R语言 面板数据分析 plm包实现(固定效应模型和组内模型)
这里写目录标题
- 1.安装plm包
- 2.问题描述
- 3.pool 模型
- 4.个体固定效应的Panel模型——不考虑时间差异,考虑公司差异的估计
-
- 4.1LSDV模型
- 4.2组内模型(within)
- 5 时间固定效应Panel模型——考虑时间差异忽略公司差异
- 6.个体和时间双维固定效应模型--Panel数据
- 7.可供参考的资料
1.安装plm包
可能会遇到错误:

采用这个指令进行安装:
install.packages("plm",type = "binary")
library(plm)
安装完成
2.问题描述
有数据集:Ex1_1.dta
数据样式:
点击下载
解释:

3.pool 模型
![]()
Pool模型本质上是对变量去整体均值后进行 OLS 估计,也可以用plm包提供功能实现
首先对数据进行处理使其变为data.frame
rankData<-pdata.frame(Ex1_1,index=c("FN","YR")) #index里是个体和时间,转化为面板数据
pool <- plm(I~ F + C,data=rankData,model="pooling")
summary(pool)
结果:

特别的,和OLS做对比
ols = lm(I~ F + C,data=rankData)
summary(ols)
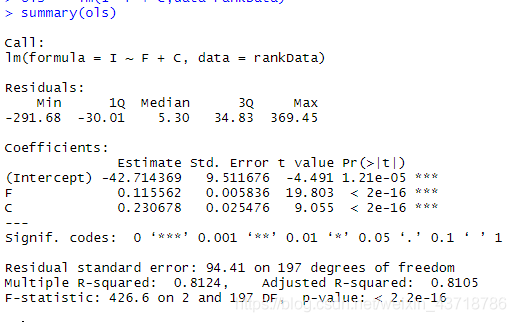
可见,结果是一样的,从软件结果进一步证实了数学推导,即忽略个体均值和时间差异的pool模型等价于OLS模型。
4.个体固定效应的Panel模型——不考虑时间差异,考虑公司差异的估计
![]()
4.1LSDV模型
增加一个factor因子即可:
注意:factor-1才能展现出十家公司,因为事实上公司设置了虚拟变量
LSDV = LSDV = lm(I~F+C+factor(FN)-1,data = Ex1_1)#factor-1才能展现出十家公司,因为事实上公司设置了虚拟变量
summary(LSDV)
结果:

解读:
-
F,C分别代表企业流通股票总价值和企业资本存量,此外还展示了 分别以十家公司做虚拟变量的估计结果,即不同公司是否显著影响企业的投资。
即总共估计的参数是2+9共11个(9个虚拟变量是为了防止完全的多重共线性)
4.2组内模型(within)
rankData<-pdata.frame(Ex1_1,index=c("FN","YR"))#第一个参数是面板的个体,第二个参数是面板的时间
within <- plm(I~ F + C,data=rankData,effect = "individual",model="within")
#within组内方法,检验不同个体是否存在差异(忽视时间影响)
summary(within)
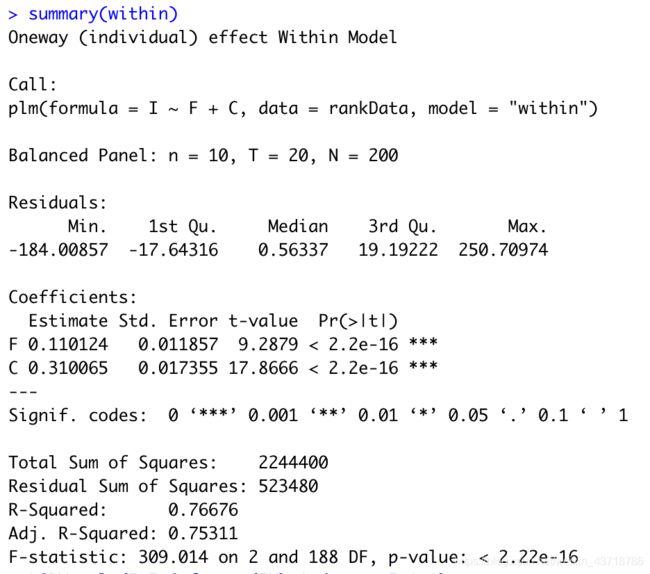
解读
- 公司股票价值每增加一个单位,对企业投资的贡献为0.11个单位;公司实际资本存量每增加一个单位,对企业投资对贡献为0.31个单位,这两个解释变量对被解释变量对贡献程度为75.31%
5 时间固定效应Panel模型——考虑时间差异忽略公司差异

采用组内模型进行估计(也可用4.1方法进行估计)
rankData<-pdata.frame(Ex1_1,index=c("FN","YR"))#第一个参数是面板的个体,第二个参数是面板的时间
within2 = plm(I~ F + C,data=rankData,effect = "time",model="within")
#within组内方法,检验不同时间是否存在差异(忽视个体影响)
summary(within2)

解读:
- 用第4节中相似的办法可以解读
6.个体和时间双维固定效应模型–Panel数据

rankData<-pdata.frame(Ex1_1,index=c("FN","YR"))#第一个参数是面板的个体,第二个参数是面板的时间
within3 <- plm(I~ F + C,data=rankData,effect = "twoways",model="within")
#twoways参数既考虑个体效益,也考虑时间效应
summary(within3)

解读
解读类似上面。此外F,C的F检验都是显著的(F,C后面的三个星号*)。拒绝全为0的原假设。
7.可供参考的资料
从经管之家帖子看到的
R计量的不多,你下载下面的书去看面板的章节把
Applied Econometrics with R
伍德里奇的配套的书
Principles of Econometrics with R https://bbs.pinggu.org/thread-4805190-1-1.html
或者看 plm包的说明文件(个人不太推荐,感觉写的不清楚)
helphttps://www.jstatsoft.org/article/view/v027i02
https://cran.r-project.org/web/views/Econometrics.html