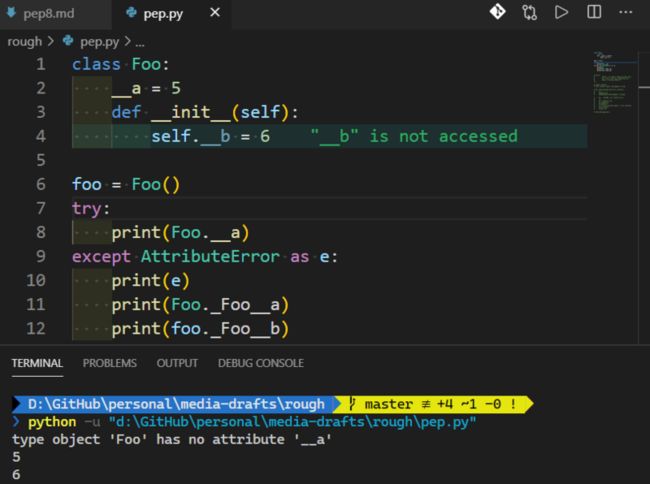
如上,直接调用 Foo.__a 或者 foo.__b 会产生 AttributeError 错误。但是 python 给了个“后门”,你仍然可以通过 _类名__变量名 调用私有变量。
4/4 尊重“人类的思维”
# Yes
if foo is not None:
# No
if not foo is None:如上,或许新手会觉得 not ... is 这种结构逻辑来了个反转,很好玩,尽管其作用与 is not 完全相同。
还是那句话,程序员也是人,大家都喜欢简单清晰的逻辑。除非是很巧妙的技巧,否则,没有必要玩文字游戏,降低效率。
# Yes
try:
value = collection[key]
except KeyError:
return key_not_found(key)
else:
return handle_value(value)
# No
try:
# Too broad!
return handle_value(collection[key])
except KeyError:
# Will also catch KeyError raised by handle_value()
return key_not_found(key)如上,在使用 try catch 时,我们想捕捉 KeyError ,那就不要在 try 中进行别的操作。为什么?
- 如果
handle_value()本身有错,那么我们很难通过handle_value(collection[key])捕捉其自己的错误,因为其与collection[key]可能出现的错误混淆在了一起
# Yes
def foo(x):
if x >= 0:
return math.sqrt(x)
else:
return None
def bar(x):
if x < 0:
return None
return math.sqrt(x)
# No
def foo(x):
if x >= 0:
return math.sqrt(x)
def bar(x):
if x < 0:
return
return math.sqrt(x)如上, x 小于 0 时,无法开平方,自然也就无法输入 math.sqrt() 。这里我们应该让程序更加清晰一些,尽管我们知道如果一个函数什么都不做返回的是 None ,但是也不要不写 return None 。用 pep 8 的话说,我们应该 be consistent in return statements.
一些我会忽略的规范,更多的思考
1/3 每行最多字符数?I say NO.
我们知道, pep 8 希望我们每行 最多 79 个字符。
我觉得对于我这种开发者来说,真的没必要。而且,我读过很多优秀的开源框架,其也没有尊重这个标准。
原因很简单,我们的生产环境不同。
我喜欢大字体,而且我只有一个小小的笔记本电脑,连工位都没有。 很多朋友拥有好几块屏幕/加长屏幕,而我只能把一块小小的笔记本显示器竖着一分为二。如下图。

无论是 79 个字符,还是 109 个字符,我的编辑器都不能一行显示下来,因此这条规范对我来说意义不大。
或许开发 python 标准库时会用上。但不是现在。
2/3 注释文件标准?我复议
pep 8 与 pep 257 中,都对注释方式进行了标准化,如下。
def complex(real=0.0, imag=0.0):
"""Form a complex number.
Keyword arguments:
real -- the real part (default 0.0)
imag -- the imaginary part (default 0.0)
"""
if imag == 0.0 and real == 0.0:
return complex_zero
...我并不是很感兴趣。原因:
- 我记得 pyCharm 中,默认的注释并不是这样的,说明标准并不是唯一的
- 具体使用什么标准,我觉得要 就事论事 ,比如 MkDocs 会帮我们自动地把注释编译成文档并发布在网上,因此我们想要使用 MkDocs 时,去学习 MkDocs 的规范便好

如上是 thu-ml/tianshou 源码,其注释使用 markdown 写的, 如果去访问说明文档,你会发现说明文档就是根据源代码注释自动生成的。
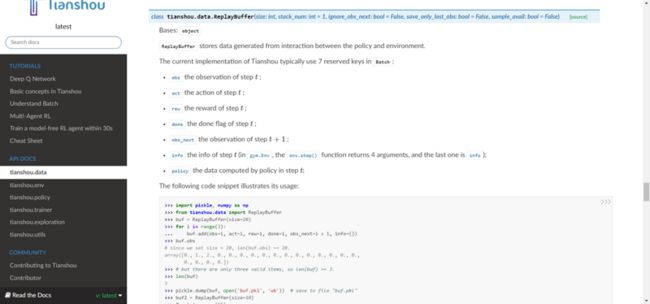
Amazing. 这才是“写代码的”该有的美德:懒惰,不做重复的动作,能自动化就自动化。
3/3 读规范文档不如多读好项目
最后,光说不练假把戏。
在我看来,多读优秀的代码、项目, 有意识地注意高手的书写规范和其怎么安排项目结构,意义远比只读 pep 8 要大很多。