复旦大学傅金兰:中文分词是个已经解决的任务了吗?
⬆⬆⬆ 点击蓝字
关注我们
AI TIME欢迎每一位AI爱好者的加入!
随着深度神经网络的快速发展,中文单词分词(CWS)系统的性能已逐渐达到瓶颈。尽管神经网络对于性能的提升十分惊人,模型的可解释却极低。那么,性能好的模型就意味着完美无瑕的分词系统吗?如何打开当前SOTA分词系统的黑箱,洞察其优点和不足呢?如何量化不同数据集的分词标准差异?
本期AI TIME PhD直播间,我们有幸邀请到复旦大学博士生傅金兰为我们进行分享,报告主题是——中文分词是个已经解决的任务了吗?在本次报告中,傅金兰介绍了团队发表在EMNLP 2020的工作,总结了分词系统已取得的成就和存在的问题,进而提出了可解释评估的方法,以及如何通过可解释评估进行模型诊断分析以及量化不同分词标准之间的距离,最后简单讲解了可解释评估在NER任务上的扩展。

傅金兰:复旦大学自然语言处理实验室2016级博士生,导师是黄萱菁教授和张奇教授,研究方向为信息抽取,可解释评估。曾以一作在EMNLP、AAAI等顶会上发表论文多篇。

一、动机:打开神经网络分词系统的黑箱
首先介绍本文的动机,图中展示了分词任务的性能随时间的变化趋势,可以明显看出模型性能随时间的推移逐渐趋于平缓。尤其近4年来,模型性能的提升非常之少,大概不到一个点。
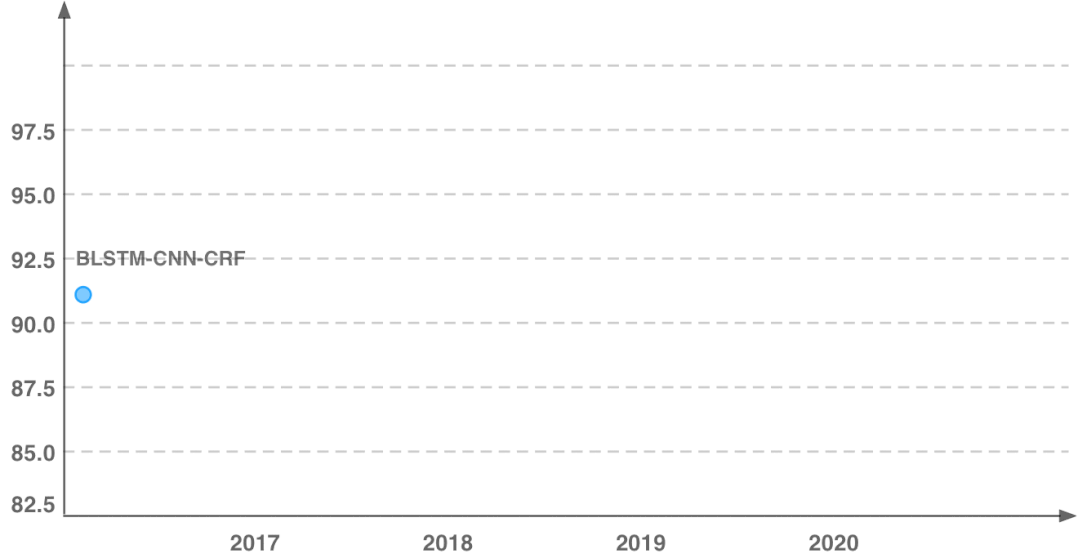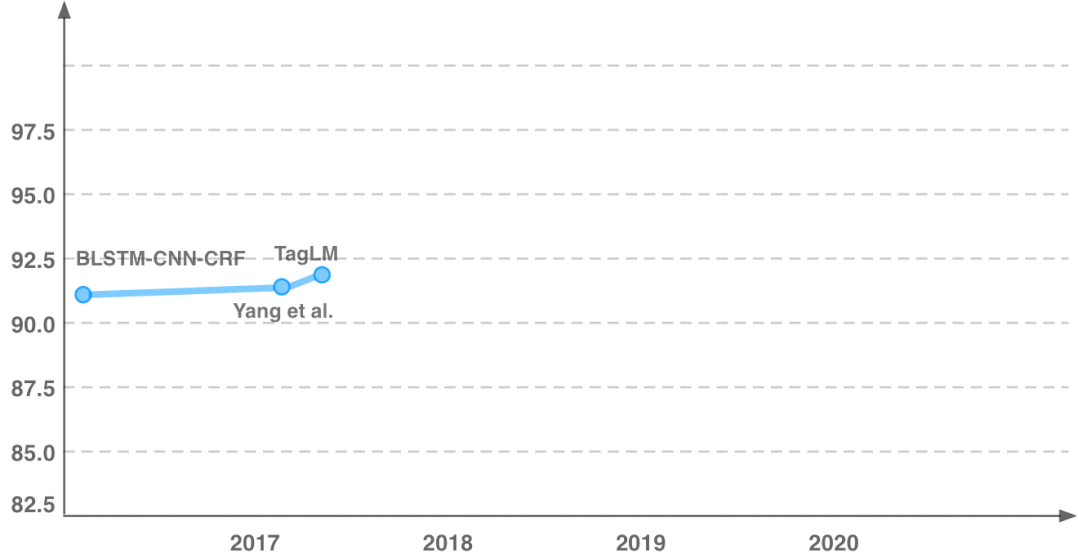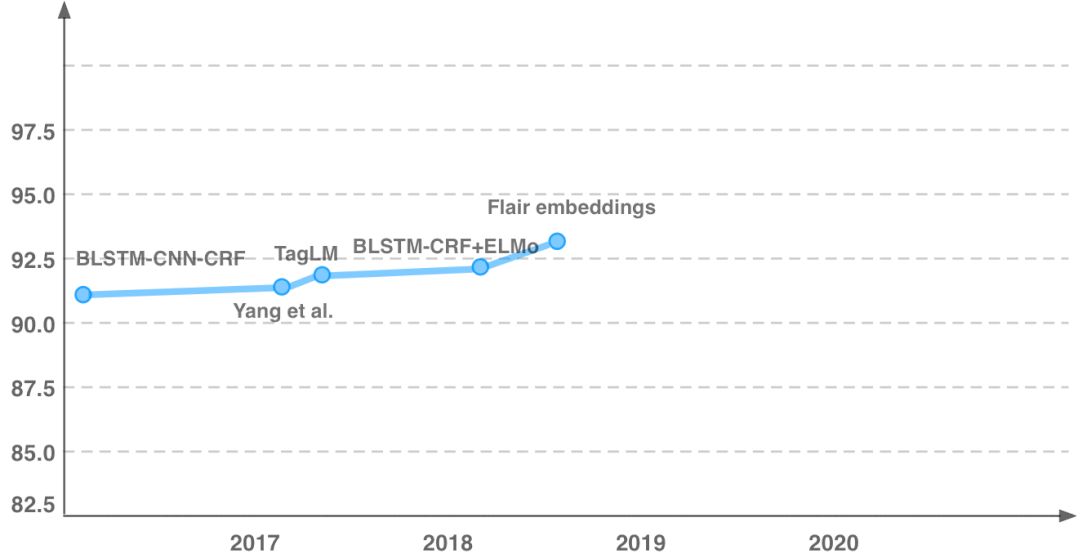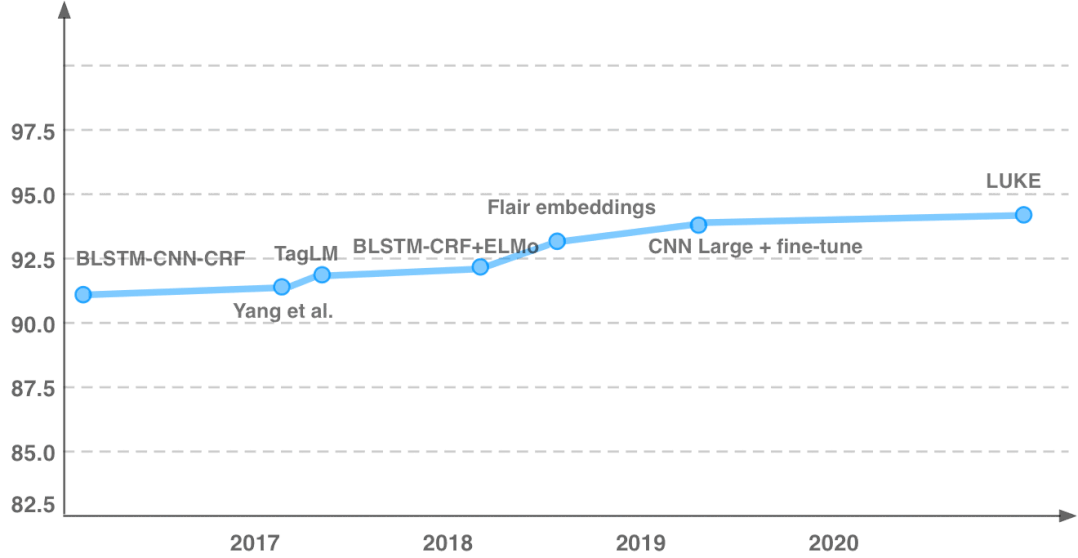
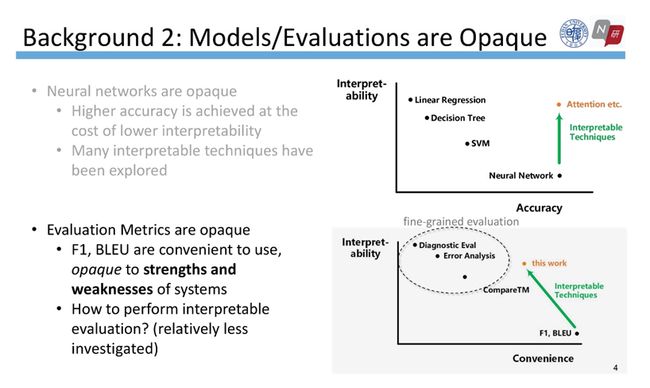
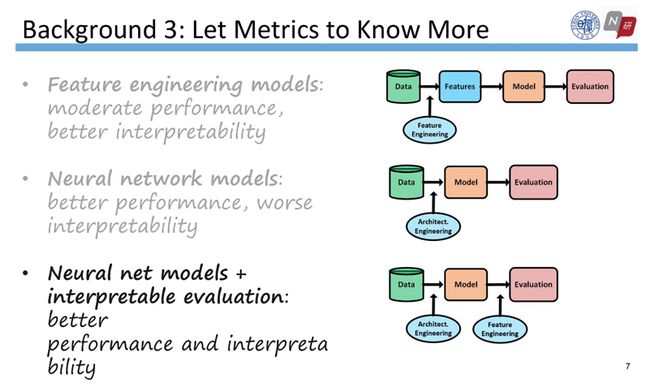
传统的特征工程方法通常在模型训练前就确定要引入的特征,但现在神经网络模型能自动抽取特征,尽管性能提升惊人,模型的可解释却极低。从线性回归到决策树、SVM、再到神经网络,性能增长的同时可解释性却在下降。
有趣的是,评估指标也是不透明的,无法清晰刻画模型的优缺点。为了解决这个问题,最近一些工作在尝试提出诊断测试集、或者进行错误分析等细粒度的评估,然后这些方法有一定的复杂度,并且要依赖于专家知识。
因此,神经网络模型如何扬长补短,既发挥自动抽取特征的优势、又具有可解释性?我们的思路是,将特征工程的应用从模型学习转变到模型评估的过程,换言之,在评估阶段引入更多的知识。
二、研究问题及解决方案:可解释评估
接下来将通过三个研究问题展开介绍具体的工作内容。
Q1:性能好的模型就意味着完美无瑕的分词系统吗?
毋庸置疑的答案是否定的。那么当前SOTA分词系统的瓶颈是什么?为了回答这个问题,我们提出了可解释评估。

可解释评估建立在属性的基础上,而中文分词通常被定义为基于字符的序列标注问题,其属性与字符息息相关。我们在这篇论文中提出了3个大类下的7个属性,分别是内在属性,即词长、句长、OOV密度;熟悉度,即词频、字频;标签一致性,即字的标签一致性、词的标签一致性。
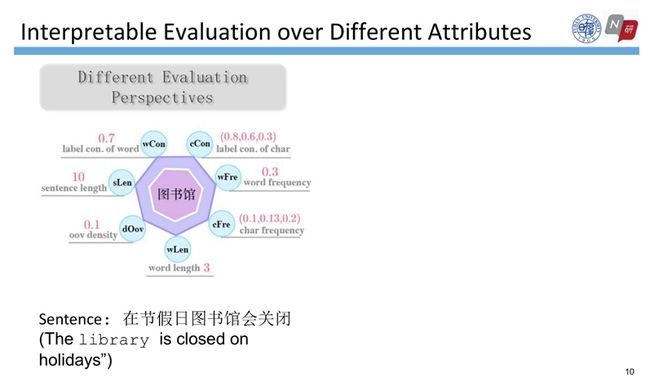
测试集中的每个词都可以计算这7个属性值,然后再依据属性值把这些词划分为几个不同的部分。例如词长属性,假设“图书馆”的词长为3,就将它放置到wLen=3的桶中。通过这样的方式,可以将整个测试集的词分别放入不同的桶中。然后,给定带有gold label的测试集以及模型预测的标签结果这两个文件,我们就可以计算这两个文件的属性值,从而分别在每个桶上计算F1值。
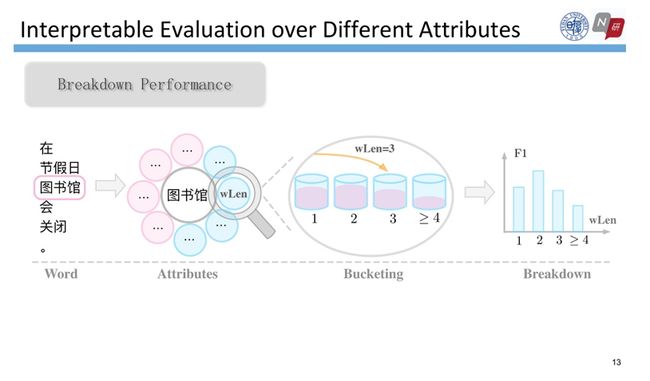
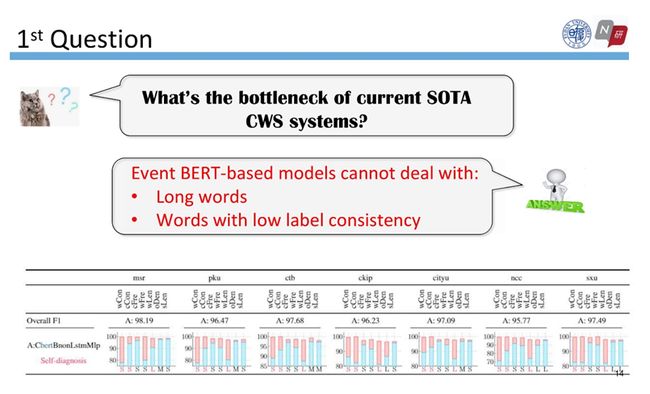
有了计算结果后,我们能通过模型的自诊断回答刚才的问题:当前SOTA分词系统的瓶颈是什么?
下图是BERT模型在7个数据集上自诊断的结果,蓝色的柱子表示表现最差的桶的性能,红色表示最好和最差的桶性能的差距。红色的柱子越长,差距越大,表示该模型在该属性上至少存在一个分组不能很好地完成分词任务。我们发现在不同数据集上,对于低标签一致性的词、以及词长较长的词, BERT的性能差距都普遍较大,这就揭示了BERT的短板和瓶颈。
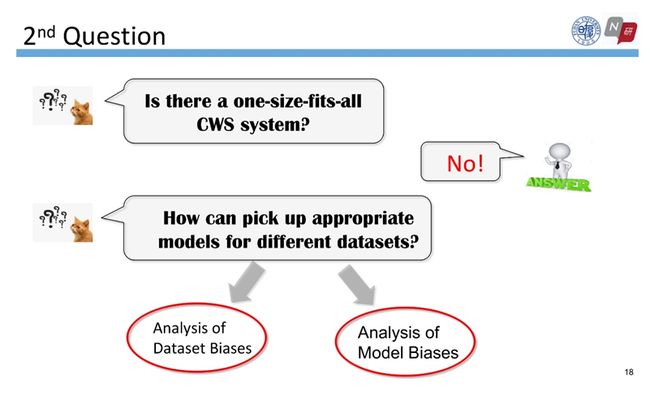
Q2:是否存在一体适用的分词系统?
答案是否定的。为了回答这个问题,我们实现了8个分词系统在7个数据集上的评估,可以明显看到不同数据集上性能最好的模型不尽相同。那么,如何为不同的数据集选择合适的模型结构?

为了回答这个问题,我们通过可解释评估进行了数据集差异分析和模型差异分析。以下结论是基于一定的数学统计检验分析得到的,具有一定的严谨性。
首先,我们提出了两个指标来定量刻画数据集的差异。第一个指标与系统无关,是将一个数据集上词的属性取平均,仅跟属性值有关。第二个指标是依赖于系统的,是8个模型在某个属性上的平均。
我们将7个数据集在7个属性上的2个指标进行了可视化,如图所示,可以发现词的标签一致性和词长对分词性能有普遍的影响。

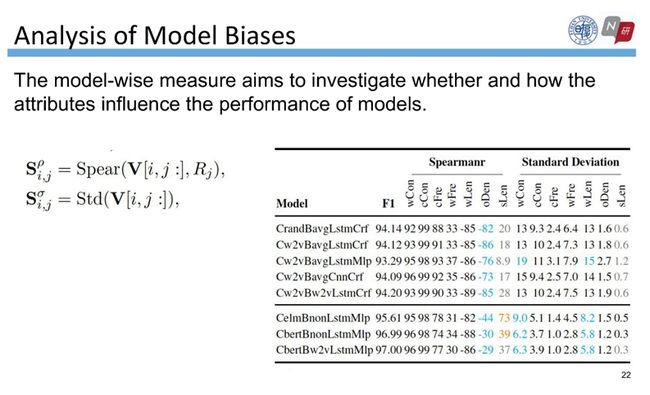
其次,模型偏差分析目的是分析属性是否影响模型的性能,以及属性是如何影响模型的性能的。我们用两个指标来刻画属性如何影响模型的性能,分别是基于斯皮尔曼(Spearman)相关系数和标准差。
右边的表格表示基于Spearman和标准差这两个指标刻画的属性和模型之间的性能关系:Spearman的值越大,表示该属性对模型的影响程度呈正相关,即属性值越大,模型性能越好;标准差越大,表示模型在该属性上性能差别较大。
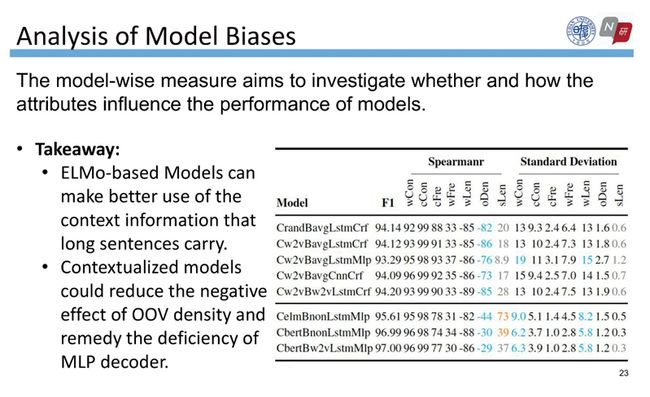
通过分析有两点重要的发现:第一,基于ELMo的模型可以更好地利用长句子所携带的上下文信息。第二,引入了上下文预训练的embedding可以减少OOV密度的负面影响,并弥补MLP decoder的不足。
那么,如何为不同的数据集选择适合它的模型架构呢?
为了回答这个问题,我们提出了辅助诊断的方法。首先选择两个模型,例如我们选择了BERT和ELMo,然后分别将两个模型的结果文件里的词计算属性值,然后按照属性值分桶。还是以词长属性为例,分别计算每个桶上的F1值,然后得到两个模型在每个桶上F1的差值,就能清楚地看出来BERT和ELMo各自的优缺点。
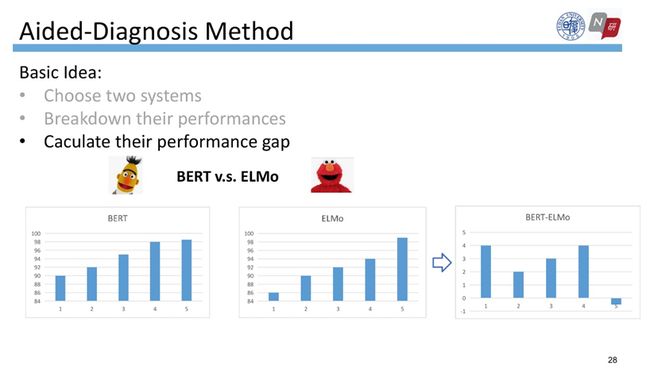
为了便于观看,我们在每个属性上仅展示了一个具有代表意义的桶,即差值较大、或者发生反转的桶。通过观察我们发现ELMo比BERT更擅长处理长序列,而BERT相比ELMo更擅长处理高标签不一致的词。

Q3:是否可以设计一种指标来量化不同数据集的标准距离?
关于分词的标准问题,可以看图中右上角的例子,在CCTV数据集里“总决赛”通常被当作一个词,而在PKU里“总”和“决赛”是分开的两个词。为了衡量一对训练集之间的分词标准差异,我们首先应该知道哪些属性对于分词任务是重要的。

根据先前的分析,我们知道词的标签一致性是一个决定性因素,它的计算是依赖于训练集的,用于衡量测试集中的词-标签对(pair)在训练语料中出现的程度。我们将词的标签一致性的定义扩展到语料库级别,也就是对数据集的词的标签一致性求了期望。
我们假设,可以根据语料级别的词的标签一致性来量化两两数据集之间的距离。如图(粉红色)展示的是两两数据集之间,根据词的标签一致性而刻画的物理距离。为了验证这一假设,我们进行了杂交数据集的实验,并将结果通过归一化等一系列方式得到下图(蓝色),发现数据集间的物理距离图和性能图是非常相似和接近的。这说明词的标签一致性在一定程度上可以量化不同数据之间的标准差异。

那么我们可以使用这个指标来建立更强大的分词系统吗?
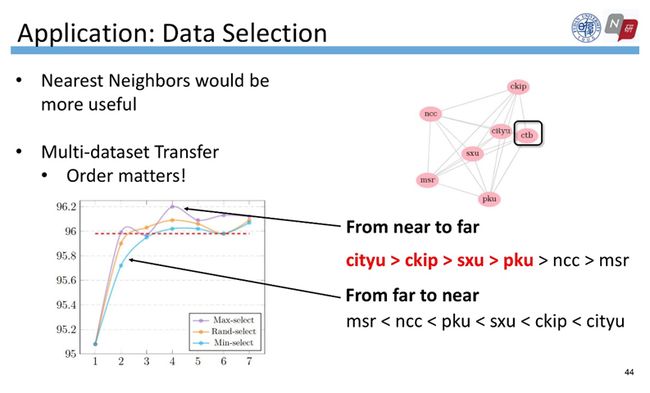
假设我们打算在CTB数据集上训练,如果我们想利用更多相关数据集进行多任务的学习,那么哪些数据集是我们应该使用的?我们假设与CTB较接近的数据集更加有用,依据上面的分析,可以根据标签一致性量化标准距离。
于是,我们做了一个有趣的实验:给定数据集CTB,逐步添加更多数据集,添加顺序有三种:首先可以根据词的标签一致性量化的距离,由近到远添加;也可以根据距离从远到近而添加;最后是随机添加数据集。如图横坐标表示添加数据集的个数,纵坐标表示CTB数据集在这三种不同的顺序下的性能趋势。我们发现更多的训练集不能保证更好的性能,而按照词的标签一致性量化数据集的距离、然后从近到远添加数据集的性能是最优的。
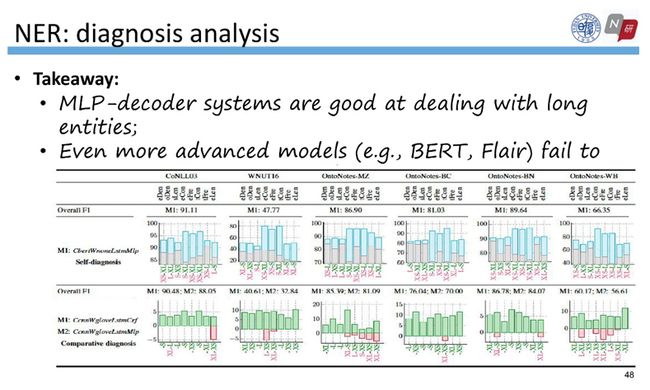
最后,我们所提出来的可解释评估很容易扩展到其他的任务上。以我们发表在EMNLP的另一篇NER相关的姊妹篇为例,可以给每个实体定义类似的若干属性,然后进行分桶,并在每个桶上计算模型表现,从而进行类似的自诊断和辅助诊断的分析,以便发现性能好的模型本身存在的缺点、以及某些普遍认为性能较差的结构可能存在的一些优势。在该工作中,我们发现MLP decoder相比于 CRF decoder更擅长处理长实体。
负采样
原论文链接:
RethinkCWS: Is Chinese Word Segmentation a Solved Task? EMNLP 2020.
https://arxiv.org/pdf/2011.06858.pdf
Interpretable Multi-dataset Evaluation for Named Entity Recognition. EMNLP 2020.
https://www.aclweb.org/anthology/2020.emnlp-main.489.pdf
开源代码:
https://github.com/neulab/InterpretEval
负采样
整理:涂宇鸽
排版:岳白雪
审稿:傅金兰
本周直播预告:


AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你,请将简历等信息发至[email protected]!
微信联系:AITIME_HY

AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注
(直播回放:https://b23.tv/WJcJaw)
(点击“阅读原文”下载本次报告ppt)