xml-了解 XML 架构
了解 XML 架构
发布日期: 4/13/2004 | 更新日期: 4/13/2004Aaron Skonnard
DevelopMentor
2003 年 3 月
适用于:
类型系统
XML 架构定义语言 (XSD)
Web 服务开发
本页内容
摘要:XML 架构预计将在未来的 XML 处理中扮演核心角色,尤其是在 Web 服务领域,它将作为构建更高级别抽象的重要基础之一。本文详细地说明了如何使用 XML 架构定义语言。(22 页打印页)
简介
1 + 2 = ?
在软件中,回答此类问题所需的信息是由类型系统来提供的。编程语言使用类型系统来简化生成优质代码的任务。类型系统定义了一组可供开发人员在其程序设计中选择使用的类型和操作。一个类型定义一个值空间,或者换句话说,定义一组可能的值。例如,如果上面的操作数被认为是数值类型,答案就可能是 3;但如果它们被认为是字符串型,答案就可能是 “12”,具体情况取决于 “+” 运算符是如何定义的。
类型系统的主要好处之一是,编译器可以使用它在运行前确定代码中是否包含错误,这样就避免了可能产生大量的错误。编译器还可以利用类型系统信息针对给定类型生成操作代码。另外,编译器和运行库都在很大程度上依赖类型系统来确定在使用某个特定类型时如何分配内存空间,这使得开发人员可以不关注这些单调乏味的工作。
许多语言和运行库还允许在运行时以编程方式检查类型信息。这就使开发人员能够考虑得多一点,提出关于类型特征的问题,并且做出基于相应答案的决定。这种在运行时检查类型信息的技术通常被称为反射。在今天的主流编程环境(例如,Microsoft? .NET 框架和 Java)中,反射扮演了重要角色,这有效地减少了开发人员在其代码中必须考虑的问题。在这些编程环境中,虚拟机(例如,公共语言运行库或 JVM)提供大多数程序所需的额外服务(例如,安全、垃圾回收、序列化、远程方法调用甚至是 Web 服务集成)。
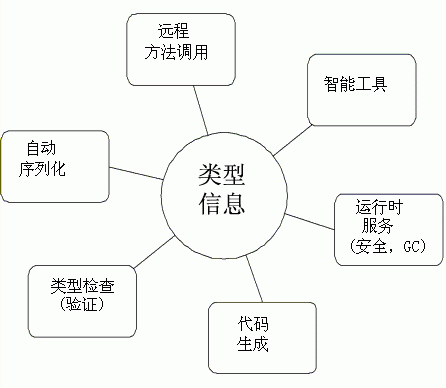
图 1. 类型信息的好处
一个定义完善的类型系统以及反射还能够创建更好的工具,以便与这种语言共同使用。开发人员已经能够快速适应许多事情,例如,Microsoft? Intellisense?、代码完成以及那些能够大大加速开发过程的方便的红色 Squiggle。大体说来,一个好的类型系统会提供许多有趣的好处(请参见图 1),其中的大部分好处是容易被当作理所当然、而没有时却让人倍感失落的那种。
XML 1.0 是一个缺乏智能类型系统的语言的典型示例。如果没有类型系统,则在 XML 1.0 文档中找到的信息只能被视为文本。这就要求开发人员事先知道“真正的类型”,以便他们在代码中执行必要的强制。
XML 架构定义语言 (XSD) 为 XML 处理环境提供了一种类型系统。在小容器中,XML 架构可以描述您要使用的类型。符合 XML 架构类型的 XML 文档通常是指实例 文档,这与类和对象间传统的面向对象的 (OO) 关系非常相似(请参见图 2)。这是一种跳离文档类型定义 (DTD) 的基本工作方式的概念切换,它可在映射到传统的编程语言或数据库类型系统时提供更大的灵活性。在这些环境中,XML 架构大大否决了 DTD 的使用。
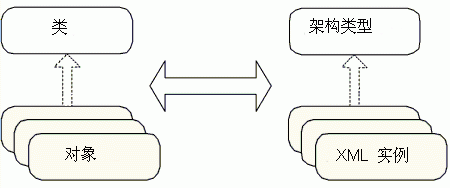
图 2. OO 与 XML 概念
XML 架构只有在一种完全以 XML 为中心的方式下,才能够提供图 1 所示的全部好处。包含 XML 架构类型信息的逻辑 XML 文档通常被称为后架构验证信息集 (PSVI)。PSVI 使得如下操作成为可能:像在其他编程环境中一样,在运行时执行基于 XML 架构的反射。总的说来,XML 架构预计将在未来的 XML 处理中扮演核心角色,尤其是在 Web 服务领域,它将作为构建更高级别抽象的重要基础之一。本文的剩余部分将更详细地介绍如何使用 XML 架构定义语言。
数据类型:值和词法空间
XML 架构提供了一个内置数据类型 清单,开发人员可以使用它来约束文本(有关帮助图,请参见 W3C XML Schema Part 2:Datatypes Web page)。所有这些类型都可以在 http://www.w3.org/2001/XMLSchema 命名空间中找到。每种类型都有一个定义好的值空间。类型的值空间仅仅是可用在给定类型的实例中的一组值。

图 3. 字节值空间
例如,XML 架构提供了一种名为字节的内置类型,它具有从 -128 到 127 的值空间。另一个示例是 XML 架构中的布尔类型,它的值空间非常简单,因为它只有以下两个值:真 和假。共有 44 种内置类型供您选择,每种都有不同的值空间以满足不同数据建模的需要。
图 4 阐释了许多内置类型都被定义为另外一种类型的值空间的子集,也称为通过限制派生。例如,字节型值空间是短整型值空间的子集,短整型值空间又是整型值空间的子集,而整型值空间又是长整型值空间的子集,等等。因此,基本集合论告诉我们,一种派生类型的实例也是它的任一祖先类型的有效实例。(严格地说,它们是 anySimpleType 本身的子集。)
尽管编程语言使用值空间信息来计算需要多大的内存来表示值,开发人员却极少需要担心将它们表示为文本的问题。然而,对于 XML,却不能忽视一个事实,那就是实例将很可能序列化为 XML 1.0 文件,这需要以词法形式表示值。如果每个 XML 架构处理器都独立地决定如何进行此操作,那么互操作性很快就会失去。因此,除了定义每种类型的值空间外,XML 架构还定义了它们所允许的词法表示形式。
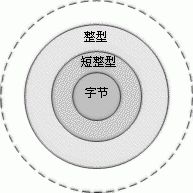
图 4. 类型子集
例如,布尔型的真值可以表示为 “true” 或 “1”,而布尔型的假值可以表示为 “false” 或 “0”。双精度型值 10 可以表示为 “10”、“10.0” 或 “10.0000”,甚至可表示为 “0.01E3”。而日期型的“2003 年 1 月 1 日”就可以用词法格式表示为“2003-01-01”。如果使任何类型的词法格式(以及任何可能的变化形式)都符合标准,开发人员就可以不考虑代码实际序列化方式的复杂性,而专门处理代码中的值。
在命名空间中定义类型
除了提供内置类型外,大部分编程语言还允许开发人员定义他们自己的类型,它们通常被称为用户定义类型 (UDT)。在定义 UDT 时,大部分编程语言还允许您用命名空间来限定它们,以便使它们不会与其他恰好与其具有相同名称的 UDT 相混淆。有关 XML 命名空间如何工作的详细信息,请参阅了解 XML 命名空间。图 5 显示了一个 C# 命名空间定义和一个与之类似的 XML 架构定义。正如您所看到的一样,XML 架构还支持在命名空间内定义类型。
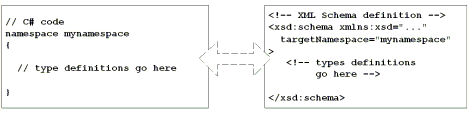
图 5. 在命名空间中定义类型
xsd:schema 元素确定命名空间中的内容范围,而targetNamespace 属性指定命名空间的名称。例如,下面的 XML 架构模板定义一个新的名为 http://example.org/publishing 的命名空间:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://example.org/publishing" xmlns:tns="http://example.org/publishing" > <!-- type definitions --> <xsd:simpleType name="AuthorId"> <!-- define value space details here --> ... </xsd:simpleType> <xsd:complexType name="AuthorType"> <!-- define structural details here --> ... </xsd:complexType> <!-- global element/attribute declarations --> <xsd:element name="author" type="tns:AuthorType"/> <xsd:attribute name="authorId" type="tns:AuthorId"/> ... </xsd:schema>
位于 xsd:schema 元素内的所有内容(作为直接子级)都被认为是全局的,因此它们会自动与目标命名空间相关联。在上例中,http://example.org/publishing 命名空间中共有 4 个元素:AuthorId、AuthorType、author 和 authorId。因此,无论何时在架构内引用其中的一个元素,都必须使用命名空间限定的名称。
为了使用命名空间限定的名称,还将需要另外一个命名空间声明,该声明映射到架构的 targetNamespace 值。上面显示的 “tns” 命名空间声明的作用就在于此。因此,我无论何时需要引用我在架构中定义的内容,都可以在名称前加上 “tns” 前缀,如本例所示。
您可以在 xsd:schema 元素内定义两种类型:简单类型(使用 xsd:simpleType)和复杂类型(使用 xsd:complexType)。简单类型只能分配给纯文本元素和属性,因为它们并不定义结构,而是定义值空间。具有附加结构的元素(例如,带有属性或子元素的元素)必须定义为复杂类型。
除了定义类型,您还可以在架构内定义全局元素(使用 xsd:element)和属性(使用 xsd:attribute),并为它们指定类型。在上例中,我定义了一个名为 author 的全局元素和一个名为 authorId 的全局属性。因为这些构造也是全局的,所以当我在实例文档中使用它们时,必须通过目标命名空间对其进行限定。下面的 XML 文档包含前面定义的 author 元素的一个实例:
<x:author xmlns:x="http://example.org/publishing"> <!-- structure determined by complexType definition --> ... </x:author>
下面的 XML 文档包含全局 authorId 属性:
<!-- authorId value constrained by simpleType definition --> <publication xmlns:x="http://example.org/publishing" x:authorId="333-33-3333"/>
也可以使用 http://www.w3.org/2001/XMLSchema-instance 命名空间中的 type 属性为实例文档中的元素显式指定类型。这个命名空间包含少数只能用在实例文档中的属性。使用类型属性类似于在一些编程语言中的类型间进行强制转换。下例为 genericId 元素(尚未在架构中定义)显式指定 AuthorId 类型:
<genericId xmlns:x="http://example.org/publishing" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="tns:AuthorId" >333-33-3333</genericId>
请注意,AuthorId 和我们指定给上面显示的全局 authorId 属性的类型是相同的。这表明您能够为属性或纯文本元素指定简单类型以约束它们的值。同样,一定要注意到,用于指定类型的 xsi:type 技术只能应用于元素,而不能应用于属性。
定义简单类型
大多数编程语言只允许开发人员将多种内置类型排列为某种结构化类型,而不允许开发人员定义新的具有用户定义的值空间的简单类型。在这一点上,XML 架构有所不同,因为它允许用户定义其各自的自定义简单类型,这些简单类型的值空间是预定义的内置类型的子集。
像前面显示的那样,您可以使用 xsd:simpleType 元素定义新的简单类型。在 xsd:simpleType 元素内,可以指定一个您希望限制(使用 xsd:restriction 元素)其值空间的基类型。在 xsd:restriction 元素内,您可以通过限制一个或多个方面 来准确指定希望如何来限制基类型。例如,下面的简单类型使用 xsd:minInclusive 和 xsd:maxInclusive 方面约束 xsd:double 和 xsd:date 值空间:
... <xsd:simpleType name="RoyaltyRate"> <xsd:restriction base="xsd:double"> <xsd:minInclus
下面的文档包含上面定义的元素的有效实例:
<x:rate xmlns:x="http://example.org/publishing">17.5</x:rate>
<x:publicationDate xmlns:x="http://example.org/publishing" >2003-06-01</x:publicationDate>
XML 架构定义了可用于每种类型的方面(请参阅表 1)。大多数方面都不能应用于所有类型(一些方面仅对某些类型有意义)。大多数方面限制了类型的值空间,而模式方面则限制了类型的词法空间。对于值空间和词法空间来说,限制两者中的任一者都会间接地限制另外一个。先前的示例约束了基类型的值空间,而接下来的示例使用正则表达约束了字符串的词法空间:
...
<xsd:simpleType name="SSN">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{3}-\d{2}-\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="PublisherAssignedId">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\d{2}-\d{8}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:simpleType name="Phone">
<xsd:restriction base="xsd:string">
<xsd:pattern value="\(\d{3}\)\d{3}-\d{4}"/>
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="authorId" type="tns:SSN"/>
<xsd:element name="pubsAuId" type="tns:PublisherAssignedId"/>
<xsd:element name="phone" type="tns:Phone"/>
...
下面的文档包含上面定义的元素的有效实例:
<x:authorId xmlns:x="http://example.org/publishing" >123-45-6789</x:authorId>
<x:pubsAuId xmlns:x="http://example.org/publishing" >01-23456789</x:pubsAuId>
<x:phone xmlns:x="http://example.org/publishing" >(801)390-4552</x:phone>
只有与正则表达式(在模式方面中指定)相匹配的字符串才被认为是给定类型的有效实例。
方面元素 说明xsd:enumeration
指定一个该类型必须匹配的固定值。
xsd:fractionDigits
指定小数点右侧十进制位数的最大值。
xsd:length
指定基于字符串的类型中的字符数量、基于二进制的类型中的八位字节数量或者基于列表的类型中的项数量。
xsd:maxExclusive
指定该类型的值空间的上限(不包括上限)。
xsd:maxInclusive
指定该类型的值空间的上限(包括上限)。
xsd:maxLength
指定基于字符串的类型中字符的最大数量、基于二进制的类型中的八位字节的最大数量或者基于列表的类型中项的最大数量。
xsd:minExclusive
指定该类型的值空间的下限(不包括下限)。
xsd:minInclusive
指定该类型的值空间的下限(包括下限)。
xsd:minLength
指定基于字符串的类型中字符的最小数量、基于二进制的类型中的八位字节的最小数量或者基于列表的类型中项的最小数量。
xsd:pattern
基于正则表达式指定一个该类型必须匹配的模式。
xsd:totalDigits
为从数字派生的类型指定十进制位数的最大值。
xsd:whiteSpace
指定空白正常化规则。
表 1. 方面
另一个有趣的方面是 xsd:enumeration,它允许将值空间约束为枚举值列表。下面的示例将 xsd:NMTOKEN 的值空间约束为四个特定的枚举值:
... <xsd:simpleType name="PublicationType"> <xsd:restriction base="xsd:NMTOKEN"> <xsd:enumeration value="Book"/> <xsd:enumeration value="Magazine"/> <xsd:enumeration value="Journal"/> <xsd:enumeration value="Online"/> </xsd:restriction> </xsd:simpleType> <xsd:element name="pubType" type="tns:PublicationType"/> ...
下面的文档包含上面定义的元素的有效实例:
<x:pubType xmlns:x="http://example.org/publishing" >Online</x:pubType>派生元素 说明
xsd:restriction
新类型是现有类型的限制,这表示新类型具有一组范围更窄的合法值。
xsd:list
新类型是另一个简单类型的、用空白分隔的列表。
xsd:union
新类型是两个或更多其他简单类型的联合。
表 2. 简单类型的构造技巧
除了限制类型的值空间外,还可以构造新的作为其他简单类型的列表 或联合 的简单类型。为此,要使用 xsd:list 或 xsd:union 元素,而不使用 xsd:restriction(请参阅表 2)。在使用 xsd:list 时,实质上是在从指定的值空间定义一个用空白分隔的值列表。值得提醒的是,在使用 xsd:list 或 xsd:union 时,不像使用 xsd:restriction 时那样具有派生层次结构,因此在这些情况下不能应用类型兼容性。下例将名为 AuthorList 的新类型定义为 SSN 值列表。
... <xsd:simpleType name="AuthorList"> <xsd:list itemType="tns:SSN"/> </xsd:simpleType> <xsd:element name="authors" type="tns:AuthorList"/> ...
下面的文档包含 authors 元素的有效实例:
<x:authors xmlns:x="http://example.org/publishing" >111-11-1111 222-22-2222 333-33-3333 444-44-4444</x:authors>
对于 xsd:union 来说,是在创建一种可将多个值空间组合到一个新的值空间中的新类型。联合类型的实例可以是所指定的任何值空间中的值。例如,下面的名为 AuthorId 的类型将 SSN 值空间与 PublisherAssignedId 值空间组合在一起:
... <xsd:simpleType name="AuthorId"> <xsd:union memberTypes="tns:SSN tns:PublisherAssignedId"/> </xsd:simpleType> <xsd:element name="authorId" type="tns:AuthorId"/> ...
下面的每个文档都显示 authorId 元素的一个有效实例:
<x:authorId xmlns:x="http://example.org/publishing" >111-11-1111</x:authorId>
<x:authorId xmlns:x="http://example.org/publishing" >22-22222222</x:authorId>
XML 架构对用户定义类型(以及更具体的自定义值空间/词法空间)的支持是这种语言更强大的方面之一。由于大多数编程语言不提供该支持,因此开发人员不得不在他们的应用程序代码中处理此类问题(通常是通过属性的 setter)。这种可定义能够完全满足您的需求的自定义值空间/词法空间的功能使错误处理和验证代码问题降低一个难度级别。
... <xsd:complexType name="AuthorType"> <!-- compositor goes here --> </xsd:complexType> ...
定义复杂类型
XML 架构允许将不同的简单类型(或值空间)排列为结构(也称作复杂类型)。可以使用 xsd:complexType 元素在架构的目标命名空间内定义新的复杂类型,如下所示:
xsd:complexType 元素包含所谓的合成器,合成器描述类型内容的合成,因此又被称作该元素的内容模型。XML 架构定义了三个可用在复杂类型定义中的合成器:xsd:sequence、xsd:choice 和 xsd:all(请参阅表 3)。
合成器中包含粒子,而粒子中包括诸如其他合成器、元素声明、通配符和模型组之类的内容。属性声明并不被视为粒子,因为它们不重复。因此,属性声明不会放在合成器内,而是放在复杂类型定义结尾处的合成器后面。
合成器 定义xsd:sequence
所包含粒子的有序序列。
xsd:choice
可供选择的所包含粒子。
xsd:all
以任何顺序排列的所有所包含粒子。
表 3. 复杂类型合成器
元素声明 (xsd:element) 可能是最常用的粒子。下面的名为 AuthorType 的 complexType 定义了一个由两个子元素和一个属性(此处的子元素和属性分属于不同的简单类型)组成的有序序列:
... <xsd:complexType name="AuthorType"> <!-- compositor goes here --> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="phone" type="tns:Phone"/> </xsd:sequence> <xsd:attribute name="id" type="tns:AuthorId"/> </xsd:complexType> <xsd:element name="author" type="tns:AuthorType"/> ...
在 xsd:complexType 元素内声明的元素和属性被视为该复杂类型的局部 元素和属性。局部元素和属性只能在定义它们的上下文内使用。这就引发了一个有趣的问题:在实例文档中,局部元素/属性是否需要由命名空间来限定。因为局部元素和属性总是包含由目标命名空间限定的祖先元素(通常是全局元素),所以人们可以认为让局部元素和属性也由命名空间限定并不是必要的。这与大多数编程语言中的工作方式相类似 - 如果您在一个命名空间中定义了一个类,则只有该类的名称由命名空间限定,而它的局部成员则不会被限定。
由于这个原因,在 XML 架构中,局部元素和属性在默认情况下应当不受限定。因此,author 元素的有效实例如下所示:
<x:author xmlns:x="http://example.org/publishing" id="333-33-3333" > <name>Aaron Skonnard</name> <phone>(801)390-4552</phone> </x:author>
然而,XML 架构允许使用 xsd:element/xsd:attribute 的 form 属性或者使用 xsd:schema 的 elementFormDefault/attributeFormDefault 属性,来显示控制给定的局部元素/属性是应当受限定还是不受限定,如下所示:
<xsd:schema xmlns:xsd="http://www.w3.org/2001/XMLSchema" targetNamespace="http://example.org/publishing" xmlns:tns="http://example.org/publishing" elementFormDefault="qualified" attributeFormDefault="qualified" > ... </xsd:schema>
在有了此架构之后,下面的实例将被视为有效实例(而上面的实例将被视为无效实例):
<x:author xmlns:x="http://example.org/publishing" x:id="333-33-3333" > <x:name>Aaron Skonnard</x:name> <x:phone>(801)390-4552</x:phone> </x:author>
在大多数情况下,只要实例与架构相符合,那么对局部元素使用哪种命名空间样式就无关紧要了。
您也可以使用 ref 属性在一个复杂类型内引用全局元素/属性声明,如下所示:
... <!-- global definitions --> <xsd:attribute name="id" type="tns:AuthorId"/> <xsd:element name="name" type="xsd:string"/> <xsd:element name="author" type="tns:AuthorType"/>
由于 id 和 name 是全局元素,因此它们在实例文档中总是需要受到限定。使用 “ref” 可以指定全局元素同样可以用在 AuthorType μ?上下文内,但这并没有改变它需要受到限定这一事实。phone 元素仍然是在局部定义的,这意味着,在实例中,它可能需要也可能不需要受到限定,具体情况取决于所使用的形式。因此,假设 elementFormDefault="unqualified",有效实例将如下所示:
<x:author xmlns:x="http://example.org/publishing" x:id="333-33-3333" > <x:name>Aaron Skonnard</x:name> <phone>(801)390-4552</phone> </x:author>
下面是一个稍微复杂点的示例,它使用嵌套的复杂类型、其他合成器和重复粒子:
<xsd:complexType name="AddressType"> <xsd:all> <xsd:element name="street" type="xsd:string"/> <xsd:element name="city" type="xsd:string" minOccurs="0"/> <xsd:element name="state" type="tns:State" minOccurs="0"/> <xsd:element name="zip" type="tns:Zip"/> </xsd:all> </xsd:complexType> <xsd:complexType name="PublicationsListType"> <xsd:choice maxOccurs="unbounded"> <xsd:element name="book" type="xsd:string"/> <xsd:element name="article" type="xsd:string"/> <xsd:element name="whitepaper" type="xsd:string"/> </xsd:choice> </xsd:complexType> <xsd:complexType name="AuthorType"> <xsd:sequence> <xsd:choice> <xsd:element name="name" type="xsd:string"/> <xsd:element name="fullName" type="xsd:string"/> </xsd:choice> <xsd:element name="address" type="tns:AddressType"/> <xsd:element name="phone" type="tns:Phone" minOccurs="0" maxOccurs="unbounded"/> <xsd:element name="recentPublications" type="tns:PublicationsListType"/> </xsd:sequence> <xsd:attribute name="id" type="tns:AuthorId"/> </xsd:complexType> <xsd:element name="author" type="tns:AuthorType"/> ...
在本例中,AuthorType 包含由另一个合成器和一个选项组成的序列,其后还有三个元素声明。一些元素属于其他由用户定义的复杂类型(AddressType 和 PublicationsListType),这些复杂类型可在该类型内有效地定义嵌套结构。此选项意味着是允许 name 元素还是允许 fullName 元素出现在该位置。最后,AddressType 中的 all 合成器指出元素的顺序是可以忽略的。
另请注意,phone 元素声明使用 minOccurs 和 maxOccurs 元素指定出现约束。出现约束可以应用于复杂类型中的任何粒子。每个出现约束的默认值是 1,这意味着给定的粒子必须在指定的位置出现一次。指定 minOccurs="0" 会使给定的粒子成为可选粒子,而指定 maxOccurs="unbounded" 会允许粒子重复无限多次。您也可以根据自己的喜好指定任意限制,例如,minOccurs="3" maxOccurs="77"。总的来说,针对合成器使用出现约束是适用于整个组的(请注意,PublicationsListType 将出现约束应用于某个选项)。下面举例说明新的 AuthorType 的有效实例:
<x:author xmlns:x="http://example.org/publishing" id="333-33-3333" > <name>Aaron Skonnard</name> <address> <street>123 Main</street> <zip>84043</zip> </address> <phone>801-729-0924</phone> <phone>801-390-4555</phone> <phone>801-825-3925</phone> <recentPublications> <whitepaper>Web Service Abstractions</whitepaper> <book>Essential XML Quick Reference</book> <article>Web Services and DataSets</article> <article>Understanding SOAP</article> <book>Essential XML</book> </recentPublications> </x:author>
在默认情况下,复杂类型具有闭合式内容模型。这就意味着只允许指定的粒子出现在实例中。然而,XML 架构允许使用所谓的通配符 定义开放式内容模型。在复杂类型内使用 xsd:any 意味着任何元素都可以出现在那个位置上,这可有效地使它成为事先无法预知的内容的占位符。还可以使用 xsd:anyAttribute 来为属性定义占位符。
<xsd:complexType name="AuthorType"> <!-- compositor goes here --> <xsd:sequence> <xsd:element name="name" type="xsd:string"/> <xsd:element name="phone" type="tns:Phone"/> <xsd:any minOccurs="0" maxOccurs="unbounded"/> </xsd:sequence> <xsd:anyAttribute/> </xsd:complexType> <xsd:element name="author" type="tns:AuthorType"/>
下面阐释了上面定义的 author 元素的一个有效实例:
<x:author xmlns:x="http://example.org/publishing" xmlns:aw="http://www.aw.com/legal/contracts" aw:auId="01-3424383" > <!-- explicitly defined by the complexType --> <name>Aaron Skonnard</name> <phone>801-825-3925</phone> <!-- extra elements that replace wildcard --> <aw:contract xmlns:aw="http://www.aw.com/legal/contracts"> <title>Essential Web Services Quick Reference</title> <deadline>2003-06-01</deadline> </aw:contract> ... </x:author>
在使用通配符时,也可以约束内容实际所来自的命名空间。xsd:any 和 xsd:anyAttribute 都附带了一个可选的命名空间属性,该属性可以包含表 4 中所示的任一个值。这使得有关通配符替换来自何处的内容变得非常具体。
属性值 允许使用的元素##any
来自任何命名空间的任何元素
##other
非 targetNamespace 命名空间中的任何元素
##targetNamespace
targetNamespace 中的任何元素
##local
任何非限定元素(不属于命名空间)
ns 字符串列表
来自列出的命名空间中的任何元素
表 4. 通配符的命名空间属性
使用通配符,也可以指定在验证过程中架构处理器应该如何处理通配符内容。xsd:any 和 xsd:anyAttribute 都附带了一个 processContents 属性,该属性可以指定下列三个值之一:lax、strict 和 skip。这个值告诉处理器是否应当针对替换通配符的内容执行架构验证。Strict 指示处理器必须 针对内容执行验证,Lax 指示处理器应当 在架构信息可用时执行验证,而 skip 指示处理器不能 执行架构验证。
让我们看一个使用这些属性的示例。SOAP 1.1 的架构实际上使用通配符以及这两个属性来定义 soap:Header 和 soap:Body 元素的结构:
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:tns="http://schemas.xmlsoap.org/soap/envelope/" targetNamespace="http://schemas.xmlsoap.org/soap/envelope/" > ... <xs:element name="Header" type="tns:Header" /> <xs:complexType name="Header" > <xs:sequence> <xs:any namespace="##other" minOccurs="0" maxOccurs="unbounded" processContents="lax" /> </xs:sequence> <xs:anyAttribute namespace="##other" processContents="lax" /> </xs:complexType> <xs:element name="Body" type="tns:Body" /> <xs:complexType name="Body" > <xs:sequence> <xs:any namespace="##any" minOccurs="0" maxOccurs="unbounded" processContents="lax" /> </xs:sequence> <xs:anyAttribute namespace="##any" processContents="lax" /> </xs:complexType> ... </xs:schema>
根据该架构,soap:Header 可以包含零个或更多元素,以及来自非 targetNamespace 命名空间中的任意数量的属性,而 soap:Body 可以包含零个或更多元素,以及来自任意命名空间中的任意数量的属性。在这两种情况下,只有当架构信息在运行时可用时,才应当执行验证(例如,lax 验证)。因为事先无法预知什么内容将被置于 soap:Header 或 soap:Body元素中,因此通配符提供了一种为 XML 消息处理定义灵活的开放式框架的方法。
定位和管理架构
在这一点上总出现的问题之一是,XML 架构处理器在运行时如何定位给定的实例文档所需的架构定义。XML 架构处理器切断示例文档的命名空间以定位相应的架构,但 XML 架构规范并未明确指定处理器应当如何进行此操作。大多数处理器都允许您事先加载一个包含您将要使用的所有架构的架构缓存。然后,在运行时,您只需将处理器指向架构缓存,以便它能够有效地查找特定实例所需的架构。
XML 架构还定义了一种在实例文档中提供架构位置提示的方法。这是通过 xsi:schemaLocation 属性实现的,如下所示:
<x:author xmlns:x="http://example.org/publishing" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://example.org/publishing pubs.xsd" >
xsi:schemaLocation 属性允许您提供一个由空格分隔的、包含命名空间名称和 URI 位置对(指出到哪里去查找特定的架构文件)的列表。但是,这同样只是一个提示,处理器可能不会在那里实际查看是否还有一个更高效的检索机制。
小结
XML 架构为 XML(能够提供许多功能强大的服务)提供了一个表达类型系统。我们已经涵盖了 XML 架构定义的基础,包括简单类型定义和复杂类型定义。简单类型定义允许您为纯文本元素和属性定义自定义的值空间。另一方面,复杂类型定义允许您将简单类型排列为结构。
事实上,XML 架构的功能远比我们在这里所讨论到的多。例如,复杂类型定义支持通过扩展和限制进行派生,这就允许您以一种很好地映射到 OO 类层次结构的方式定义复杂类型层次结构。在构建好复杂类型层次结构之后,还可以在实例文档中使用替换技术。XML 架构还使 XML 架构定义能够贯穿到多个文件和命名空间之中,然后通过其被包括和/或导入,以便增加重用性并简化维护。这些更高级的话题还是留在将来的关于 XML 架构设计的文章中介绍吧。
有关 XML 架构的更多信息,请查看电子版的 Essential XML Quick Reference(可从网上免费下载)— XML 架构章节包含各个构造和数据类型的简化说明和示例。
参考
XML Schema Part 0:Primer
XML Schema Part 1:Structures
XML Schema Part 2:Datatypes
Essential XML Quick Reference