数据库理论:ER模型,关系转换,并发控制与冲突可串行化调度
目录
- 前言
- ER模型
-
- 实体
- 属性
- 关系
-
- 参与
- 关系的度(degree)
- 一对一与一对多
- ER 图符
- 关系转化(重要)
- 并发控制
-
- 概述
- 并发控制中的不一致性
-
- 修改丢失
- 不可重复读
- 脏读
- 封锁技术
- 封锁三协议
-
- 第一封锁协议
- 第二封锁协议
- 第三封锁协议
- 活死锁
-
- 死锁预防
- 死锁诊断
- 死锁解除
- 并发调度的可串行性(重要)
-
- 可串行化调度
- 冲突可串行化调度
-
- 冲突操作
- 例子
- 两段锁
- 封锁粒度
-
- 隐式锁
- 意向锁
- 锁的强度
前言
今天小测,赶快抱佛脚 Orz 。。。。
编辑下,小测炸了,投啦投啦
注:
前半部分是个人对全英 ppt 的翻译,大家就当看个笑话,不保证准确性。。。
后半部分是中文 ppt 的个人笔记,侵删。
ER模型
ER 模型,又名 “实体关系模型”,洋文叫 Entity - Relationship Model,是数据库结构设计的第一步,也是至关重要的一步,因为其决定了一些数据库的约束细节。
实体
实体是客观世界的一个描述。比如学生 “小明” 是一个实体。而实体集合则描述了一群实体,比如 “越南大学的所有学生”,或者 “隔壁老王的羊群” 就是实体的集合。

实体又根据其特征分为强弱实体。
其中:
- 能够独立存在,自己(的特征)能够唯一地标识自己,这种实体是强实体
- 必须依赖其他强实体才能唯一地标识自己,这种实体是弱实体
举例:
一个员工是强实体。就比如同一办公室的老习和老江,就不会被人搞混。
一个银行账户是强实体。存款多少?谁拥有?白纸黑字,十分清楚。
一个交易是弱实体,因为必须同时确定 “经手员工” 和 “银行账户” 才能够唯一地描述该交易。比如账户 1145141919810,经过柜台员工老胡,存款 3000 元。账户和员工缺一不可。

属性
属性是一些实体抽象出来的共有属性,比如人的两个肩膀扛一个脑袋,或者是螃蟹的八只脚。
属性分为原子属性和复合属性,其中原子属性不可进一步拆分,比如年龄,性别。而复合属性可以被进一步拆分,比如姓名就可以等价于【姓+名】

关系
关系是实体层面的概念。比如学生实体【老江】报名选修了课程实体【离散数学】,那么这两个实体之间就建立了 “关系”


参与
【参与】这个概念是基于 entity 层面的。值得注意的是,并非所有 entity 都能参与关系 r。
令 R 是实体集合 E1,E2,E…,En 上的一组关系的集合。一个 E1 中的实体 e1 参与关系集合 R,当且仅到 R 中存在包含 e1 的关系(元组)
比如:
- E1=学生实体集合,E2=老师实体集合
- 关系集合 R 中存在一个关系(学生e1,老师e2)
- 其中学生实体 e1 属于 E1,老师实体 e2 属于 E2
- 那么称 e1,e2 参与关集合 R
此外,同一组实体集合,可能他们之间存在不同的关系:
- 比如一个员工在一个部门工作(员工e,部门d)
- 或者是一个员工是该部门的经理(部门d,经理m)。
注:
这段话太拗口了,不 bb 看原文:

此外【R 是实体集合 E1,E2 上的关系】不等价于【E1,E2 中的每个实体都参与 R】,比如不是所有员工都是部门的经理,所以他们并不参与(经理,部门)这个关系。
如果实体集合 E1 中的每个实体都参与关系 R,那么称 E1 完全参与 R。

关系的度(degree)
关系的度即为参与该关系的实体集合数目。

一元关系:即只有一个实体集合参与的关系,度为 1,比如:
- 学生实体 s1 和学生实体 s2 是同学关系,有(s1,s2)和(s2,s1)
- 员工实体 e1 和员工实体 e2 是同事关系,有(e1,e2)和(e2,e1)

二元关系:即两个实体集合参与的关系,度为 2,比如:
- 学生实体 s1 选修课程实体 c1,那么有(s1,c1)
- 人实体 p1 拥有车辆实体 c1,那么有(p1,c1)
注意有向性。。。即谁决定谁

三元关系同理,要注意谁决定谁:

一对一与一对多
关系也有一对 n 的区别。比如一对一的关系就像【丈夫】和【妻子】。
比如对于实体集合 E1,E2。E1 中的每一个实体 e1,最多存在一个 E2 中的实体 e2 与 e1 产生联系。

此外,一对一关系也分一元和二元(对应有向图和无向图),比如:
- 丈夫实体 h 对应妻子实体 w,那么有 二元的一对一 关系:(h,w)和(w,h)
- 妻子实体 w 嫁给 丈夫实体 h,那么有 一元的一对一 关系:(w,h)
注意我们不能说【丈夫】嫁给【妻子】(因为并不存在这个关系,或者说不存在反向边)
反过来【妻子】嫁给【丈夫】是合理的一元关系,百合除外!
pid=85524069

有 1 就有 n,一对多关系更多地应用于数据库中。比如一个学生可以有一个班级,但是一个班级可以对应很多个学生。

和上面的一对一关系一样,多对一关系也分一元和二元(对应有向图和无向图),比如:
- 一场洽谈会,可以有一个导师和 n 个学生。谓语为【洽谈】,于是有关系【学生和老师洽谈】or【老师和学生洽谈】
- 一个母亲实体 m 可以有 n 个孩子 ci,谓语为【是 xxx 的母亲】,但是反过来不能有【ci 是 m 的母亲】

多对多:和上面雷同

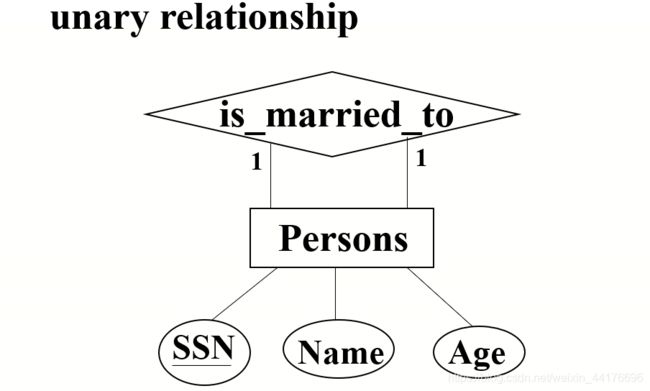
ER 图符
通过一些标准化的图符来描述 ER 模型。



比如我们可以用如下的图来表示名为【嫁给】的 一元一对一关系 :
一对多的二元,三元关系也是同理的:

关系转化(重要)
关系转化是指通过关系图,写出对应的关系元组(或者说是写出数据库表的结构)。这里重要的意思是考试要考。
至于为啥叫【转换】
你问我??
唔。。。。原文是 transform
直译过来就是转换,没毛病 Orz
对于一对一的关系,我们可以用外键的形式给出对应的约束。比如经理和部门之间的一对一关系:

我们通过关系转换,得到两个表,分别是:
- dept(Name,location)
- managers(SSN, Name, Age, Dept_name)
这里仅展示第一种表的划分(下图左侧)。我们把 dept 表的主键 Name,以外键约束的形式,划分到 Manager 表中,表示该经理管理的是哪个部门。
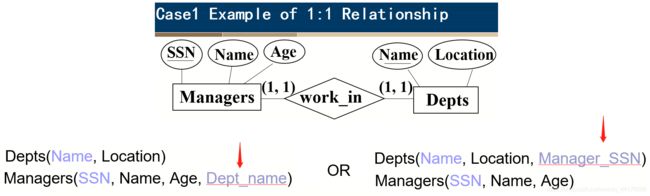
因为是一对一的关系(即一个部门有且只有一个经理)所以我们可以有两种划分表的方式。
值得注意的是,如果面对多对一的关系比如某个员工管理某个部门:
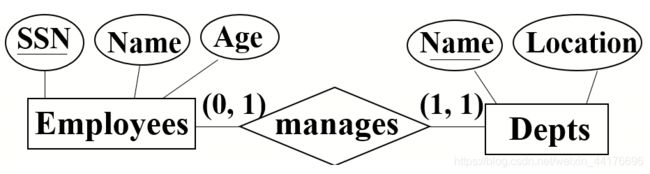
经理也是员工,但并非所有员工都是经理,我们就要小心了:
- 我们只能在部门表 dept 中,以外键约束 manager_SSN 来表示该部门的经理
- 不能在员工表中添加一项外键来表示该员工所管理的部门
- 因为不是所有员工都是经理。
所以我们只能有一种外键的形式,那就是在 dept 表中添加外键,表示谁是该部门的老大:
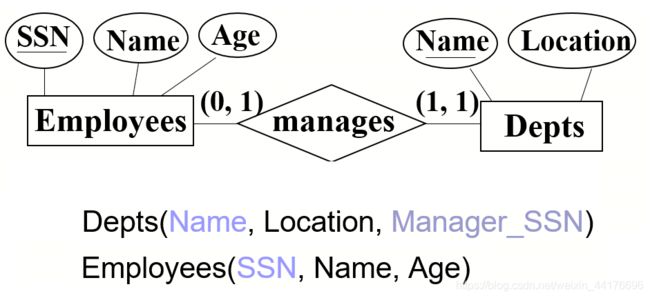
注:
如果你还没有晕,那你就没晕了(雾
这里仅是我的理解
但是,相信我,老师,给的,全英文的,ppt,更加,抽象,只有一张,图

同理,人人都有且仅有一个母亲,于是我们可以通过外键 mother_SSN 来唯一地表示该 person 的母亲。
但是一个母亲可能有多个孩子,于是我们不能使用 child_SSN 来表示一个母亲的孩子。

对于一些复杂的属性,比如姓名又分为【姓+名】,我们一般有两种方案:
- 将复杂属性拆分并且合并到主表中
- 将复杂属性单独作为一个表,然后通过主表的外键约束进行寻址
看图:

我们来做个简单练习:看图,写出表的结构(关系转换),这里使用 method1 进行转换:
method1 不认为 programmer 或者是 manager 为新的类,于是仅使用员工 id(EMP#)来查询 Manager 的 budget 属性和 Programmers 的 Years_of_experience 属性:
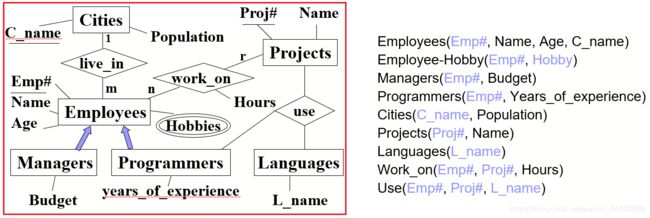
method2 如下,因为将继承的类(programmer 和 manager)看作一张单独的表,于是我们要多写很多条目:

并发控制
数据库往往是很多请求并发的进行,于是涉及到并发控制。
概述
并发控制的核心单位是【事务】,一个事务表示一件事情,比如收钱和出货往往是永不分离的,那么收钱和出货就组成一个事务。
事务具有原子性,一个事务的所有操作要么全部执行,要么全部不执行,否则就会出错。
并发控制中的不一致性
在实际情况,收钱和出货往往不能够做到完全原子化,事实上,出货和收钱都是数据库中的一条 alter 命令,执行两条命令,必有先后!

并发操作会导致三种场景错误情况:
- 丢失修改(前一次修改的结果覆盖后一次修改的结果)
- 不可重复的(读数据在读之后被修改,读的是旧的数据)
- 脏读(读数据之后数据回滚,读的是新的数据)

修改丢失
丢失修改发生于两个事务先后提交修改请求,那么前一次的修改就会被覆盖。
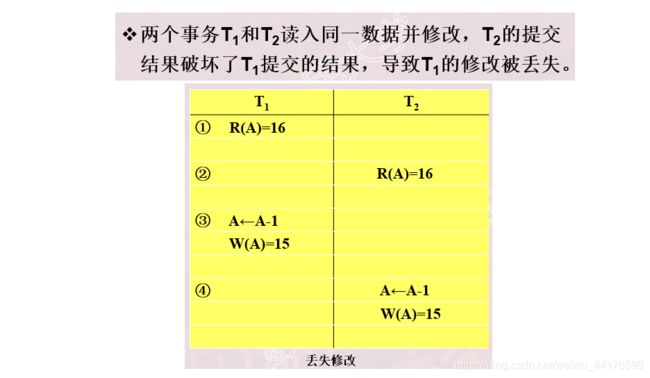
不可重复读
不可重复读指的读请求之后,目标数据马上被修改,导致读的数据是旧的。


脏读
脏读指的是在某个事务 t 之后读数据,t 回滚导致读请求读到的是错误的数据。
(注意与不可重复读区分,区别是:
- 脏读读取的是 “新” 的数据,不可重复读读取的是旧的
- 脏读往往伴随着 回滚 的发生

封锁技术
封锁是一项重要的技术。在对数据进行存取之前,先将数据保护起来,即锁起来。
基本的封锁类型有两类:
- 共享锁(S 锁)
- 排它锁(X 锁)

封锁三协议
锁的基本类型有了,还要进行锁的使用规范。类比数据库三范式,锁的使用也有三协议。
第一封锁协议
一级封锁协议约定:
- 事务 T 在修改数据 R 之前必须对 R 上 X 锁,直到事务结束才释放
因为要修改就要有 X 锁,而 X 锁能够保证当前事务的修改不被覆盖:

第二封锁协议
二级封锁协议约定:
- 事务 T 在修改数据 R 之前必须对 R 上 X 锁,直到事务结束才释放
- 事务 T 在读取数据 R 之前必须对 R 上 S 锁,读完即可释放
因为读数据之前要加 S 锁,而如果数据正在被写,那么根据协议 1,数据上面必有 X 锁,此时 S 锁加不上去,于是避免了可能存在的脏读:

注:
因为 读完我们就释放 S 锁 了
这意味着读完之后,同一数据的修改是当前事务不可控制的了
那么我们无法避免【不可重复读】的异常情况。
第三封锁协议
三级封锁协议约定:
- 事务 T 在修改数据 R 之前必须对 R 上 X 锁,直到事务结束才释放
- 事务 T 在读取数据 R 之前必须对 R 上 S 锁,直到事务结束才释放
因为 S 锁必须等到事务结束才释放,我们的事务可以完全保证要读的数据不被修改(因为改数据要加 X 锁,而 S 锁保证 X 锁加不上去),于是可以防止【不可重复读】的异常情况。

活死锁
有锁必有死锁问题。先来看活锁:
活锁的意思是在多个事务同时请求锁的时候,我们只能随机的给一个事务分配锁,那么就有可能出现一个永远轮不到的锁请求:

解决活锁也很简单,比如制定先来后到的规则即可。主要的难点还是死锁。
来看死锁。死锁是两个事务都互相依赖于对方已经封锁的数据。因为锁在事务结束后释放,那么两个事务永远无法结束,陷入无穷的等待。。。

解决死锁可以从两方面下手:
- 不让死锁产生(预防)
- 解除死锁(拆锁)
死锁预防
死锁的预防是一难题。一般有如下两种方案:
- 一次封锁
- 顺序封锁
一次封锁法,指的是一次性将所有用到的数据都上锁。缺点就是强制将并发事务阻塞成串行事务,降低了系统的并发性。
而顺序封锁法,则是预先规定一组封锁顺序,比如先封锁 A 数据,后封锁 B 数据。人为地制定封锁顺序可以避开死锁发生的情况。难点是方案难以拟定,每更改一个应用场景,都要换方案,十分困难。
死锁诊断
死锁诊断则较为被动。在死锁发生的时候,我们需要判断当前系统是否发生了死锁。常见的方法有:
- 超时法
- 等待图法
超时法很简单。如果上锁超过一定时间,就人为发生死锁。但是弊端也很明显:如果我事务就是要这么长时间呢?
更加流行的方法是使用等待图法,即画出锁之间的依赖图。如果依赖图有环,那么说明会发生死锁!

死锁解除
zsbd。

并发调度的可串行性(重要)
数据库对于并发的事务的不同调度可能会产生不同的结果。
串行调度意为顺序执行 n 个事务(只要不并发就不会有并发问题,经典鸵鸟 )而串行调度的结果是正确的。
此外,执行结果等价于串行调度结果的调度,也是正确的调度。
可串行化调度
可串行化调度的定义是: n 个事务并发的执行,当且仅到其结果 R1,与串行地顺序执行 n 个事务得到的结果 R2,当 R1=R2 时,该调度为可串行化调度。
一个给定的并发调度,当且仅到它是可串行化的,才是正确的调度。
注:
判断一个调度是否是可串行化调度,只要其调度结果,满足任意串行调度的全排列中的一个,即认为其是可串行化调度。
比如事务 A,B,C 有 6 种调度顺序:ABC,ACB,BAC,BCA,CAB,CBA
那么有结果 R1,R2,R3,R4,R5,R6
只要最终调度的结果等于 R1,R2,R3,R4,R5,R6 中的任意一个,即认为该调度是可串行化调度
例子:

如下图:
我们按照 T1,T2 的顺序串行调度,结果为:A=3,B=4
我们按照 T2,T1 的顺序串行调度,结果为:A=4,B=3

如下图:
如果串行执行就会发生问题:结果不属于顺序执行的结果(3,4 或 4,3)中的任意一个,这里就发生了 “不可重复读” 的冲突!

如下图:则是一种正确的调度

冲突可串行化调度
冲突可串行化是一种比 “可串行化” 更加严格的条件,一般在商用系统中调度器采用的都是这种策略。
冲突可串行化要求一组事务的 冲突操作 满足可串行化的条件。那么什么是冲突操作呢?
冲突操作
冲突操作是指 不同事务 对于 同一数据 的
- 【读,写】 操作,互为冲突操作
- 【写,写】 操作,互为冲突操作
其他的不是冲突操作

其中,不能交换的操作有:
- 同一事务的两个操作
- 不同事务的 冲突操作
所以我们可以得出冲突可串行化的的定义:
一个调度在 保证冲突操作顺序不变 的情况下,通过交换两个事务的 不冲突操作,得到一个新调度 S。如果 S 是串行的(结果等于任意一个顺序串行的执行结果),那么称 S 是冲突可串行化的调度。
例子
因为不同事务对于不同数据的【读,写】操作不是冲突操作,故我们交换事务 1,2 对于 A,B 的【读,写】操作的顺序,得到的新调度是合法的。

值得注意的是,可串行化调度,不一定是冲突可串行化调度,因为后者的要求更加严格!

两段锁
两段锁规定了上锁的规范。进一步保证了事务的正确性。两段锁规定一个事务的上锁分为两个阶段:
- 扩展阶段:事务可以申请锁,但是不能释放任何锁
- 收缩阶段:事务可以释放锁,但是不能申请任何锁
两段锁的精髓就是:各取所需,在用完之后马上释放。可以大大提高系统的并发性能

封锁粒度
封锁粒度指的是封锁的规模。我们是要对一条记录上锁?还是一张表?一个页?一个数据库都上锁?
锁的粒度越大,开销也越大,并发性能就越小。

隐式锁
因为数据库中,数据存在树形结构关系,那么对父节点上锁,意味着子节点全部被锁了。
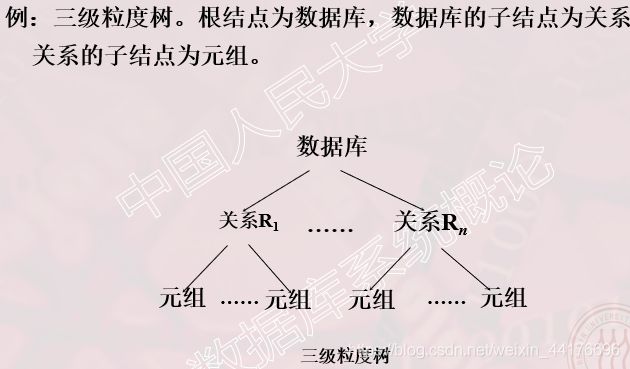
其中隐式锁就是父节点加锁,子节点跟着被锁了。尽管没有直接锁子节点,但是无形的带已经将子节点封锁了。

意向锁
对于一个树形的系统,如果要检查一个节点有无锁,那么理论上应该遍历其所有上级节点,检查上级节点是否被锁,这是开销非常大的。
于是我们引入了意向锁。如果对节点 A 加意向锁,表明 A 的下层节点正在被加锁。意向锁能够大大减少遍历树的过程的开销。

锁的强度
意向锁又分:
- 共享意向锁(IS)
- 排它意向锁(IX)
- 共享排它意向锁(SIX)

于是根据我们的定义,有如下的强度排名:
X > SIX > S = IX > IS
