数据分析利器:XGBoost算法最佳解析

作者:symonxiong,腾讯 CDG 应用研究员
XGBoost是一种经典的集成式提升算法框架,具有训练效率高、预测效果好、可控参数多、使用方便等特性,是大数据分析领域的一柄利器。在实际业务中,XGBoost经常被运用于用户行为预判、用户标签预测、用户信用评分等项目中。XGBoost算法框架涉及到比较多数学公式和优化技巧,比较难懂,容易出现一知半解的情况。由于XGBoost在数据分析领域实在是太经典、太常用,最近带着敬畏之心,对陈天奇博士的Paper和XGBoost官网重新学习了一下,基于此,本文对XGBoost算法的来龙去脉进行小结。
本文重点解析XGBoost算法框架的原理,希望通过本文能够洞悉XGBoost核心算法的来龙去脉。对于XGBoost算法,最先想到的是Boosting算法。Boosting提升算法是一种有效且被广泛使用的模型训练算法,XGBoost也是基于Boosting来实现。Boosting算法思想是对弱分类器基础上不断改进提升,并将这些分类器集成在一起,形成一个强分类器。简而言之,XGBoost算法可以说是一种集成式提升算法,是将许多基础模型集成在一起,形成一个很强的模型。这里的基础模型可以是分类与回归决策树CART(Classification and Regression Trees),也可以是线性模型。如果基础模型是CART树(如图1所示),比如第1颗决策树tree1预测左下角男孩的值为+2,对于第1颗决策树遗留下来的剩余部分,使用第2颗决策树预测值为+0.9,则对男孩的总预测值为2+0.9=2.9。
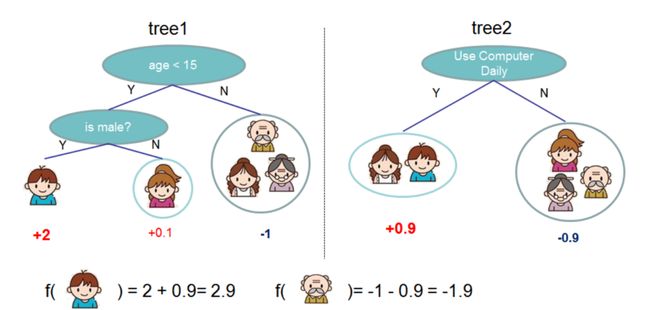 图1.基于二叉树的XGBoost模型
图1.基于二叉树的XGBoost模型
XGBoost算法框架可以分为四个阶段来理解(如图2所示)。第一个阶段,如何构造目标函数? 在进行优化求解时,首先需要构造目标函数,有了目标函数才能进行优化求解。这种思路和LR模型(Logistic Regression)是一致。在LR模型中,首先,对于回归问题构造平方项损失,对于分类问题构造最大似然损失作为目标函数,然后基于构造好的目标函数,才会考虑采用梯度下降算法进行优化求解,比如随机梯度下降、Mini-Batch批量梯度下降、梯度下降等。在这个阶段,我们可以得到XGBoost的基本目标函数结构。
第二个阶段,目标函数优化求解困难,如何对目标函数近似转换? 在第一个阶段得到的基本目标函数较为复杂,不是凸函数,没法使用连续性变量对目标函数直接优化求极值。因此,使用泰勒级数对目标函数进行展开,对目标函数规整、重组后,将目标函数转换为关于预测残差的多项式函数。
第三个阶段,如何将树的结构引入到目标函数中? 第二个阶段得到的多项式目标函数是一个复合函数。被预测的残差和模型复杂度还是未知的函数,需要对这两个函数进行参数化表示,即将决策树的结构信息通过数学符号表示出来。在第三个阶段,在树的形状确定情况下,可以优化求解出局部最优解。
第四个阶段,如何确定树的形状,要不要使用贪心算法? 如何在模型空间里面寻找最优的决策树形状,这是一个NP-Hard问题,我们很难对可能存在的树结构全部罗列出来,尤其在特征个数很多情况下。因此,在这里需要使用贪心算法来求得局部最优解。
 图2.XGBoost算法构建逻辑
图2.XGBoost算法构建逻辑
1.如何构造目标函数?
当使用多棵树来预测时,假设已经训练了 棵树,则对于第 个样本的(最终)预测值为:
在公式1中, 表示对 个样本的预测值, 属于 集合范围内, 表示通过第 棵树对第 个样本进行预测,比如第1棵树预测值为 ,第2棵树预测值为 ,依次类推,将这些树的预测值累加到一起,则得到样本的最终预测值 。因此,如果要得到样本的最终预测值,需要训练得到 棵树。
如果要训练得到 棵树,首先需要构造训练的目标函数(如公式2所示)。在构建模型时,不仅需要考虑到模型的预测准确性,还需要考虑到模型的复杂程度,既准确又简单的模型在实际应用中的效果才是最好的。因此,目标函数由两部分构成,第一部分表示损失函数,比如平方损失、交叉熵损失、折页损失函数等。第一部分表示 个样本总的损失函数值。因为在这里通过样本预测值 和样本真实值 的比较,可以计算出针对样本 的模型预测损失值 。这里可以暂时先不用考虑损失函数的具体形式,因为这里的损失函数,可以统一表示回归与分类问题的损失函数形式。
公式2的第二部分表示正则项,是用来控制模型的复杂度,模型越复杂,惩罚力度越大,从而提升模型的泛化能力,因为越复杂的模型越容易过拟合。XGBoost的正则化思路跟 模型中加 / 正则化思路一致,不同的地方在于正则化项具体物理含义不同。在这里 表示第 棵树的复杂度,接下来的问题是如何对树的复杂度进行参数化表示,这样后面才能进行参数优化。
在损失函数中 ,是有很多个模型(决策树)共同参与,通过叠加式的训练得到。如图2所示,训练完第一颗树 后,对于第一棵树没有训练好的地方,使用第二颗树 训练,依次类推,训练第 个棵树,最后训练第 颗树 。当在训练第 棵树时,前面的第1棵树到第 颗树是已知的,未知的是第 棵树,即基于前面构建的决策树已知情况下,构建第 棵树。
 图3.XGBoost叠加式训练
图3.XGBoost叠加式训练
对于样本 ,首先初始化假定第0棵树为 ,预测值为 ,然后在第0棵树基础上训练第1棵树,得到预测值 ,在第1棵树基础上训练第2颗树,又可以得到预测值 ,依次类推,当训练第 棵树的时候,前面 棵树的总预测值为 ,递推训练具体过程如下所示:
根据XGBoost的递推训练过程,每棵决策树训练时会得到样本对应的预测值,根据样本预测值和真实值比较,可以计算得到模型预测损失值。又因为训练所得的每棵决策树都有对应的结构信息,因此可以得到每棵决策树的复杂度 。根据这些信息,可以对目标函数公式2进行简化,得到公式3。
在公式3中, 表示训练样本个数, 为 颗决策树累加的预测值, 为 颗决策树总的复杂度,在训练第 颗决策树时,这两个东西是已知的,即在对目标函数进行求最小值优化时候, 和 为已知。因此,将常数项 拿掉,得到公式4作为XGBoost的目标函数。
2.目标函数优化困难,如何对函数近似转换?
在公式4中,已经得到了需要优化的目标函数,这个目标函数已经是简化后的函数。对于公式4,没法进行进一步优化。为了解决目标函数无法进行进一步优化,XGBoost原文是使用泰勒级数展开式技术对目标函数进行近似转换,即使用函数的1阶、2阶、3阶... 阶导数和对应的函数值,将目标函数进行多项式展开,多项式阶数越多,对目标函数的近似程度越高。这样做的好处是便于后面优化求解。
令,,带入到目标函数公式4,得到基于二阶泰勒展开式的函数(如公式5所示),其中,。
在训练第 颗树时,目标函数(公式5)中, , 、 是已知的。因此,可以将已知常数项 去掉,得到进一步简化后的目标函数(公式6)。 、 分别表示第 颗决策树的损失函数的1阶、2阶导数。前面 颗决策树预测后,通过 、 将前面第 颗决策树的预测损失信息传递给第 颗决策树。在公式6中,第 颗树的预测函数 、树复杂度函数 对于我们来说,仍然都是未知的,因此需要将其参数化,通过参数形式表示出来,才能进行下一步的优化求解。
3.如何将树结构引入到目标函数中?
接下来的问题是如何对函数 、 进行参数化表示。首先,对于叶子权重函数 ,如图4所示决策树,有1号、2号、3号叶子节点,这三个叶子节点对应的取值分别为15,12,20,在1号叶子节点上,有{1,3}两个样本,在2号叶子节点上,有{4}一个样本,在3号叶子节点上,有{2,5}两个样本。在这里,使用 来表示决策树的叶子权重值,三个叶子节点对应的叶子权重值为 、 、 。对于样本 落在决策树叶子节点的位置信息,使用 表示, 表示样本1落在第1个叶子节点上, 表示样本1落在第3个叶子节点上, 表示样本4落在第2个叶子节点上。
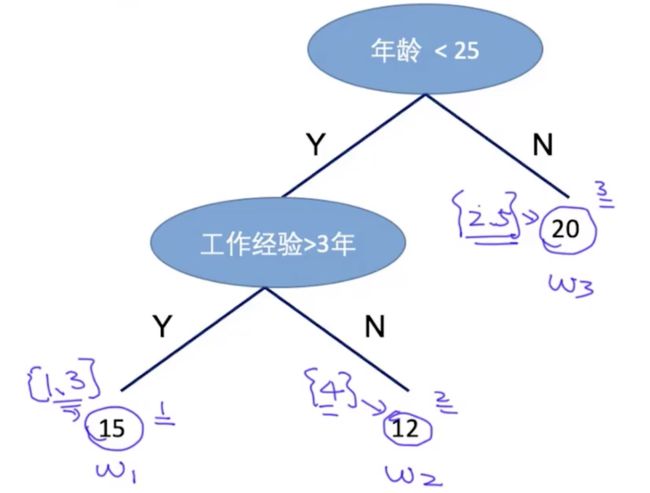 图4.XGBoost决策树结构
图4.XGBoost决策树结构
对于第 颗树的叶子权重函数 ,根据叶子权重值和样本所在叶子的位置信息,即可确定函数 。因此,我们引入决策树叶子权重值 和样本所在叶子的位置信息 两个变量,将其参数化表示成 。然而, 是一个函数,作为 的下标是不利于优化求解。因此,这里需要将 转化为 形式。 是根据样本落在叶子节点的位置信息直接遍历计算损失函数。 是从叶子节点的角度,对每个叶子节点中的样本进行遍历计算损失函数,其中, 表示树的叶子节点。假设 ,即 表示有哪些样本落在第j个叶子节点上,比如 表示样本{1,3}落在叶子节点1上, 表示样本{4}落在叶子节点2上, 表示样本{2,5}落在叶子节点3上(如上文图4所示)。在这里强调一下,将 转换为 形式,是可以从数学公式推到得到(比如下式)。根据样本所在叶子节点位置,计算所有样本的一阶损失得到第一行等式,其中, 表示样本 的一阶损失, 表示样本 对应的叶子节点, 表示叶子节点 对应的叶子权重值。
对于模型复杂度, 表示第 颗树的复杂度。在决策树里面,如果要降低树的复杂度,在训练决策树时,可以通过叶子节点中样本个数、树的深度等控制决策树的复杂度。在XGBoost中,是通过叶子节点个数、树的深度、叶子节点值来控制模型复杂度。XGBoost中的决策树是分类与回归决策树CART(Classification and Regression Trees)。由于CART是二叉树,控制叶子节点个数等同于控制了树的深度。因此,可以使用叶子节点个数来评估树的复杂度,即叶子节点个数越多(树的深度越深),决策树结构越复杂。对于叶子节点值,由于叶子节点值越大,相当于样本预测值分布在较少的几颗决策树的叶子节点上,这样容易出现过拟合。如果叶子节点值越小,相当于预测值分布在较多的决策树叶子节点上,每颗决策树参与预测其中的一小部分,过拟合的风险被分散。因此,叶子节点值越大,模型越容易过拟合,等同于决策树的复杂度越高。综合起来,如公式7所示,使用叶子节点个数 、叶子节点值 评估第 颗决策树的复杂度,其中 、 为超参数。如果希望叶子个数尽量少,则将 值尽量调大,如果希望叶子权重值尽量小,则将 尽量调大。
将 和公式7带入目标函数(公式6)中,可以得到参数化的目标函数(公式8)。在公式8中,在训练第 颗决策树时, 和 这两部分是已知, 为超参数。令 , ,对公式8进行调整,此时得到目标函数是关于 的一元二次抛物线,是目标函数最终的参数化表示形式。抛物线是有极值,对抛物线求极值可以直接套用抛物线极值公式,求解很方便。
基于公式8,对目标函数关于 求导,可以求得树的叶子节点 最优的权重值,如公式9所示。
将等式9带入到公式8中,计算得到树的目标损失值(如等式10),该等式表示决策树损失分数 ,分数越小,说明树的预测准确度越高、复杂度越低。
4.如何确定树的形状?
这里需要注意到一点,树的叶子节点最优解 和损失函数极小值 是在树的形状给定后的优化求解。因此,如果要求得叶子节点最优解和损失函数极小值,首先需要确定树的形状。如何寻找树的形状?最直接的方式是枚举所有可能的形状,然后计算每种形状的损失函数 ,从中选择损失函数最小的形状作为模型训练使用。这样在树的形状确定后,就可以对叶子节点值和损失函数值进行优化求解。这种方式在实际应用中一般不会采用,因为当样本的特征集很大时,树的形状个数是呈指数级增加,计算这些形状树对应损失函数 需要消耗大量的计算资源。
为了寻找树的形状,我们一般使用贪心算法来简化计算,降低计算的复杂度。贪心算法是在局部寻找最优解,在每一步迭代时,选择能使当前局部最优的方向。XGBoost寻找树的形状的思路和传统决策树模型建立树的思路一致。比如传统决策树在进行节点分割时,基于信息熵,选择信息熵下降最大的特征进行分割;对于XGBoost树模型,基于损失函数,选择能让损失函数下降最多的特征进行分割。如图5所示,虚线框是已经构造好的树形状,如果需要在蓝色节点做进一步分裂,此时需要按照某种标准,选择最好的特征进行分割。在这里,XGBoost使用损失函数下降最大的特征作为节点分裂。
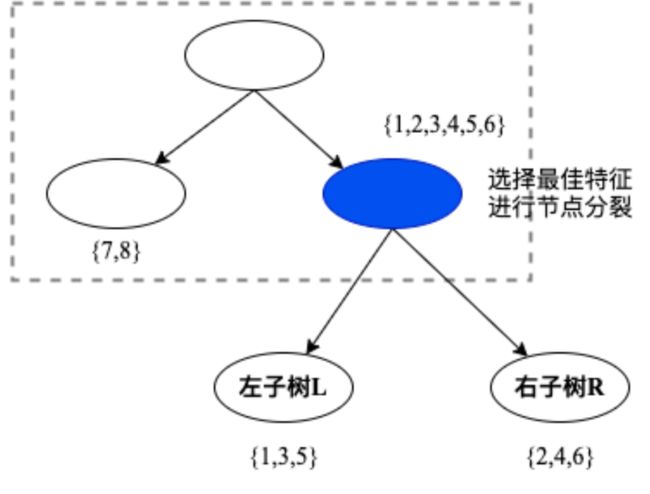 图5.XGBoost树节点最佳分割点
图5.XGBoost树节点最佳分割点
根据公式10,可以计算到蓝色节点在分裂前和分裂后的的损失函数值: 。两式相减,则得到特征如果作为分裂节点时,所能带来的损失函数下降值大小。因此,依据如下等式,选择能使 最大的特征作为分裂节点。
5.其它常见问题
关于XGBoost的常见经典问题,这类问题对于深入理解XGBoost模型很重要,因此,本文对此也进行了梳理小结。
(1) XGBoost为什么需要对目标函数进行泰勒展开?
根据XGBoost官网(如图6所示),目标损失函数之间存在较大的差别,比如平方损失函数、逻辑损失函数等。对目标函数进行泰勒展开,就是为了统一目标函数的形式,针对回归和分类问题,使得平方损失或逻辑损失函数优化求解,可以共用同一套算法框架及工程代码。另外,对目标函数进行泰勒展开,可以使得XGBoost支持自定义损失函数,只需要新的损失函数二阶可导即可,从而提升算法框架的扩展性。
 图6.XGBoost目标函数泰勒展开式官方解释
图6.XGBoost目标函数泰勒展开式官方解释
相对于GBDT的一阶泰勒展开,XGBoost采用二阶泰勒展开,可以更精准的逼近真实的损失函数,提升算法框架的精准性。另外,一阶导数描述梯度的变化方向,二阶导数可以描述梯度变化方向是如何变化的,利用二阶导数信息更容易找到极值点。因此,基于二阶导数信息能够让梯度收敛的更快,类似于牛顿法比SGD收敛更快。
(2) XGBoost如何进行采样?
XGBoost算法框架,参考随机森林的Bagging方法,支持样本采样和特征采样。由于XGBoost里没有交代是有放回采样,认为这里的样本采样和特征采样都是无放回采样。每次训练时,对数据集采样,可以增加树的多样性,降低模型过拟合的风险。另外,对数据集采样还能减少计算,加快模型的训练速度。在降低过拟合风险中,对特征采样比对样本采样的效果更显著。
样本采样(如图7所示),默认是 不进行样本采样。样本的采样的方式有两种,一种是认为每个样本平等水平,对样本集进行相同概率采样;另外一种认为每个样本是不平等,每个样本对应的一阶、二阶导数信息表示优先级,导数信息越大的样本越有可能被采到。
 图7.XGBoost样本采样
图7.XGBoost样本采样
特征采样(如图8所示),默认 对特征不进行采样。对特征的采样方式有三种,第一种是在建立每棵树时进行特征采样;第二种特征采样范围是在第一种的基础上,对于树的每一层级(树的深度)进行特征采样;第三种特征采样范围是在第二种的基础上,对于每个树节点进行特征采样。这三种特征采样方式有串行效果。比如,当第一、二、三种的特征采样比例均是0.5时,如果特征总量为64个,经过这三种采样的综合效果,最终采样得到的特征个数为8个。
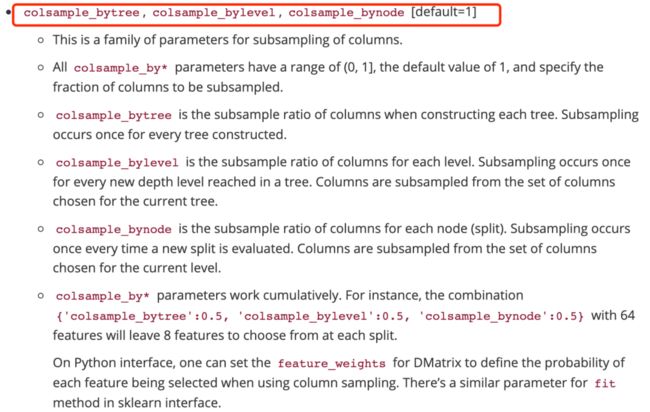 图7.XGBoost样本采样
图7.XGBoost样本采样
(3)XGBoost为什么训练会比较快?
XGBoost训练速度快,这个主要是工程实现优化的结果,具体的优化措施如下几点:第一、支持并行化训练。XGBoost的并行,并不是说每棵树可以并行训练,XGBoost本质上仍然采用Boosting思想,每棵树训练前需要等前面的树训练完成后才能开始训练。XGBoost的并行,指的是特征维度的并行。在训练之前,每个特征按特征值大小对样本进行预排序,并存储为Block结构(如图8所示),在后面查找特征分割点时可以重复使用,而且特征已经被存储为一个个Block结构,那么在寻找每个特征的最佳分割点时,可以利用多线程对每个Block并行计算。
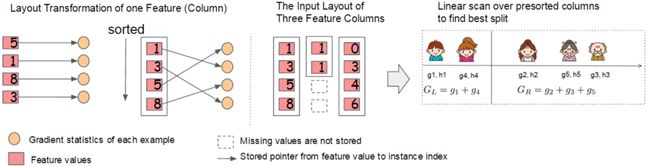 图8.样本排序
图8.样本排序
第二、采用近似算法技术,得到候选分位点。在构造决策树分裂节点时,当采用精确贪心算法穷举计算每个特征下的所有特征值增益,如果特征个数多、特征取值大,会造成较大的计算量。当样本数据量大时,特征值无法完全加载到内存中,计算效率低。对于分布式数据集,同样会面临无法将特征值全部加载到本地内存的问题。因此,基于这两个现实问题,采用近似直方图算法,将每个特征取值划分为常数个分位点,作为候选分割点,从中选择相对最优的分割点作为决策树分裂节点。
第三、缓存感知访问技术。对于有大量数据或者说分布式系统来说,不可能将所有的数据都放进内存里面。因此,需要将其放在外存上或者将数据分布式存储。但是会有一个问题,这样做每次都要从外存上读取数据到内存,这将会是十分耗时的操作。在XGBoost中,采用预读取的方式,将下一块将要读取的数据预先放进内存里面。这个过程是多开了一个线程,该线程与训练的线程独立并负责数据读取。此外,还要考虑Block的大小问题。如果设置最大的Block来存储所有样本在 特征上的值和梯度,Cache未必能一次性处理如此多的梯度做统计。如果设置过小的Block-size,这样不能充分利用多线程的优势。这样会出现训练线程已经训练完数据,但是预读取线程还没把数据放入内存或者cache中。经过测试,Block-size设置为2^16个特征值是效果最好。
第四、Blocks核外计算优化技术。为了高效使用系统资源,对于机器资源,除了CPU和内存外,磁盘空间也可以利用起来处理数据。为了实现这个功能,XGBoost在模型训练时,会将数据分成多个块并将每个块存储在磁盘上。在计算过程中,使用独立的线程将Block预提取到主内存缓冲区,这样数据计算和磁盘读取可以同步进行,但由于IO非常耗时,所以还采用了两种技术来改进这种核外计算。
Block Compression:块压缩,并且加载到主内存时由独立的线程进行解压缩。
Block Sharding:块分片,即将数据分片到多个磁盘,为每个磁盘分配一个线程,将数据提取到内存缓冲区,然后每次训练线程的时候交替地从每个缓冲区读取数据,有助于在多个磁盘可用时,增加读取的吞吐量。
除了这些技术,XGBoost的特征采样技术也可以提升计算效率。如果设定特征采样比例colsample_by* < 1.0,则在选择最佳特征分割点作为分裂节点时,特征候选集变小,挑选最佳特征分割点时计算量降低。
(4)XGBoost如何处理缺失值问题?
XGBoost的一个优点是允许特征存在缺失值。对缺失值的处理方式如图9所示: 在特征 上寻找最佳分割点时,不会对该列特征missing的样本进行遍历,而只对该特征值为non-missing的样本上对应的特征值进行遍历。对于稀疏离散特征,通过这个技巧可以大大减少寻找特征最佳分割点的时间开销。
在逻辑实现上,为了保证完备性,会将该特征值missing的样本分别分配到左叶子节点和右叶子节点,两种情形都计算一遍后,选择分裂后增益最大的那个方向(左分支或是右分支),作为预测时特征值缺失样本的默认分支方向。 如果在训练中没有缺失值而在预测中出现缺失,那么会自动将缺失值的划分方向放到右子节点。
 图9.XGBoost缺失值处
图9.XGBoost缺失值处
(5)XGBoost和GBDT的区别是什么?
XGBoost和GBDT都是基于Boosting思想实现。XGBoost可以认为是在GBDT基础上的扩展。两者的主要不同如下:基分类器:GBDT是以分类与回归决策树CART作为基分类器,XGBoost的基分类器不仅支持CART决策树,还支持线性分类器,此时XGBoost相当于带L1和L2正则化项的Logistic回归(分类问题)或者线性回归(回归问题)。导数信息:GBDT在优化求解时,只是用到一阶导数信息,XGBoost对代价函数做了二阶泰勒展开,同时用到一阶和二阶导数信息。另外,XGBoost工具支持自定义代价函数,只要函数可以一阶和二阶求导即可。正则项:XGBoost在代价函数里加入正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、每个叶子节点上输出的预测值的 模的平方和。正则项有利于降低模型的方差variance,使学习出来的模型更加简单,防止过拟合。GBDT的代价函数中是没有正则项。缺失值处理:对于特征的取值有缺失的样本,XGBoost可以自动学习出它的分裂方向。 另外,XGBoost还做了其它工程优化,包括特征值Block化、并行化计算特征增益、近似直方图算法、特征采样技术等
(6)如何使用XGBoost进行模型训练?
在使用XGBoost前,可以根据官网说明文档进行安装(下面有链接,这里不赘述)。本文采用的数据集是Kaggle平台房价预测开源数据集(地址如参考文章8所示)。值得说明的一点,在进行模型训练前,一般需要做数据清洗、特征工程、样本划分、模型参数调优这些过程。针对这些过程,本文在这里不展开细讲。在进行模型训练前,本文已经完成数据清洗、特征工程、模型参数调优过程,并得到最终用于模型训练的样本集和最优模型参数。如下代码,是使用XGBoost进行模型训练过程。
#### 导入数据分析基础包 #####
import pandas as pd
import matplotlib
import numpy as np
import scipy as sp
import IPython
from IPython import display
import sklearn
import random
import time
#### 导入训练样本 #####
# 样本集特征
X_train=pd.read_csv('./final_train.csv',sep='\t',index=None)
# 样本集标签
y_train=pd.read_csv('./final_y_train.csv',sep='\t',index=None)
### 导入算法模型和评分标准 ####
from sklearn import svm, tree, linear_model, neighbors, naive_bayes, ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
#Common Model Helpers
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
#Visualization
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
from pandas.plotting import scatter_matrix
#Configure Visualization Defaults
#%matplotlib inline = show plots in Jupyter Notebook browser
%matplotlib inline
mpl.style.use('ggplot')
sns.set_style('white')
pylab.rcParams['figure.figsize'] = 12,8
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression, ElasticNet
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import fbeta_score, make_scorer, r2_score ,mean_squared_error
from sklearn.linear_model import Lasso
from sklearn.svm import SVR
from xgboost import XGBRegressor
from sklearn.model_selection import KFold, cross_val_score, train_test_split
# 计算平方误差
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
# 模型:Xgboost
from sklearn.model_selection import GridSearchCV
best_reg_xgb = XGBRegressor(learning_rate= 0.01, n_estimators = 5000,
max_depth= 4, min_child_weight = 1.5, gamma = 0,
subsample = 0.7, colsample_bytree = 0.6,
seed = 27)
best_reg_xgb.fit(X_train, y_train)
pred_y_XGB = best_reg_xgb.predict(X_train)
#
print (rmsle(pred_y_XGB, y_train))
6.小结
本文从目标函数构建、目标函数优化、树结构信息表示、树形状确定等四部分,对XGBoost算法框架进行解析。最后,针对XGBoost的常见问题进行小结。通过本文,洞悉XGBoost框架的底层算法原理。在用户行为预判、用户标签预测、用户信用评分等数据分析业务中,经常会使用到XGBoost算法框架。如果对XGBoost算法原理理解透彻,在实际业务中的模型训练过程中,有利于较好地理解模型参数,对模型调参过程帮助较大。
对于文章中表述不妥的地方,欢迎私信于我。
参考文章
(1).陈天奇XGBoost算法原著:https://dl.acm.org/doi/pdf/10.1145/2939672.2939785
(2).20道XGBoost面试题:https://cloud.tencent.com/developer/article/1500914
(3).XGBoost框架Parameters含义:https://xgboost.readthedocs.io/en/latest/parameter.html
(4).XGBoost提升树官方介绍:https://xgboost.readthedocs.io/en/latest/tutorials/model.html
(5).XGBoost官方论坛:https://discuss.xgboost.ai/
(6).GBDT提升树官方介绍:https://scikit-learn.org/stable/modules/ensemble.html#gradient-tree-boosting
(7).XGBoost安装官网说明:https://xgboost.readthedocs.io/en/latest/build.html
(8).Kaggle开源数据:https://www.kaggle.com/c/house-prices-advanced-regression-techniques