严格冷启动问题的再次尝试AGNN及代码
hi各位大佬好,我是百变大魔王探花小明哥GBM.问题来源:领导说,这里要当成严格冷启动问题,不能用预热的行为数据,看来之前的LCE是肯定不行的,目前主要解决的是item冷启动的问题,而对这些cold item的点击行为也是冷的用户,卧槽,这是真的冷啊。冰冷的梦里,无法跟你相聚。
For Recommendation in Deep learning QQ Group 277356808
For Visual in deep learning QQ Group 629530787
I'm here waiting for you
不接受这个网页的私聊/私信!!!
开始——
MF是CF中最流行的方法(效果好呗)。给定一个M*N的点击行为(user M个,item N个),首先学习到低纬的user或者item隐向量,然后采用一个评分函数生成矩阵中缺失的分数。其中稀疏性和冷启动问题则是比较困难的。传统的方法例如inductive learning,meta learning及HIN都不符合严格冷启动,因为他们都需要user/item在测试集中有行为。当缺乏偏好信息,比如,当一个新的电影上映,它就是个新的(冷的)item,那么是不知道bob对它的评分的,幸运的是,item的属性信息,例如导演和种类,可以代表这个item,因而,当电影有同样的属性就可以形成图,这样就能传递邻节点偏好信息,比如从美队到复仇者。但是仍旧有两个问题摆在面前,1,如何转化属性表达为偏好表达;2,如何有效地聚合不同形式的属性(文字和图像)。AGNN中首先采用一个扩展的变分自编码器(VAE)产生偏好embedding(从重构的属性分布中),另外也设计了一个gated-gnn聚合复杂的节点embedding,这样模型有一个跳跃能力,因为可以指定节点embedding每个维度的不同重要性。
问题定义
令![]() ,M 和N是个数,分别是用户和item,除此之外,每个用户和item都有一系列不同领域的属性。每个属性都有离散编码,所有的属性拼接成multi-hot属性编码,示例
,M 和N是个数,分别是用户和item,除此之外,每个用户和item都有一系列不同领域的属性。每个属性都有离散编码,所有的属性拼接成multi-hot属性编码,示例![]() 分别是性别,年龄,职业。令R是交互矩阵(也就是行为矩阵),可以是分数或者点击与否。这就是典型的热启动评分预测问题,目标是预测未知的评分。而一般的冷启动问题是,在训练集中没有user或者item,而在测试集中有交互。如下示例:
分别是性别,年龄,职业。令R是交互矩阵(也就是行为矩阵),可以是分数或者点击与否。这就是典型的热启动评分预测问题,目标是预测未知的评分。而一般的冷启动问题是,在训练集中没有user或者item,而在测试集中有交互。如下示例:

图a和图b不同之处是NV和NU在测试集中无有评分(一般冷启动的图a有交互行为),而图b则没有,测试集中也没有交互行为,也就是预测NV或者NU的交互。
模型概览
一个输入层,一个交互层,一个gated-gnn层,一个预测层。gnn用来处理严格冷启动中的user或item的属性,VAE结构用来从属性近似用户的偏好,gnn则是用于信息过滤或者聚合。如下所示,整体架构

按照领导的思路,他肯定会问,U-U 图和I-I图是怎么构建的,卧槽,paper作者也没给出个详细介绍,代码也有些繁杂,我还是提个issue吧.
模型结构
不同于两部分的user-item 图,模型是在现有的同样属性图上,这样使得模型能够摆脱稀疏交互。属性的质量是关键,在本文采用一个很自然的近似方法构建属性图,也会对比不同图构建方法的影响。首先定义两种近似:偏好近似,属性近似。1)偏好近似度量两个节点历史偏好的相似性。如果两个users有相似的评分记录(或者两个items有相同的评分表),那么他们将有一个高的偏好近似。注意,对严格冷启动节点,因为没有历史评分,所以不能计算偏好近似。2)属性近似度量两个节点的属性的相似度。如果两个users有相似的用户画像(性别,职业,类别),那么他们将有高的属性近似。近似的计算方法:
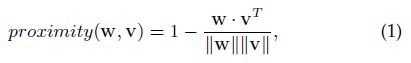
w和v是两个节点的偏好表达或者multi-hot属性编码。两种类型的近似经min-max norm后得到最终的近似,然后sum。因近似是在多种属性上进行的,有必要保留多样性邻居。
大数据量下的one-hot表达维度高,而multi-hot仅仅是拼接在一起(像极了相亲)而没有考虑交互关系。交互的目的就是减少one-hot维度,为multi-hot学习到高阶属性交互。为了这个目的,首先建立一个查询表,将节点的one-hot表达降低到dense向量。查表层对应两个参数矩阵M,N,每个输入![]() 编码用户的偏好和item的属性。注意,
编码用户的偏好和item的属性。注意,![]() 对严格冷启动是无意义的,因为没有交互训练他们的偏好embedding,稍后再说。通过双向交互pooling操作捕获高阶属性交互,除此之外也有线性联合操作。令
对严格冷启动是无意义的,因为没有交互训练他们的偏好embedding,稍后再说。通过双向交互pooling操作捕获高阶属性交互,除此之外也有线性联合操作。令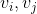 分别为第i和j个类型的属性embedding向量,a是multi-hot属性编码。
分别为第i和j个类型的属性embedding向量,a是multi-hot属性编码。
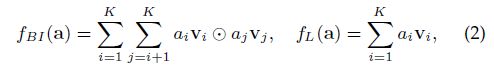
然后有一个FC,得到user或item的embedding
![]()
![]()
然后融合偏好embedding和属性embedding得到节点embedding,这样每个节点都有历史偏好和本身的属性。分号是拼接操作
![]()
对于严格冷启动问题,节点没有交互,那么就是偏好缺失问题,则直接从属性embedding重构偏好embedding。一类用户喜欢的item是类似的,比如,十几岁的少年可能感兴趣的是动画片。这就说明,属性和偏好embedding不就在隐空间相近,而且有类似的分布。因此,采用VAE结构重构偏好。提出的扩展VAE如上Fig3b,有三部分,推断,产生,近似,前两部分是标准的VAE,第三个是扩展的,在产生部分,u给定一隐变量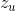 通过MLP生成。这部分略过(主要是 有点困了)
通过MLP生成。这部分略过(主要是 有点困了)
直接看gnn部分,a是聚合,f是过滤。给定用户的节点u,其节点embedding为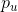 ,其邻集为Nu,节点embedding
,其邻集为Nu,节点embedding ![]() 是Nu中第i个邻居
是Nu中第i个邻居
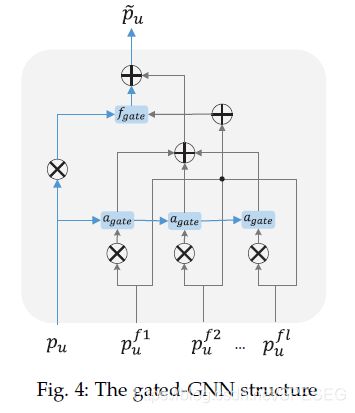
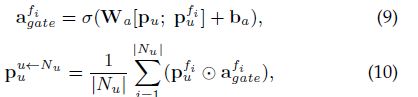
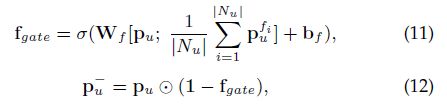
12式就是最终得到的user的embedding,同样可以得到item的最终embedding。
预测层,有user和item的embedding,可以得到user对item的评分

loss部分采用预测评分损失和重构损失(VAE那部分的),前者就是差的平方。评价指标是均方根误差和MAE。1问题是我这里的都是隐式反馈,就是点击与否,没有评分,是不是都是换个loss就好了???不得而知啊,先看代码吧,又是torch的。想起了蹩脚的英语,沟通就是费劲。2问题是我这里的情况是真的冷用户啊,完全不知道他的属性啥的(职业性别没有的,人家一来你让人家填这个玩意,人家都走了),这个实际应用还是有点难度啊。
代码上面已经附过了。挖个坑,下次再填吧。不好整。