实验八 查找算法比较
实验八 查找
实验目的
基于教材内容,从顺序查找、二分查找、基于BST的查找和哈希中任选两种查找算法,实现并比较性能。
基本要求
(1)对实现的查找算法进行实验比较,在不同数据规模(N)下执行100次成功查找,以表格形式记录最小、最大和平均查找时间;在不同数据规模(N)下执行100次不成功查找,以表格形式记录最小、最大和平均查找时间。
(2)查找算法要基于教材,测试输入的整数数据文件(5个,文件中数据规模N分别是100,1K,10K,100K和1M),每次查找的比较次数和时间也要输出到文件中。
(3)提交最终实验作业。用附件的形式,提交两个文件:一个压缩包(包含源码和5个用于查找测试的数据文件);一个pdf文档(文档中包含实验日志和一个根据基本要求(1)记录实验结果的表格,然后进行适当的实验结果分析)。
本次实验的重点在于加强对顺序查找、二分查找、基于BST的查找和哈希等查找算法的认识和性能的分析。(在此次实验中我选择了顺序查找和哈希查找,所以以下日志内容主要是本人对两种查找算法的认识)
- 顺序查找:
顾名思义,顺序查找即依次从前向后查找,是一种易于理解、易于实现,但耗时较多的查找方式。
-
查找过程
首先,将待查找数据与表内的第一个数据进行比对,如果相同则表明查找成功,如果不相同,则与第二个数据进行对比。重复以上过程,直到找到匹配的数据,使查找成功,或直到查找到表的最后一位依旧不匹配,此时表明该数据不存在,查找不成功。
-
算法要求
必须采用顺序存储结构。
-
比较次数
当顺序表有n个关键字时:
查找失败时,比较max次关键字;查找成功时,比较n次关键字(n即为循环次序)。
-
算法复杂度
顺序查找的基本思想是一次向后查找,若找到就停止,若一直到最后都未找到,则表明查找失败。
时间复杂度是O(n)
-
Hash查找
哈希查找是通过计算数据元素的存储地址进行查找的一种方法。
-
定义
哈希查找的操作步骤:
⑴用给定的哈希函数构造哈希表;
⑵根据选择的冲突处理方法解决地址冲突;
⑶在哈希表的基础上执行哈希查找
-
操作步骤
step1
取数据元素的关键字key,计算其哈希函数值。若该地址对应的存储空间还没有被占用,则将该元素存入;否则执行step2解决冲突。
step2
根据选择的冲突处理方法,计算关键字key的下一个存储地址。若下一个存储地址仍被占用,则继续执行step2,直到找到能用的存储地址为止。哈希查找步骤为:
设哈希表为HST[0~M-1],哈希函数取H(key),解决冲突的方法为R(x);
Step1 对给定k值,计算哈希地址 Di=H(k);若HST为空,则查找失败;
若HST=k,则查找成功;否则,执行step2(处理冲突)。
Step2 重复计算处理冲突的下一个存储地址 Dk=R(Dk-1),直到HST[Dk]为
空,或HST[Dk]=k为止。若HST[Dk]=K,则查找成功,否则查找失败。
哈希查找的本质是先将数据映射成它的哈希值。哈希查找的核心是构造一个哈希函数,它将原来直观、整洁的数据映射为看上去似乎是随机的一些整数。
哈希查找的产生有这样一种背景——有些数据本身是无法排序的(如图像),有些数据是很难比较的(如图像)。如果数据本身是无法排序的,就不能对它们进行比较查找。如果数据是很难比较的,即使采用折半查找,要比较的次数也是非常多的。因此,哈希查找并不查找数据本身,而是先将数据映射为一个整数(它的哈希值),并将哈希值相同的数据存放在同一个位置一即以哈希值为索引构造一个数组。
在哈希查找的过程中,只需先将要查找的数据映射为它的哈希值,然后查找具有这个哈希值的数据,这就大大减少了查找次数。如果构造哈希函数的参数经过精心设计,内存空间也足以存放哈希表,查找一个数据元素所需的比较次数基本上就接近于一次。
-
解决冲突
影响哈希查找效率的一个重要因素是哈希函数本身。当两个不同的数据元素的哈希值相同时,就会发生冲突。为减少发生冲突的可能性,哈希函数应该将数据尽可能分散地映射到哈希表的每一个表项中。解决冲突的方法有以下两种:
(1) 开放地址法
如果两个数据元素的哈希值相同,则在哈希表中为后插入的数据元素另外选择一个表项。
当程序查找哈希表时,如果没有在第一个对应的哈希表项中找到符合查找要求的数据元素,程序就会继续往后查找,直到找到一个符合查找要求的数据元素,或者遇到一个空的表项。
(2) 链地址法
将哈希值相同的数据元素存放在一个链表中,在查找哈希表的过程中,当查找到这个链表时,必须采用线性查找方法。
-
查找结果
| 查找算法 | Hash查找(成功) | ||||
|---|---|---|---|---|---|
| 数据规模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找时间(单位:ms) | 0 | 0 | 0 | 0 | 0 |
| 最大查找时间(单位:ms) | 0.0001 | 0.0001 | 0.0001 | 0.0001 | 0.0001 |
| 平均查找时间(单位:ms) | 2e-005 | 1.4e-005 | 1e-005 | 2.2e-005 | 1.3e-005 |
| 查找算法 | Hash查找(失败) | ||||
| 数据规模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找时间(单位:ms) | 0 | 0 | 0 | 0 | 0 |
| 最大查找时间(单位:ms) | 0.0001 | 0.0001 | 0.0001 | 0.0002 | 0.0001 |
| 平均查找时间(单位:ms) | 2.5e-005 | 1.8e-005 | 2.6e-005 | 2.7e-005 | 1.9e-005 |
| 查找算法 | 顺序查找(成功) | ||||
| 数据规模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找时间(单位:ms) | 0 | 0.0001 | 0.0001 | 0.0011 | 0.043 |
| 最大查找时间(单位:ms) | 0.0014 | 0.0131 | 0.0299 | 0.6088 | 2.5673 |
| 平均查找时间(单位:ms) | 0.000224 | 0.001744 | 0.012086 | 0.1256 | 1.24673 |
| 查找算法 | 顺序查找(失败) | ||||
| 数据规模 | 100 | 1k | 10k | 100k | 1M |
| 最小查找时间(单位:ms) | 2.0865 | 2.0858 | 2.0813 | 2.08311 | 2.0834 |
| 最大查找时间(单位:ms) | 3.4584 | 2.9283 | 3.0102 | 2.7519 | 3.2602 |
| 平均查找时间(单位:ms) | 2.26678 | 2.23546 | 2.23569 | 2.21732 | 2.21285 |
实验结果分析:
Hash查询时间几乎为0,所花时间基本上是在建立hash表时。hash查找较顺序查找的优势体数据量越大越明显.从理论上来看,hash查找的时间复杂度为O(1),顺序查找的则为O(n);hash查找的劣势是建hash表花时间过多,当然这也跟hash表的设计有关;
从实验来看,hash查找用于数据量巨大,查询频繁的情况下.
知道了上面这些后,我们就开始写代码
(1)首先是随机数文件的生成,方法有很多。额外创建success和fail的txt文件,用于对随机数的成功和失败的查找。
如下
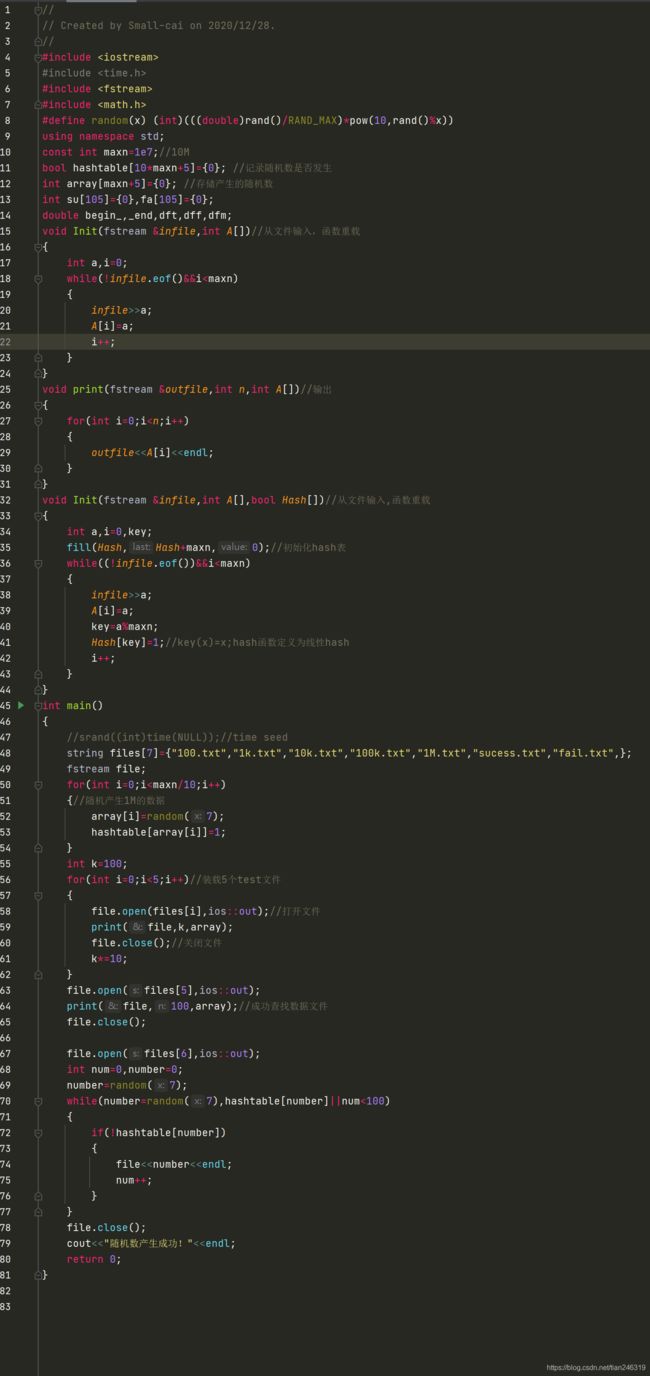
生成后的文件如下图所示

![]()
(2)接下来是对每一组测试数据分别进行100次成功和失败查找
/*
Created by Small-cai
Data: 12/28 12:56
*/
#include 最后,文件下多出

信安应怜儿和你一起努力~