分享狼叔关于《大前端工程化的实践与思考》
前言
本文来自极客前端训练营的主题公开课,非原创。
作者简介
桑世龙(狼叔),阿里巴巴前端技术专家,nodejs《狼书》作者。
快速发展的大背景
前端发展太快了,在2004年之前,大概只要会网页三剑客(一套强大的网页编辑工具,最初是Macromedia公司开发的,由Dreamweaver、Fireworks、Flash三个软件组成)就很牛了,那时候前端还比较“纯洁“。在进入以Ajax为代表的异步刷新改进用户体验的Web 2.0时代后,开始涌现出大量的库,比如Prototype、jQuery、MooTools、YUI、Ext JS、kissy等,它们都还只是对浏览器兼容性和工具类函数的封装,可是从Backbone、Angular 1.x相继出现后,前端就开始热闹起来了,出现MVC、MVVM、IOC(控制反转,Java著名框架Spring里的概念)、前端路由(类似于Express、Koa等框架的路由)、Virtual DOM(虚拟DOM,通过DOM Diff算法,减少对DOM操作)、JSON API(接口规范)、JavaScript Runtime(Coffee、Babel、TypeScrpt)等等,各种框架格式如雨后春笋一样冒出来,以前可能半年甚至更长时间才出一个框架,现在可能几周就有新的框架诞生,前端进入了空前的爆发阶段。
图解2004-2016变化
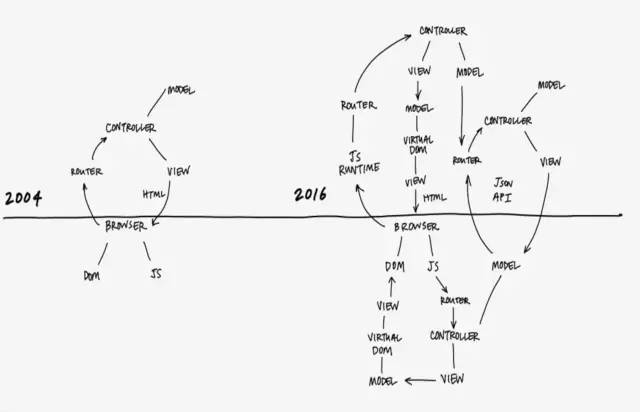
前端经历过的几个阶段
现在前端开发也复杂到了一定程度,对比之前的开发方式,可以称为现代Web开发。这里我来做一个总结,前端发展经历了4个阶段:
目前前端的发展状态
目前整个大前端还属于发展期,没有形成固定模式,所以从趋势上看是上升期,复杂、混乱、多样性的结果也导致现在的前端比较吃香,被大家戏称为“钱端”。很多同学会问,学习前端技术是采用渐进式方式,还是上来就直接学React/Vue.js等框架呢?实际上,我认为这两种方式都存在,如果有经济压力就向“钱“看,可以直接学习React/Vue.js等框架,但学会了之后,一定要把其他3个阶段补充学习完;如果没有经济压力,又有时间和耐心的话,循序渐进的学习是最好的方式。编程没有捷径,无论是哪种,都需要脚踏实地多多练习。
当你代码写多了,就会发现:
于是,前端开发变得复杂,并进入现代Web开发时代。

nodejs
对于Node.js来说,所有前端框架都是视图层(View)的展现技术而已,可以非常方便地和各种框架集成,并按照业务需求予以更好的实现。另外,所有的前端框架都采用Node.js和NPM作为辅助开发工具,使用了大量Node.js模块,但前端框架使用的模块大同小异,如果熟练掌握了Node.js和NPM,对于学习前端技术来说,你要学的只是纯前端的部分而已,复用价值非常高。
和Node.js相关的前端开发模块实在是太多了,这里简单列举一些:
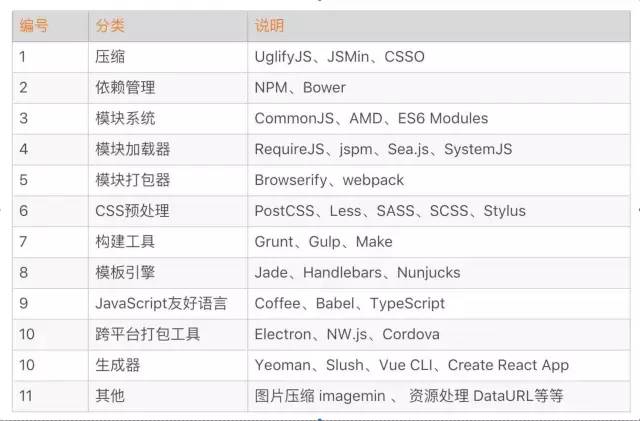
由这些模块,也就引出了我们今天要聊得话题——大前端工程化实践与思考。
构建工具
先来说说构建工具。预处理器是前端高级玩法。

我经常开玩笑说以前HTML/JavaScript/CSS的时代太纯洁了,现在随便写哪样都要编译/转译。好处是可以借助高级特性,提高开发效率;缺点也是极其明显的,就是人脑要有转换思维。这其实是蛮痛苦的,本来HTML/JavaScript/CSS就不够熟练,再转一次,对于新手来说需要一个适应过程。所以这件事还是要辩证地看,福祸相依。
说起构建工具,大概都会想到Make、Ant、Rake、Gradle等,其实Node.js世界里有更多实现。

选用构建工具最主要的目的是为了自动化。对于需要反复重复的任务,例如压缩(minification)、编译、单元测试、linting等,自动化工具可以减轻你的劳动,简化你的工作。尤其是工程越复杂,自动化的价值就越大。这里的编译包含模板、CSS预处理语言、JavaScript友好语言等编译,在源码编写时用的是高级玩法。
除了编码编译外,还有测试、代码风格检查、上线前优化(合并、压缩、混淆),可以说,构建系统在整个软件工程里无处不在。
grunt
Grunt除了配置复杂外,还有一个问题就性能,可能很多同学遇不到性能问题。Grunt是读写文件的,所以在多文件、大文件处理时是有性能瓶颈的。
Grunt的设计还是挺精巧的,但配置起来让人抓狂,自然会有很多不爽的人,于是Gulp就慢慢崛起了。
Gulp
简单来讲,Gulp是一个Node.js写的构建工具,基于Stream的流式构建工具,它包含大量插件。Orchestrator是Gulp底层依赖的task相关的核心库,它定义了task执行方式和依赖,而且支持最大可能的并发,Gulp的高效即来源于此。本身Stream对大文件读写就非常棒,再加上上面说的种种特性,使得Gulp流行成为必然。
Gulp的应用场景非常广,前端项目或Node项目都可以使用,哪怕是webpack也可以和Gulp搭配使用,通过gulp-webpack模块即可。如果想深入学习Gulp,可以看一下stuq-gulp(github.com/i5ting/stuq…),文中以WeUI里Gulp用法为例,由浅入深,从用法到原理进行了阐述。
模块化
解耦是软件开发领域永恒的主题,而模块化是目前最好的解耦方式,所以从无到有、从有到成熟的演化,必然要经历很长的路。如今的发展,源于1993年HTML创建、1995年诞生JavaScript、1996年发布CSS1,之后就进入了原始而野蛮的开发阶段。从互联网诞生到2000年泡沫破灭,Web技术才算真正崛起。那时候特别纯洁,会写的人就很牛了,之后Flash也曾超级火爆。在之后就到了Web 2.0时代,开始出现Ajax,开始有了各种兼容浏览器的库,然后开始模块化,在2009年诞生了Node.js,彻底改变了JavaScript以及前端开发领域的开发方式,从浏览器端的Backbone支持MVC模式,到AngluarJS支持的MVVM,到现在的React/Vue和webpack等。
这里我尝试从更宏观的视角来进行归类,大致分5个阶段,分别是原始阶段、包管理器、模块规范、模块加载器、模块打包器。下面我来一一说明。
原始阶段
脚本加载还都比较原始,方式如下:使用多个script标签加载、手动管理顺序、手动管理加载哪些。
在Web开发里经过了很多尝试,也做过很多龌蹉的事儿,比如
如果说加载比较恶心,那么脚本顺序更恶心,而且JavaScript有个“特性”,一处报错,所有后面的都会崩溃,所以开发会很苦的维护脚本加载的顺序。
包管理器
很明显,直接进行文件操作是非常低效率的做法,对于版本、依赖都没法做更好的处理。于是就出现了Bower、NPM等包管理器,所有模块升级,依赖都有包管理负责,可以说很大程度上省去了前端的重复性工作。
模块规范
模块化加载的本质是按需加载。
模块加载器
模块加载器需要实现两个基本功能:
常见的比如RequireJS、Sea.js和SystemJS。以AMD的模块加载器RequireJS为例,通常使用RequireJS的话,我们只需要导入RequireJS即可,不需要显式导入其他的JS库,因为这个工作会交给RequireJS来做。
模块打包器
对于开发来说,只需要关注业务模块,不需要了解模块加载器和构建过程,很明显这是非常理想的,也因此产生了webpack这样的模块打包器。
Gulp作为通用构建工具,它已经非常完美了。但技术变革太快了,应用各种预处理器、前端组件化,导致前端无比复杂,而webpack的出现刚刚好,完美解决了前端工程化的问题。
webpack基本介绍
webpack是Node编写的著名模块,是打包器(bundler),不只是支持CommonJS模块,而且还支持更潮的ES6模块,是目前使用极其广泛的打包器,像前端组件化的框架(React、Vue)大多都是使用webpack的。
loader && plugins
它提供了两个极其好的机制:loaders和plugins。
loaders:webpack认为每个文件都是资源模块,针对打包构建过程中用来处理源文件的(JSX、SCSS、Less..)统称为loader。
plugins:插件可以完成更多loader不能完成的功能。插件并不直接操作单个文件,它直接对整个构建过程起作用,大多数内容功能都是基于这个插件系统运行的;当然还可以开发和使用开源的webpack插件,来满足各式各样的需求。比如知名插件autoprefixer、html-webpack-plugin、webpack-dev-middleware、webpack-hot-middleware。
webpack打包过程
浏览器加载过程
(1)通过