【社区分享】从零开始学习 TinyML,建立 TensorFlow 深度学习模型(模型应用篇)
TinyML是什么?如何从零开始入门学习?本系列上一篇教程为大家介绍了 TensorFlow 的基础原理,在这一篇中,我们将结合代码实例,教你如何去编写微控制器能够运行的 ML 应用,并进一步掌握项目运行的整体流程。

本文来自社区投稿与征集,作者王玉成,ML&IoT Google Developers Expert,温州大学智能锁具研究院总工程师。了解更多:https://blog.csdn.net/wfing
Hello World — 梦开始的地方(中)
在前面的准备工作中,我们完成了模型训练,并且将模型的二进制格式转化成为 C++ 可以识别的数组。但是,这仅仅是基于微控制器项目前面的一小步。后续还有许多工作要做。
项目中的代码也是完全基于 C++ 11 的标准版来开发的,避免了复杂的逻辑。这份代码也可以当作 C++ 模板进行开发。但是不要一提到 C++ 就特别怕,在这一篇文章会用已有的代码去描述整体的工程流程。
正式阅读项目的代码之前,我们需要关注一下项目运行的整体流程:
-
传感器采集数据
-
对数据进行前处理,送到 ML 解释器
-
ML 模型预测数据
-
对预测的数据做出最终的判断
-
设备响应 ML 的推理结果,进行必要的操作
3.1 从测试角度来看流程
进行代码阅读之前,我们最好通过一些测试用例来了解代码流程。
通过有效的测试用例,我们可以看到在何时运行了错误的代码。在编写完成之后,测试通常会自动的运行,并且不断验证是否仍然在执行我们所希望的方法。在这个示例中,我们会根据测试用例来加载建模,并且对模型推理进行检测:检验模型的预测是否符合我们的预期。通过测试代码来入手,而非进行代码阅读,将会使我们更快地了解代码的流程。
3.2 头文件依赖
首先我们来看一下这些代码依赖于哪些头文件:
![]()
/home/ycwang/work/ycwang/desktop/ai/tensorflow/tensorflow-master/是 tensorflow 源代码的一级目录/根目录的位置。
头文件结构如下:
![]()
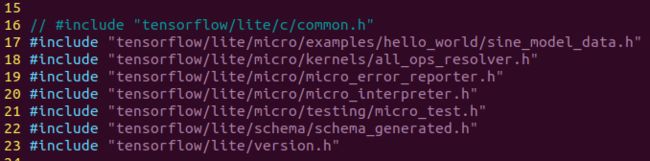
#include 是用于导入 C++ 的头文件,类似于 JAVA 用 import 导入包的用法。头文件引用指向的目录为 tensorflow 源码的根目录。我们先来看看这些头文件的含义:
-
tensorflow/lite/micro/examples/hello_world/sine_model_data.h
在上一章的最后,我们使用 xxd 命令把训练后的模型,转换为 C ++ 的二进制模型 -
tensorflow/lite/micro/kernels/all_ops_resolver.h
一个允许解释器加载模型使用的操作的类 -
tensorflow/lite/micro/micro_error_reporter.h
可以记录错误并输出以帮助调试的类 -
tensorflow/lite/micro/micro_interpreter.h
TensorFlow Lite for Microcontrollers 解释器,模型将在解释器中运行 -
tensorflow/lite/micro/testing/micro_test.h
编写测试的轻量级框架,我们可以将该文件作为测试运行 -
tensorflow/lite/schema/schema_generated.h
定义 TensorFlow Lite FlatBuffer 数据结构的模型,用于理解 sine_model_data.h 中的模型数据 -
tensorflow/lite/version.h
模式的当前版本号
大致了解了头文件依赖之后,我们就可以试着通过阅读源代码去了解测试流程。所有的代码来自于 hello_world_test.cc 文件。
3.3 建立测试
我们进入了代码的正文。TensorFlow Lite 将代码用于微控制器测试框架。看起来像这样:
TF_LITE_MICRO_TESTS_BEGIN
TF_LITE_MICRO_TEST(LoadModelAndPerformInference){
...
}
在 C ++ 中,您可以定义特殊命名的代码块, 这些代码块称为宏。此处名称为 TF_LITE_MICRO_TESTS_BEGIN 和 TF_LITE_MICRO_TEST 的宏,它们在文件 micro_test.h 中定义。
这些宏将我们其余的代码包装在必要的设备中,以使其得以执行。
我们不需要知道它到底是如何工作的;我们只知道我们可以将这些宏用作设置测试的快捷方式。
第二个宏名为 TF_LITE_MICRO_TEST,接受一个参数。在这种情况下,传入的参数是 LoadModelAndPerformInference。这个说法是测试名称,并在运行测试时将其与测试结果一起输出这样我们就可以查看测试是否通过。
3.4 准备Log
// Set up logging
tflite::MicroErrorReporter micro_error_reporter;
tflite::ErrorReporter* error_reporter = µ_error_reporter;
在29行中,我们定义一个 MicroErrorReporter 实例。MicroErrorReporter 类在 micro_error_reporter.h 中定义。它提供了记录调试机制推理过程相关的信息。我们将其称为打印调试信息,然后 TensorFlow Lite for Microcontrollers 解释器将使用它来打印遇到的任何错误。
您可能已经注意到了每个 tflite ::前缀输入名称,例如 tflite :: MicroErrorReporter。这是一个名字空间,这只是帮助组织 C ++ 代码的一种方式。TensorFlow Lite 在名称空间 tflite 下定义了所有有用的东西,这意味着如果另一个库碰巧实现了类具有相同的名称,它们不会与 TensorFlow Micro 提供的名称冲突。
第一个声明似乎很简单,但是第二个看起来带 * 和 & 字符,看着很奇怪?当我们已经有 MicroErrorReporter,为什么要声明一个 ErrorReporter 呢?
tflite :: ErrorReporter * error_reporter =&micro_error_reporter;
为了解释这里发生的事情,我们需要了解一些背景信息。MicroErrorReporter 是 ErrorReporter 类的子类,它提供了一个关于如何在 TensorFlow Lite 中使用这种调试日志记录机制的说明。
MicroErrorReporter 会继承 ErrorReporter 的一种方法,将其替换为专为在微控制器上使用而编写的逻辑。
在前面的代码行中,我们创建一个名为 error_reporter 的变量,该变量为 type ErrorReporter。它也是一个指针,在其声明中使用 * 表示。
指针是一种特殊类型的变量,它不保存值,而是保存引用。可以在内存中找到值的位置。在 C ++ 中,一些特定的类(例如 ErrorReporter)可以指向其子类之一的值(例如 MicroErrorReporter)。
如前所述,MicroErrorReporter 继承了 ErrorReporter。无需过多赘述,继承该方法具有使其他一些方法难以理解的副作用。
为了仍然可以访问 ErrorReporter 的非重写方法,我们需要将我们的 MicroErrorReporter 实例视为一个 ErrorReporter。我们通过创建 ErrorReporter 指针并将其指向 micro_error_reporter 变量。连字号 (&) 在前面的分配中表示我们正在分配 micro_error_reporter 的指针,而不是它的值。
3.5 映射模型
// Map the model into a usable data structure. This doesn't involve any
// copying or parsing, it's a very lightweight operation.
const tflite::Model* model = ::tflite::GetModel(g_sine_model_data);
if (model->version() != TFLITE_SCHEMA_VERSION) {
TF_LITE_REPORT_ERROR(error_reporter,
"Model provided is schema version %d not equal "
"to supported version %d.\n",
model->version(), TFLITE_SCHEMA_VERSION);
}
通过上述代码,我们获取模型数据数组(在文件 sine_model_data.h 中定义)并将其传递给名为 GetModel() 的方法。此方法返回模型指针,并分配给名为 model 的变量。如您所料,此变量能代表我们的模型。
Model 类型是一个结构,在 C ++ 中与类非常相似。在 schema_genic.h 中,包含了我们模型的数据,并允许我们查询信息。
知识点:数据对齐。如果您在 sine_model_data.cc 中检查模型的源文件,则会看到定义 g_sine_model_data 的位置引用了一个宏。
DATA_ALIGN_ATTRIBUTE:
const unsigned char g_sine_model_data [] DATA_ALIGN_ATTRIBUTE = {
当数据在内存中对齐时,处理器可以最有效地读取数据,这意味着数据存储结构,在保证不与处理器边界重叠的情况下,仅需一次操作即可读取。通过指定此宏,我们可以确保我们的模型数据已正确对齐以实现最佳读取性能。
然后,我们将模型的版本号与 TFLITE_SCHEMA_VERSION 进行比较,表示我们当前正在使用的 TensorFlow Lite 库的版本。如果数字匹配,我们的模型已使用兼容版本的TensorFlow Lite转换器。
Tips:在进行下一步之前,最好检查一下模型版本,因为匹配可能会导致难以调试的奇怪行为。
我们调用 error_reporter 的 Report() 方法来记录此警告。error_reporter 也是一个指针,我们使用->运算符访问 Report()。
Report() 方法的设计行为类似于 C ++ 中常用的 printf(),用于记录文本。我们可以将 printf() 方法中熟悉的格式化输出用到 Report() 方法中。
3.6 创建一个 AllOpsResolver
// This pulls in all the operation implementations we need
tflite::ops::micro::AllOpsResolver resolver;
我们的代码可以记录错误,并且我们已经将模型加载到了我们的结构体中,并检查它是否为兼容版本。
接下来,我们创建一个 AllOpsResolver 的实例:
通过上面的分析,我们了解了机器学习模型的运算是输入转换为输出的数学运算。AllOpsResolver 类提供 TensorFlow Lite for Microcontrollers 的所有操作并且提供解释器。
3.7 定义张量域
// Create an area of memory to use for input, output, and intermediate arrays.// Finding the minimum value for your model may require some trial and error.
const int tensor_arena_size = 2 * 1024;
uint8_t tensor_arena[tensor_arena_size];
这部分存储空间将用于存储模型的输入、输出和中间张量,我们称其为张量域。就我们而言,我们已经提供了一个大小为2,048字节的数组。我们用表达式指定其为 2×1024。那么,我们的张量域应该有多大?这是个好问题。不幸,没有一个简单的答案。不同的模型架构具有不同的大小和输入,输出和中间张量的数量,因此很难知道我们需要多大内存。该数字不必是准确的,我们可以保留内存使其不超出我们的需求,但是由于微控制器的RAM有限,我们应该将其保持尽可能小,以便为我们程序的其余部分留出空间。我们可以通过反复试验来做到这一点。这就是为什么我们将数组大小表示为 n×1024:因此可以轻松地上下缩放数字(通过更改 n),同时保持它是八的倍数。要找到正确的数组大小,请从较高开始。本书示例中使用的最高数字是 70×1024。然后,依次减少数量,直到模型不再运行。那么,最后一个有效的数字就是正确的!
3.8 创建解释器
// Build an interpreter to run the model with
tflite::MicroInterpreter interpreter(model, resolver, tensor_arena,
tensor_arena_size, error_reporter);
// Allocate memory from the tensor_arena for the model's tensors
TF_LITE_MICRO_EXPECT_EQ(interpreter.AllocateTensors(), kTfLiteOk);
首先,我们声明一个名为 MicroInterpreter 的解释器。这个类是 TensorFlow Lite for Microcontrollers 最核心的类:一段神奇的代码将根据我们提供的数据进行建模。我们将大多数对象传递给其构造函数,然后调用 AllocateTensors()。
AllocateTensors() 方法遍历由模型定义所有张量,并从 tensor_arena 为其分配内存。在尝试运行推理之前,我们必须先调用 AllocateTensors(),否则推断理将失败。
3.9 检查输入张量
// Obtain a pointer to the model's input tensor
TfLiteTensor* input = interpreter.input(0);
创建解释器后,我们需要为模型提供一些输入。至此,我们将输入数据写入模型的输入张量。
要获取指向输入张量的指针,我们调用解释器的 input() 方法。由于一个模型可以有多个输入张量,我们需要将索引传递给 input() 指定我们想要哪个张量的方法。在这种情况下,我们的模型只有一个输入张量,因此其索引为 0。在 TensorFlow Lite 中,张量由 TfLiteTensor 结构表示,即在 c_api_internal.h 中定义。该结构提供了用于交互的 API 张量。在下一部分代码中,我们来验证张量是否正确。因为我们将大量使用张量。通过以下代码来熟悉 TfLiteTensor 结构的工作方式:
// Make sure the input has the properties we expect
TF_LITE_MICRO_EXPECT_NE(nullptr, input);
// The property "dims" tells us the tensor's shape. It has one element for
// each dimension. Our input is a 2D tensor containing 1 element, so "dims"
// should have size 2.
TF_LITE_MICRO_EXPECT_EQ(2, input->dims->size);
// The value of each element gives the length of the corresponding tensor.
// We should expect two single element tensors (one is contained within the
// other).
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);
// The input is a 32 bit floating point value
TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, input->type);
您会注意到的第一件事是几个宏:TFLITE_MICRO_EXPECT_NE 和 TFLITE_MICRO_EXPECT_EQ。这些宏是 TensorFlow Lite for Micro 的一部分,属于测试框架,它们使我们能够对值进行断言,证明它们具有某些期望值。
例如,宏 TF_LITE_MICRO_EXPECT_NE 设计为断言这两个调用它的变量不相等(因此其名称的 _NE 部分代表不等于)。如果变量不相等,则代码将继续执行。如果他们相等,将记录一个错误,并且测试将标记为失败。
实际上在 Tensorflow Lite micro 中定义了一系列的宏,可以参考 tensorflow/lite/micro/testing/micro_test.h 分析宏的源码,获取更多的帮助。
整个张量的检查包括输入张量的形状,通过对 TfLiteTensor 中的 dims 成员来实现。最后确认张量的维度是正确的。
3.10 通过输入运行推理
要进行推断,我们需要在输入张量中添加一个值,然后指示解释器调用模型。之后,我们将检查模型是否成功运行。代码如下:
// Provide an input value
input->data.f[0] = 0.;
TensorFlow Lite 的 TfLiteTensor 结构具有一个数据变量,可用于设置输入张量的内容。
input-> data.f [0] = 0。数据变量是 TfLitePtrUnion,它是一个联合体,这是一种特殊的 C ++ 数据类型,允许您将不同的数据类型存储在内存中的同一位置。由于一个给定张量可以包含许多不同类型的数据(例如,浮点型、整型或布尔值),联合体是帮助我们进行存储的理想类型。TfLitePtrUnion 联合体在 c_api_internal.h 中声明。结构如下:
typedef union {
int32_t* i32;
int64_t* i64;
float* f;
TfLiteFloat16* f16;
char* raw;
const char* raw_const;
uint8_t* uint8;
bool* b;
int16_t* i16;
TfLiteComplex64* c64;
int8_t* int8;
} TfLitePtrUnion;
我们会看到有一堆成员,每个成员代表某种类型。每个成员是一个指针,可以指向内存中应该存储数据的位置存储。当我们像以前一样调用解释器 .AllocateTensors() 时,适当的指针设置为指向为该内存分配的内存块张量以存储数据。因为每个张量都有特定的数据类型,所以只有指针将设置对应的类型。
这意味着,要存储数据,我们可以使用不同类型的指针。例如,如果我们的张量是 kTfLiteFloat32 类型,我们将使用 data.f 由于指针指向一个内存块,因此我们可以在后面使用方括号([])指示我们的程序在何处存储数据的指针名称。
// Run the model on this input and check that it succeeds
TfLiteStatus invoke_status = interpreter.Invoke();
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
当我们在解释器上调用 Invoke() 时,TensorFlow Lite 解释器将运行模型。该模型由数学运算图组成,执行解释器将输入数据转换为输出。此输出存储在模型的输出张量中,我们将在后面进行探讨。
Invoke()方法返回一个 TfLiteStatus 对象,它使我们知道推理是否成功或存在问题。其值可以是 kTfLiteOk 或 kTfLiteError。我们检查错误报告中是否存在以下错误,如果:
(invoke_status!= kTfLiteOk){
error_reporter-> Report(“调用失败\ n”);
}
最后,我们断言状态必须为 kTfLiteOk 才能使测试通过:
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk,invoke_status);
3.11 读取输出
// Obtain a pointer to the output tensor and make sure it has the
// properties we expect. It should be the same as the input tensor.
TfLiteTensor* output = interpreter.output(0);
像输入一样,我们模型的输出也可以通过 TfLiteTensor 进行访问,指向它的指针非常简单
TfLiteTensor* output = interpreter.output(0);
像输入一样,输出是一个嵌套在 2D 张量中的浮点标量值。
为了进行测试,我们再次检查了输出张量是否具有预期的大小,尺寸和类型:
TF_LITE_MICRO_EXPECT_EQ(2, output->dims->size);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[0]);
TF_LITE_MICRO_EXPECT_EQ(1, input->dims->data[1]);
TF_LITE_MICRO_EXPECT_EQ(kTfLiteFloat32, output->type);
// Obtain the output value from the tensor
float value = output->data.f[0];
// Check that the output value is within 0.05 of the expected value
TF_LITE_MICRO_EXPECT_NEAR(0., value, 0.05);
现在,我们获取输出值并进行检查以确保它符合我们的高标准。首先,我们将其分配给 float 变量:
float value = output->data.f[0];
每次运行推理时,输出张量将被新值覆盖。
这意味着如果您想在程序中保留输出值,而同时继续运行推理,您需要从输出张量复制它,就像我们刚才做的。
接下来,我们使用 TF_LITE_MICRO_EXPECT_NEAR 来证明该值接近真实值。
如我们先前所见,TF_LITE_MICRO_EXPECT_NEAR 断言,第一个参数及第二个参数小于第三个参数的值。当输入的正弦为 0 时,我们测试输出是否在 0 到 0.05 范围内。我们有两个原因可以期望这个数字接近我们想要的,但不是确切的值。首先是我们的模型近似于实际正弦值,因此我们知道它不会是完全正确。第二是因为浮点计算在计算机上有一定的误差。错误可能是由于不同电脑的硬件不同造成的:例如,笔记本电脑的 CPU 可能启动结果与 Arduino 略有不同。通过灵活期望,我们更有可能使我们的测试通过。
其余测试可以推断出一次或更多次,只是为了进一步证明我们的模型有效。要再次运行推理,我们要做的就是为输入张量分配一个新值,调用 interpreter.Invoke(),并从输出张量读取输出:
// Run inference on several more values and confirm the expected outputs
input->data.f[0] = 1.;
invoke_status = interpreter.Invoke();
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(0.841, value, 0.05);
input->data.f[0] = 3.;
invoke_status = interpreter.Invoke();
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(0.141, value, 0.05);
input->data.f[0] = 5.;
invoke_status = interpreter.Invoke();
TF_LITE_MICRO_EXPECT_EQ(kTfLiteOk, invoke_status);
value = output->data.f[0];
TF_LITE_MICRO_EXPECT_NEAR(-0.959, value, 0.05);
}
TF_LITE_MICRO_TESTS_END
请注意,我们如何重用相同的输入和输出张量指针。因为我们已经有指针,我们不需要调用解释器 .input(0) 或再次用解释器输出 (0)。在我们的测试中,我们已经证明了 TensorFlow Lite for Microcontrollers 可以成功加载我们的模型,分配适当的输入和输出张量,运行进行推断,并返回预期结果。最后要做的是指示结束使用宏进行测试:
}
TF_LITE_MICRO_TESTS_END
3.12 运行测试
即使此代码最终将在微控制器上运行,我们仍然可以在我们的开发机器上构建并运行我们的测试。这使得更容易编写和调试代码。与微控制器相比,个人计算机已经远远超越了微控制器。
用于记录输出和单步执行代码的更方便的工具,这使它找出任何错误要简单得多。此外,将代码部署到设备还需要时间,因此在本地运行我们的代码要快得多。良好的工作流程,可用于构建嵌入式应用程序(或者说实话,任何类型的软件)是要在可以正常运行的测试中编写尽可能多的逻辑。总会有一些地方需要实际的硬件运行,本地测试的次数越多,您的工作就会越轻松。实际上,这意味着我们应该尝试编写预处理输入的代码,在运行模型之前进行模型推断并处理一组测试中的所有输出使其在设备上运行。用 make 来运行我们的测试。
首先进入tensorflow源码主目录。然后运行以下命令:
make -f tensorflow/lite/micro/tools/make/Makefile test_hello_world_test
运行结果如下图所示:

3.13 运行程序
当我们分析完了测试程序的代码之后,我们也就明白了整个程序的流程。测试程序和实际的运行程序的差异非常小,可以直接对着源码去分析。我们仅把程序运行的结果展示出来。
程序编译正常。编译成功,生成的用于 PC 机上执行的二进制文件在以下 tensorflow 源码根目录以下的这个目录:tensorflow/lite/micro/tools/make/gen/.
在 linux 机器上,正常运行程序的截图如下:

Hello World — 梦开始的地方(下)
这一节介绍如何把模型代码加载到 Arduino 硬件上并且执行。同时 TensorFlow Lite 会定期添加对新设备的支持,因此如果您要使用的设备未在此处列出,可以访问此网址获取最新的信息,以及查看更新的部署说明。
每个设备都有自己独特的输出功能,范围从一排 LED 到一个 LED,全 LCD 显示。因此该示例包含 HandleOutput() 每个设备的自定义实现。
各种各样的 Arduino 板都有不同的功能。并非全部的开发板都能够运行 TensorFlow Lite for Microcontrollers。我们推荐的是 Arduino Nano 33 BLE Sense 开发板。其中这款开发板的 LED 类如下图所示:

4.1 处理 Arduino 的输出
因为我们只有一个 LED 可以工作,所以我们需要创造性地思考。一种选择是根据最新预测的正弦值来改变 LED 的亮度。鉴于该值的范围是 –1 到 1,我们可以用完全熄灭的 LED 表示 0,用完全点亮的 LED 表示 –1 和 1 LED,以及带有部分变暗 LED 的任何中间值。当程序在循环中运行推理时,LED 将反复亮起和熄灭。
我们可以使用 kInferencesPerCycle 常数改变在整个正弦波周期内执行的推理次数。因为一个推断要花费一定的时间,所以对在 constants.cc 中定义的 kInferencesPerCycle 进行调整将调整 LED 衰减的速度。hello_world/arduino/constants.cc 中有此文件的特定于 Arduino 的版本。该文件的名称与 hello_world/constants.cc 相同,因此在为 Arduino 构建应用程序时将使用该文件代替原始实现。
要使内置 LED 变暗,我们可以使用一种称为脉冲宽度调制的技术 (PWM)。如果我们非常快速地打开和关闭输出引脚,则该引脚的输出电压成为关断和导通状态所花费时间之比的一个因素。如果引脚在每种状态下花费 50% 的时间,其输出电压将为其最大值的 50%,如果在开启状态下花费 75%,在关闭状态下花费 25%,则其电压将为 75% 最大。
PWM 仅在某些 Arduino 设备的某些引脚上可用,但是很容易用:我们只需要调用一个函数来设置所需的引脚输出电平即可。
实现 Arduino 输出处理的代码在 hello_world/arduino/output_handler.cc,用于代替原始文件 hello_world/output_handler.cc。
让我们浏览一下源代码:

我们来分析源码中的几个关键部分:
首先,我们包含一些头文件。我们的 output_handler.h 指定用于这个文件。Arduino.h 提供了 Arduino 平台的接口;我们用它来控制开发板。因为我们需要访问 kInferencesPerCycle,所以我们还要引用 constants.h。
接下来,我们定义函数并指示它在首次运行时要执行的操作:
//调整 LED 的亮度以表示当前的 y 值
void HandleOutput(tflite :: ErrorReporter * error_reporter,float x_value,
float y_value){
//跟踪函数是否至少运行了一次
static is_initialized = false;
//只做一次
if(!is_initialized){
//将 LED 引脚设置为输出
pinMode(LED_BUILTIN,OUTPUT);
is_initialized = true;
}
在 C ++ 中,在函数内声明为静态的变量将在多个函数中保持其值该函数的运行。在这里,我们使用 is_initialized 变量来跟踪是否以下if(!is_initialized)块中的代码以前从未运行过。
初始化块调用 Arduino 的 pinMode()函数,该函数指示微控制器给定的引脚应处于输入还是输出模式,使用 IO 之前必须要这么做。该函数使用由 Arduino 平台:LED_BUILTIN 和 OUTPUT。LED_BUILTIN 表示引脚连接安装到开发板的内置 LED 上,而 OUTPUT 表示输出模式。
将内置 LED 的引脚配置为输出模式后,将 is_initialized 设置为 true 这样该块代码将不会再次运行。
接下来,我们计算所需的 LED 亮度:
//计算 LED 的亮度,以使 y = -1 完全关闭
//并且 y = 1 完全打开。LED 的亮度范围为 0-255。
Int brightness=(int)(127.5f *(y_value + 1)) ;
Arduino 允许我们将 PWM 输出的电平设置为 0 到 255 之间的数字,其中 0 表示完全关闭,而 255 表示完全打开。我们的 y_value 是介于 – 和 1。前面的代码将 y_value 映射到 0 到 255 的范围内,以便当 y = -1 时 LED 完全熄灭,当 y = 0 时,LED 点亮一半,当 y = 1 时,LED 完全点亮。
下一步是实际设置 LED 的亮度:
//设置 LED 的亮度。如果指定的引脚不支持 PWM,
//当 y> 127 时,这将导致 LED 点亮,否则将熄灭。
AnalogWrite(LED_BUILTIN,brightness);
Arduino 平台的 AnalogWrite() 函数具有一个引脚号(我们提供 LED_BUILTIN)和 0 到 255 之间的值。调用此功能时,LED将在该级别点亮。
最后,我们使用 ErrorReporter 实例记录亮度值:
//记录当前亮度值以在 Arduino 绘图仪中显示
error_reporter-> Report(“%d \ n”,brightness);
在 Arduino 平台上,ErrorReporter设置为通过串行端口记录数据。串口是微控制器与主机计算机通信的一种非常常见的方式,并且通常用于调试。这是一种通讯协议,其中的数据是通过打开和关闭输出引脚来一次通信一位。我们可以使用它发送和接收从原始二进制数据到文本和数字的任何内容。
Arduino IDE 包含用于捕获和显示通过串行端口。其中一种工具 “串行绘图仪 (Serial Plotter)” 可以显示其接收到的值的图形通过串行。通过从我们的代码中输出亮度值流,我们将能够看到他们的图表。接下来我们就完成整个运行过程。
4.2 运行示例
运行 Arduino 的开发环境之后,打开 Hello_world 例子。
然后选择开发板
![]()

并且做相应的库更新。
选择串口
![]()

运行程序
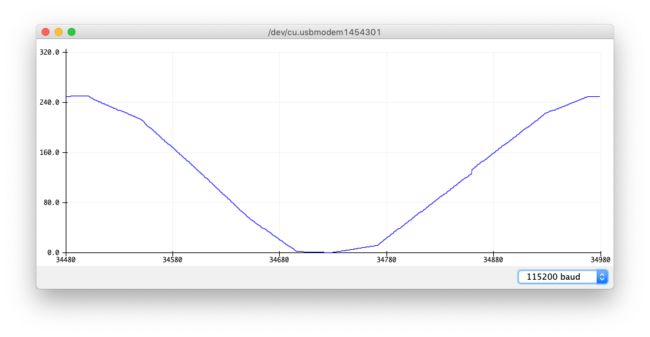
查看串口数据
显示数据图,或者原始数据。

这样我们就完成了整个代码到硬件的运行。
当然Arduino开发板中有4个示例项目可以运行。可以试着运行其它的项目。
进一步学习,请密切关注后续第三集的发布。回顾上一集内容,点击基础原理篇。
如果你对本文中提到的一些知识点存在疑问,欢迎移步“问答”版块发帖提问。你的问题有机会得到 CSDN 百大热门技术博主、资深社区作者或者 TensorFlow 资深开发者的解答哦!同时,我们也欢迎你积极地在这个版块里,回答其他小伙伴提出的问题,成为 CSDN 社区贡献者,迈出出道第一步!马上开始讨论吧!
想了解更多大神的经验分享?扫码关注TensorFlow官方微信公众号(TensorFlow_official),产品更新、课程教学、技术实践、应用实例等精彩内容一网打尽!
