Python自然语言处理学习笔记(2):Preface 前言
Updated 1st:2011/8/5
Updated 2nd:2012/5/14 中英对照完成
Preface 前言
This is a book about Natural Language Processing. By “natural language” we mean a language that is used for everyday communication by humans; languages such as English, Hindi(印度语), or Portuguese(葡萄牙语). In contrast to artificial languages such as programming languages and mathematical notations, natural languages have evolved as they pass from generation to generation, and are hard to pin down(准确地说明) with explicit rules(明确的规则). We will take Natural Language Processing(自然语言处理)—or NLP for short—in a wide sense to cover(包含) any kind of computer manipulation of natural language. At one extreme(在一个极端上), it could be as simple as counting word frequencies to compare different writing styles. At the other extreme,NLP involves “understanding” complete human utterances(言语), at least to the extent of being able to give useful responses to them(至少达到可以给予有用的回答的程度).
这是一本关于自然语言处理的书。所谓“自然语言”,是指人们日常交流中使用的语言,例如英语、印地语、葡萄牙语等。与编程语言和数学符号等人工语言相比,自然语言随着人类的繁衍而不断演化,因而很难用明确的规则来准确地说明。从广义上来讲,“自然语言处理”( Natural Language Processing 简称 NLP ) 包含所有用计算机对自然语言进行操作的方法 ,既包含了通过计数词频来比较不同的写作风格的简单手段,又包含了完全 “ 理解 ” 人类言语的终极目标,至少可以达到对人的言语给予有用回答的程度。
Technologies based on NLP are becoming increasingly widespread. For example, phones and handheld computers support predictive text(文本预测) and handwriting recognition(手写识别); web search engines give access to information locked up(锁定) in unstructured text(就是说,可以在非结构化的文本里获得信息); machine translation allows us to retrieve texts written in Chinese and read them in Spanish. By providing more natural human-machine interfaces, and more sophisticated(高级的) access to stored information, language processing has come to play a central role in the multi-lingual information society(多语言的信息社会).
基于NLP的技术正在迅速地普及到社会生活的各方面中。例如:手机和手持电脑可以支持输入法联想提示和手写识别;网络搜索引擎能在非结构化文本中搜索到信息;机器翻译可以为人们提供中文翻译成西班牙文的服务 。通过提供设计良好的人机界面和更高级的存储信息访问方式, 语言处理正在这个多语言交流的信息社会中发挥着重要的作用。
This book provides a highly accessible introduction to the field of NLP. It can be used for individual study or as the textbook for a course on natural language processing or computational linguistics, or as a supplement(补充) to courses in artificial intelligence, text mining(文本数据挖掘), or corpus linguistics(语料库语言学). The book is intensely practical(非常具有实用性), containing hundreds of fully worked examples and graded exercises.
本书为读者提供了一本易于理解的自然语言处理领域入门指南 。可以用于个人自学,也可以作为自然语言处理或计算语言学课程的教科书,或是人工智能 、文本挖掘 、语料库语言学课程的补充读物。本书的实践性很强,包括几百个实际可用的例子和分级练习。
The book is based on the Python programming language together with an open source library called the Natural Language Toolkit (NLTK). NLTK includes extensive soft-ware, data, and documentation, all freely downloadable from http://www.nltk.org/.Distributions are provided for Windows, Macintosh, and Unix platforms. We strongly encourage you to download Python and NLTK, and try out(尝试) the examples and exercises along the way.
本书基于 Python 编程语言 及 其上的一个名为自然语言工具包 ( Natural Language Toolk it , 简称 NLTK ) 的开源库 。 NLTK 包含 大量的软件 、 数据和文档 , 所有这些都可以从 http://www.nltk.org/ 免费下载 。 NLTK 的发行版本支持 Windows 、 Macintosh 和 Unix 平台 。 我们强烈建议你下载 Python 和 NLTk ,亲自动手来尝试书中的例子和练习。
Audience 读者
NLP is important for scientific, economic, social, and cultural reasons. NLP is experiencing rapid growth as its theories and methods are deployed(部署) in a variety of new language technologies. For this reason it is important for a wide range of people to have a working knowledge of NLP. Within industry, this includes people in human-computer interaction, business information analysis(商业信息分析), and web software development. Within academia, it includes people in areas from humanities computing(人文计算) and corpus linguistics through to computer science and artificial intelligence. (To many people in academia, NLP is known by the name of “Computational Linguistics.计算语言学”) This book is intended for(目的在于) a diverse(不同的) range of people who want to learn how to write programs that analyze written language, regardless of previous programming experience:
从科学、经济、社会和文化的角度来看,NLP研究是重要的。目前, NLP 技术正在迅速成长,很多NLP理论和方法被应用于许多新的语言技术中。因此,对很多行业的人来说掌握 NLP 的应用知识十分重要 。在工业界,包括了从事人机交互、商业信息分析、web软件开发的程序员和工程师;在学术界,包括了从人文计算学、语料库语言学到计算机科学和人工智能领域的研究人员 (在学术界,很多人把NLP 称为“ 计算语言学 ”)。本书旨在帮助所有想要学习如何编写程序分析书面语言的人,而且不需要先前具有编程经验 :
New to programming? 初学编程?
The early chapters of the book are suitable for readers with no prior knowledge of programming(先前没有任何编程知识的童鞋), so long as(只要) you aren’t afraid to tackle(处理) new concepts and develop new computing skills. The book is full of examples that you can copy and try for yourself, together with hundreds of graded exercises. If you need a more general introduction to Python, see the list of Python resources at http://docs.python.org/.
本书的最初几章适合没有编程经验的读者,只要你不惧怕应对新概念和学习新的计算机技能。 书中具有上百个例子和分级练习, 你可以复制下来并且亲自尝试一下。如果你需要一个更一般性的 Python 介绍,参见Python 官网的文档资源列表 http://docs.python.org/
New to Python? 初学Python?
Experienced programmers can quickly learn enough Python using this book to get immersed(专注于) in natural language processing. All relevant Python features are carefully explained and exemplified, and you will quickly come to appreciate Python’s suitability for this application area(你很快就会欣赏Python用于NLP领域的适用性). The language index will help you locate relevant discussions in the book.
有经验的程序员可以很快地掌握书中涉及到的 Python 语法,因为可以专注于自然语言处理。所有涉及到的 Python 特性都进行了详细地解释和举例说明 ,你很快就会体会到 Python是多么地合适地用于NLP应用领域。
Already dreaming in Python? 已经熟悉Python?
Skim(略读) the Python examples and dig into(钻研) the interesting language analysis material that starts in Chapter 1. You’ll soon be applying your skills to this fascinating domain.
你可以略读 Python 的例子,然后从第一章开始去钻研有趣的语言分析材料。很快就可以在这个引人入胜的领域中一展身手。
Emphasis 强调
This book is a practical introduction to NLP. You will learn by example, write real programs, and grasp(理解) the value of being able to test an idea through implementation. If you haven’t learned already, this book will teach you programming. Unlike other programming books, we provide extensive illustrations and exercises from NLP. The approach we have taken is also principled, in that we cover the theoretical underpinnings(基础材料) and don’t shy(畏缩) away from careful linguistic and computational analysis. We have tried to be pragmatic(务实的) in striking a balance(打破平衡) between theory and application, identifying the connections and the tensions(张力). Finally, we recognize that you won’t get through this unless it is also pleasurable, so we have tried to include many applications and examples that are interesting and entertaining, and sometimes whimsical(古怪的).
Note that this book is not a reference work(工具书). Its coverage of Python and NLP is selective, and presented in a tutorial style. For reference material, please consult the substantial quantity of searchable resources available at http://python.org/ and http://www.nltk.org/.
This book is not an advanced computer science text. The content ranges from introductory to intermediate, and is directed at readers who want to learn how to analyze text using Python and the Natural Language Toolkit. To learn about advanced algorithms implemented in NLTK, you can examine the Python code linked from http://www.nltk.org/, and consult the other materials cited in this book.
本书是一本NLP的应用入门。你将通过例子学习,编写实际程序,体会到能够通过实践验证自己想法的价值。如果你还没有学过编程,本书将教你如何编程。与其他编程书籍不同的是,我们提供了丰富的 NLP 领域的实例和练习。我们撰写本书的方法也遵循了相关原理,因此本书涵盖了理论的基础材料并且不回避详细的语言和计算分析 。我们在理论与实践之间寻求平衡进行了尝试,来确定它们之间的联系与边界。最终,我们认识到只有读者能从书中品味到乐趣才能做完这些例子和习题 ,因此我们竭尽所能囊括了许多有趣的应用和例子,甚至有些异想天开。
请注意本书并不是一本工具书。本书讲述的Python和NLP均是精心挑选的,并通过教程的形式展现。关于参考材料,请查阅http://python.org/和http://www.nltk.org/ ,那里有大量可搜索的资源。
本书不是高级计算机科学课本。书中的涉及内容属于初级和中级,目标读者是那些想要学习如何使用 Python 和自然语言工具包进行文本分析的人。若希望学习NLTK中实现的高级算法,你可以浏览 http://www.nltk.org/的Python代码,并且查看本书引用的其他材料。
What You Will Learn 你将学到什么
By digging into the material presented here, you will learn:
通过钻研本书,你将学到:
• How simple programs can help you manipulate and analyze language data, and how to write these programs
简单的程序如何可以帮助你处理和分析语言数据,以及如何编程这些程序
• How key concepts from NLP and linguistics are used to describe and analyze language
NLP和语言学中的关键概念是如何用来描述和分析语言的
• How data structures and algorithms are used in NLP
数据结构和算法如何在NLP中使用
• How language data is stored in standard formats, and how data can be used to evaluate the performance of NLP techniques
语言数据是如何存储在标准格式中,以及数据如何用来评价NLP技术的性能
Depending on your background, and your motivation for being interested in NLP, you will gain different kinds of skills and knowledge from this book, as set out in Table P-1.
根据读者知识背景和学习 NLP 的动机,将从本书中获得不同种类的技能和知识,详情见表 P-1 :
Table P-1. Skills and knowledge to be gained from reading this book, depending on readers’ goals and background
| Goals |
Background in arts and humanities 艺术人文背景 |
Background in science and engineering 理工背景 |
| Language analysis 语言分析 |
Manipulating large corpora, exploring linguistic models, and testing empirical claims 操作大型语料库,设计语言模型,测试经验假设 |
Using techniques in data modeling, data mining, and knowledge discovery to analyze natural language. 运用数据建模,数据挖掘和知识发现技术分析自然语言 |
| Language technology 语言技术 |
Building robust systems to perform linguistic tasks with technological applications. 构建鲁棒系统的技术应用来执行语言学任务 |
Using linguistic algorithms and data structures in robust language processing software. 在鲁棒的语言处理软件中使用语言学算法和数据结构 |
Organization 章节安排
The early chapters are organized in order of conceptual difficulty, starting with a practical introduction to language processing that shows how to explore interesting bodies of text using tiny Python programs (Chapters 1–3).
This is followed by a chapter on structured programming (Chapter 4) that consolidates(巩固) the programming topics scattered(分散) across the preceding chapters.
After this, the pace picks up(速度加快), and we move on to a series of chapters covering fundamental topics in language processing: tagging, classification, and information extraction (Chapters 5–7).
The next three chapters look at ways to parse a sentence, recognize its syntactic structure(句法结构), and construct representations of meaning (Chapters 8–10).
The final chapter is devoted to linguistic data and how it can be managed effectively (Chapter 11).
The book concludes with an After word, briefly discussing the past and future of the field.
本书前几章按照概念的难易程度进行编排。首先从一个语言处理的实际应用的介绍开始,讲述了如何使用少量 Python 程序探索有趣的文章正文( 1 -3 章 )。接着是结构化程序设计章节 ( 第4 章 ),用于巩固散布在前面几章中的编程要点。之后 ,加快了速度,我们使用了一连串的章节用来讲述语言处理的基本主题:标注、分类和信息提取( 5-7 章 )。接下来三章关注于句子解析、句法结构识别和句意表示构建(8-10 章)。最后一章讲述了语言数据以及如何进行有效地管理(第11章)。结尾处的后记简要讨论了 NLP 的过去和未来的领域。
Within each chapter, we switch between different styles of presentation. In one style, natural language is the driver(驱动). We analyze language, explore linguistic concepts, and use programming examples to support the discussion. We often employ(使用) Python constructs that have not been introduced systematically, so you can see their purpose before delving(钻研) into the details of how and why they work. This is just like learning idiomatic(惯用的) expressions in a foreign language: you' re able to buy a nice pastry(点心) without first having learned the intricacies(复杂) of question formation. In the other style of presentation, the programming language will be the driver. We’ll analyze programs, explore algorithms, and the linguistic examples will play a supporting role.
我们在每一章中在两种不同的叙述风格间切换。一种风格是以自然语言驱动的。我们分析语言,探索语言学概念;并使用编程例子来支持论据。我们经常会使用尚未系统介绍的 Pytho结构, 这样你可以在钻研这些程序如何运作并且为何如此运作的细节前明白它们的用途。 就像学习一门外语的惯用表达式一样,你能够买到好吃的糕点而不必先学会复杂的提问句型 。 在另一种叙述风格中,将以编程语言为驱动。我们将分析程序,探索算法,并且语言学例子将会用来支撑。
Each chapter ends with a series of graded exercises(分级练习), which are useful for consolidating the material. The exercises are graded according to the following scheme(体制):
○ is for easy exercises that involve minor modifications to supplied code samples or other simple activities;
◑ is for intermediate exercises that explore an aspect of the material in more depth, requiring careful analysis and design;
● is for difficult, open-ended(开放式的) tasks that will challenge your understanding of the material and force you to think independently (readers new to programming should skip these).
每章结尾都有一系列分级练习 , 用于巩固学到的知识 。 练习按照如下的标准分级 :
○ 初级练习:对范例代码作稍微修改等简单的练习;
◑ 中级练习:深入探索材料的一个方面 , 需要仔细的分析和设计 ;
● 高级练习 : 困难的、开放式的任务,挑战你对材料的理解并迫使你独立思考解决的方案(初学编程者应该跳过这些 ) 。
Each chapter has a further reading section and an online “extras” section at http://www.nltk.org/, with pointers to more advanced materials and online resources. Online versions of all the code examples are also available there.
每一章都有深入的阅读环节和一个放在 http://www.nltk.org/上在线“额外”环节,用来介绍更深入的材料和一些网络资源。所有实例代码都可从网上下载。
Why Python? 选择Python的理由?需要理由吗?不需要理由吗?...
Python is a simple yet powerful programming language with excellent functionality for processing linguistic data. Python can be downloaded for free from http://www.python.org/ . Installers are available for all platforms.
Python 是一种简单但功能强大的编程语言,非常适合处理语言数据。 Python 可以从 http://www.python.org/ 免费下载,能够在各种平台上安装运行。
Here is a four-line Python program that processes file.txt and prints all the words ending in ing:
这里有一个4行的Python程序,可以操作 file.txt 文件并且输出所有后缀是“ing”的词。
... for word in line.split():
... if word.endswith( ' ing ' ):
... print word
This program illustrates some of the main features of Python. First, whitespace is used to nest lines of code; thus the line starting with if falls inside the scope of the previous line starting with for; this ensures that the ing test is performed for each word. Second, Python is object-oriented; each variable is an entity that has certain defined attributes and methods. For example, the value of the variable line is more than a sequence of characters. It is a string object that has a “method”(or operation) called split()[string的split()方法,默认使用空格分句] that we can use to break a line into its words. To apply a method to an object, we write the object name, followed by a period, followed by the method name, i.e., line.split(). Third, methods have arguments expressed inside parentheses. For instance, in the example, word.endswith('ing') had the argument 'ing' to indicate that we wanted words ending with ing and not something else. Finally—and most importantly—Python is highly readable, so much so that it is fairly easy to guess what this program does even if you have never written a program before.
这段程序说明了Python的一些主要特征。首先,使用空白符号缩进代码,从而使if后面的代码都在前面一行for语句的范围之内;这保证了检查单词是否以“ing”结尾的测试对所有单词都进行。第二, Python是面向对象语言。每一个变量都是包含特定属性和方法的对象。例如:变量“line”的值不仅仅是一行字符串,它是一个string对象,包含用来把字符串分割成词的split()方法(或叫操作、函数)。我们在对象名称后面写句号(点)再写方法名称就可以调用对象的一个方法,即line.splie()。第三,方法的参数写在括号内。例如:上面的例子中的 word.endswith('ing'), 参数“ing”表示我们需要找的是“ing”结尾的词而不是别的结尾的词。最后也是最重要的,Python的可读性如此之强以至于可以相当容易的猜出程序的功能,即使你以前从未写过一行代码。
We chose Python because it has a shallow(浅的) learning curve, its syntax and semantics are transparent(易懂的), and it has good string-handling functionality. As an interpreted language, Python facilitates(促进) interactive exploration. As an object-oriented language, Python permits data and methods to be encapsulated(封装) and re-used easily. As a dynamic language, Python permits attributes to be added to objects on the fly(实时的), and permits variables to be typed dynamically, facilitating rapid development. Python comes with an extensive standard library, including components for graphical programming, numerical processing, and web connectivity.
我们选择Python的原因是因为它的学习曲线比较平缓,文法和语义都很清晰,具有良好的处理字符串的功能。作为解释性语言,Python便于交互式编程。作为面向对象语言, Python使得数据和方法可以被方便地封装和重用。作为动态语言, Python 允许属性等到程序运行时才被添加到对象,允许变量自动类型转换,提高开发效率。 Python 自带强大的标准库,包括图形编程、数值处理和网络连接等组件。
Python is heavily used in industry, scientific research, and education around the world. Python is often praised for the way it facilitates productivity, quality, and maintainability of software(促进了软件的生产效率,质量和可维护性). A collection of Python success stories is posted at http://www.python.org/about/success/ .NLTK defines an infrastructure that can be used to build NLP programs in Python. It provides basic classes for representing data relevant to natural language processing; standard interfaces for performing tasks such as part-of-speech tagging, syntactic parsing, and text classification; and standard implementations for each task that can be combined to solve complex problems.
Python在世界各地的工业、科研、教育领域应用广泛。 它因为提高了软件的生产效率、质量和可维护性而备受称赞。http://www.python.org/about/success/ 中列举了许多使用 Python 的成功案例。NLTK 定义了一个用 Python 进行 NLP 编程的基础架构。它提供了表示自然语言处理相关数据的基本类;给出了词性标注、文法分析 、文本分类等任务的标准接口;以及用于每个任务的标准实现,可以相结合用于解决复杂问题。
NLTK comes with extensive documentation. In addition to this book, the website at http://www.nltk.org/ provides API documentation that covers every module, class, and function in the toolkit, specifying parameters and giving examples of usage. The website also provides many HOWTOs with extensive examples and test cases, intended for users, developers, and instructors.
NLTK 自带大量文档。作为本书的补充,http://www.nltk.org/ 网站提供的API文档涵盖工具包中每一个模块、类和函数,详细说明了各种参数,还给出了用法示例。该网站还为广大用户、开发人员和导师提供了很多包含大量的例子和测试用例的HOWTO。
Software Requirements 软件安装需求
To get the most out of this book, you should install several free software packages.Current download pointers and instructions are available at http://www.nltk.org/.
为了充分利用好本书,你应该安装一些免费的软件包。 http://www.nltk.org/ 上有这些软件包当前的下载链接和安装说明。
Python (推荐2.7)
The material presented in this book assumes that you are using Python version 2.4 or 2.5. We are committed to porting NLTK to Python 3.0 once the libraries that NLTK depends on have been ported.
本书的例子都假定你正在使用 Python 2.4 或 2.5 版本。我们承诺一旦 NLTK 的依赖库支持 Python3.0 ,就将NLTK移植到 Python 3.0 。
NLTK (得先装Pyyaml,yaml一种类似于XML的东东)
The code examples in this book use NLTK version 2.0. Subsequent releases of NLTK will be backward-compatible.
本书的代码示例使用 NLTK 2.0 版本。 NLTK 的后续版本将是向后兼容的。
NLTK-Data
This contains the linguistic corpora that are analyzed and processed in the book.
NumPy (recommended 基本的数值计算还有高级点的Scipy,科学计算)
This is a scientific computing library with support for multidimensional arrays and linear algebra, required for certain probability, tagging, clustering, and classification tasks.
这是一个科学计算库,支持多维数组和线性代数 ,在某些计算概率 、标记 、聚类和分类任务中用到。
Matplotlib (recommended 类似Matlab)
This is a 2D plotting library for data visualization, and is used in some of the book’s code samples that produce line graphs and bar charts.
NetworkX (optional )
This is a library for storing and manipulating network structures consisting of nodes and edges. For visualizing semantic networks, also install the Graphviz library.
这是一个用于存储和操作由节点和边组成的网络结构的函数库 。 可视化语义网络还需要安装 Graphviz 库。
Prover9 (optional )
This is an automated theorem prover for first-order and equational logic, used to support inference in language processing.
这是一个用于一阶和逻辑方程式的自动理论证明器,用于支持语言处理中的推理。
Natural Language Toolkit (NLTK)
NLTK was originally created in 2001 as part of a computational linguistics course in the Department of Computer and Information Science at the University of Pennsylvania(宾州大学). Since then it has been developed and expanded with the help of dozens of contributors. It has now been adopted in courses in dozens of universities, and serves as the basis of many research projects. Table P-2 lists the most important NLTK modules.
NLTK 创建于 2001 年 ,最初是宾州大学计算机与信息科学系计算语言学课程的一部分 。从此以后,在数十名贡献者的帮助下不断发展壮大 。如今,它已被几十所大学的课程所采纳 ,并作为许多研究项目的基础。表 P -2 列出了 NLTK 的一些最重要的模块。
Table P-2. Language processing tasks and corresponding NLTK modules with examples of functionality
| 语言处理任务 |
NLTK模块 |
功能描述 |
| Accessing corpora 访问语料库 |
nltk.corpus |
Standardized interfaces to corpora and lexicons 语料库和词典的标准接口 |
| String processing 字符串处理 |
nltk.tokenize, nltk.stem |
Tokenizers, sentence tokenizers, stemmers 分词,句子分词,词干提取 |
| Collocation discovery 搭配发现 |
nltk.collocations |
t-test, chi-squared, point-wise mutual information |
| Part-of-speech tagging 词类标识 |
nltk.tag |
n-gram, backoff, Brill, HMM, TnT |
| Classification 分类 |
nltk.classify, nltk.cluster |
Decision tree, maximum entropy, naive Bayes, EM, k-means |
| Chunking 分块 |
nltk.chunk |
Regular expression, n-gram, named entity |
| Parsing 解析 |
nltk.parse |
Chart, feature-based, unification, probabilistic, dependency |
| Semantic interpretation 语义解释 |
nltk.sem, nltk.inference |
Lambda calculus, first-order logic, model checking |
| Evaluation metrics 指标评测 |
nltk.metrics |
Precision, recall, agreement coefficients |
| Probability and estimation 概率和估计 |
nltk.probability |
Frequency distributions, smoothed probability distributions |
| Applications 应用 |
nltk.app, nltk.chat |
Graphical concordancer(图形关键词排序), parsers, WordNet browser, chatbots
|
| Linguistic fieldwork 语言学领域的工作 |
nltk.toolbox |
Manipulate data in SIL Toolbox format 处理SIL工具箱格式中的数据 |
NLTK was designed with four primary goals in mind:
记住NLTK 设计中的四个最主要目标:
Simplicity 简易性
To provide an intuitive framework along with substantial building blocks, giving users a practical knowledge of NLP without getting bogged down(陷入困境) in the tedious(冗长乏味的) house-keeping usually associated with processing annotated(注释) language data
提供一个直观的框架和大量模块,使用户获取 NLP的应用 知识而不必陷入像标注语言数据那样繁琐的事务中。
Consistency 一致性
To provide a uniform framework with consistent interfaces and data structures, and easily guessable method names
提供一个具有一致的接口和数据结构并且方法名称容易被猜到的统一的框架。
Extensibility 可扩展性
To provide a structure into which new software modules can be easily accommodated, including alternative implementations and competing approaches to the same task
提供一种结构,新的软件模块包括同一个任务中的不同的实现和相互冲突的方法都可以方便添加进来。
Modularity 模块性
To provide components that can be used independently without needing to understand the rest of the toolkit.
提供可以独立使用而与工具包的其他部分无关的组件。
Contrasting with these goals are three non-requirements—potentially useful qualities that we have deliberately avoided. First, while the toolkit provides a wide range of functions, it is not encyclopedic(如百科全书的); it is a toolkit, not a system, and it will continue to evolve with the field of NLP. Second, while the toolkit is efficient enough to support meaningful(有意义的) tasks, it is not highly optimized for runtime performance(没有为运行性能高度优化); such optimizations often involve more complex algorithms(这样的优化常常包含了更复杂的算法), or implementations in lower-level programming languages such as C or C++(或者是在C或C++等更低级的编程语言中实现). This would make the software less readable and more difficult to install. Third, we have tried to avoid clever programming tricks(避开巧妙的编程技巧), since we believe that clear implementations are preferable to ingenious yet indecipherable ones(因为我们相信清楚直白的实现比巧妙却可读性差的方法好).
对比上述目标,我们回避了工具包的潜在实用性 。 首先,虽然工具包提供了广泛的工具,但它不是面面俱全的。它是一个工具包而不是一个系统,它将会随着 NLP 领域一起演化。第二,虽然这个工具包的效率足以支持实际的任务,但它运行时的性能还没有高度优化。这种优化往往涉及更复杂的算法或使用 C或C++等较低一级的编程语言来实现。这将影响工具包的可读性且更难以安装。第三,我们试图避开巧妙的编程技巧,因为我们相信清楚直白的实现比巧妙却可读性差的方法好。
这段可以解释在豆瓣的NLTK小组中有人鄙视其代码写得“很差”的原因。
For Instructors 指导老师参阅
自然语言处理一般是在本科或研究生层次的高年级开设的为期一个学期的课程。很多教师都发现,在如此短的时间里涵盖理论和实践 两 个方面是十分困难的。 有些课程注重理论而排挤实践练习,剥夺了学生编写程序自动处理语言 带来的 挑战和兴奋感。另一些课程仅仅教授语言学编程而不包含任何重要的NLP内容。最初开发 NLTK 就是为了解决这个问题,使在一个学期里同时教授大量理论和实践成为可能,无论学生事先有没有编程经验。
算法和数据结构在所有 NLP 教学大纲中都十分重要。它们本身可能非常枯燥,而 NLTK 提供的交互式图形用户界面能一步一步看到算法过程,使它们变得鲜活。大多说 NLT K组件都有一个无需用户输入任何数据就能执行有趣的任务的示范性例子。学习本书的一个有效的方法就是交互式重现书中的例子,把它们输入到 Python 会话控制台,观察它们做了些什么,修改它们去探索试验或理论问题。
本书包含了数百个练习,可作为学生作业的基础。最简单的练习涉及用指定的方式修改已有的程序片段来回答一个具体的问题。另一个极端,NLTK 为研究生水平的研究项目提供了一个灵活的框架,包括所有的基本数据结构和算法的标准实现,几十个广泛使用的数据集(语料库)的接口,以及一个灵活可扩展的体系结构。NLTK网站上还有其他资源支持教学中使用 NLTK 。
我们相信本书是唯一为学生提供在学习编程的环境中学习 NLP 的综合性框架。各个章节和练习通过 NLTK 紧密耦合,并将各章材料分割开,为学生(即使是那些以前没有编程经验的学生)提供一个实用的NLP的入门指南。学完这些材料后,学生将准备好尝试一本更加深层次的教科书,例如:《语音和语言处理》,作者是 Jurafsky和Martin(Prentice Hall出版社,2008年) 。
本书介绍编程概念的顺序与众不同。以一个重要的数据类型 :字符串列表( 链表 )开始,然后介绍重要的控制结构如推导和条件式等。这些概念允许我们在一开始就做一些有用的语言处理。有了这样做的冲动,我们回过头来系统的介绍一些基础概念,如字符串,循环,文件等。这样的方法同更传统的方法达到了同样的效果而不必要求读者自己已经对编程感兴趣。
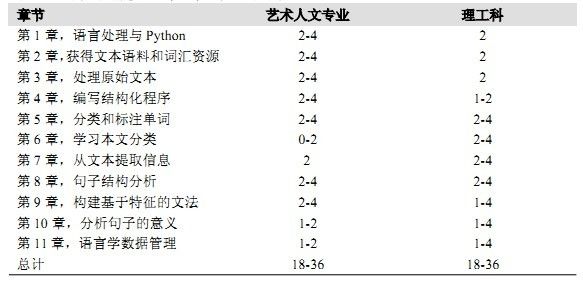
表 P-3 列出了两个课程计划表。第一个适用于艺术人文专业,第二个适用于理工科 。 其他的课程计划应该涵盖前 5 章 ,然后把剩余的时间投入单独的领域 , 例如 : 文本分类 ( 第 6 、7 章 ) 、文法(第 8 、9 章 ) 、语义(第 10 章)或者语言数据管理(第 11 章 ) 。
表 P-3. 课程计划建议;每一章近似的课时数
Conventions Used in This Book 本书约定(和OReilly出的其他动物书一样)
The following typographical conventions are used in this book:
Bold
Indicates new terms. 表示新术语
Italic
Used within paragraphs to refer to linguistic examples, the names of texts, and URLs; also used for filenames and file extensions(文件扩展名).
Constant width 等宽
Used for program listings(程序列表), as well as within paragraphs to refer to program elements such as variable or function names, statements, and keywords; also used for program names.
Constant width italic
Shows text that should be replaced with user-supplied values or by values determined by context; also used for metavariables(元变量) within program code examples.
 This icon signifies a tip, suggestion, or general note.
This icon signifies a tip, suggestion, or general note.
![]() This icon indicates a warning or caution.
This icon indicates a warning or caution.
Using Code Examples 使用代码例子
This book is here to help you get your job done. In general, you may use the code in this book in your programs and documentation. You do not need to contact us for permission unless you' re reproducing a significant portion of the code. For example,writing a program that uses several chunks of code from this book does not require permission. Selling or distributing a CD-ROM of examples from O’Reilly books does require permission. Answering a question by citing this book and quoting example code does not require permission. Incorporating a significant amount of example code from this book into your product' s documentation does require permission.
We appreciate, but do not require, attribution. An attribution usually includes the title, author, publisher, and ISBN. For example: “Natural Language Processing with Python, by Steven Bird, Ewan Klein, and Edward Loper. Copyright 2009 Steven Bird, Ewan Klein, and Edward Loper, 978-0-596-51649-9.”If you feel your use of code examples falls outside fair use or the permission given above, feel free to contact us at [email protected].
最后附上这三位帅哥的图,LOL
