为什么训练时测试准确率大幅度波动_基于机器学习的流量波动趋势预测实践
1. 概述
本实践数据是基于电商网站——“苏宁易购”的业务访问流量,进行的深入数据挖掘。在此基础上,建立机器学习或统计算法模型,进行离线分析,选取最优模型,对流量波动趋势进行实时预测,实现智能化的异常流量预警。
1.1. 流量预测的价值
流量预测,是流控的重要环节,也是流控迈向智能化的关键一步。对苏宁易购而言,业务系统流量趋势的预测、异常流量的及时预警极为重要,它能够及时提醒用户验证是否有CC攻击、黄牛刷单、爬虫等危害企业网络正常经营活动的行为。
1.2. 流量预测的几大难点
对于流量波动趋势预测、异常流量检测,存在以下难点:
l 需要检测的流量系统种类繁多流量特征各不相同。苏宁易购业务系统众多,每一个系统每分钟产生的流量大小、流量趋势不同,每一分钟的访问业务系统个数不同。
l 流量受业务系统经营活动影响较大。活动力度大、活动频繁,则流量大且稳定;活动力度大、活动稀疏,则流量波动大。面向易购的销售系统,则流量大且稳定;面向内部用户系统,则流量小且波动大。
l 不同用户对流量异常的关注点不同,流量预测难以满足所有场景需求。促销、CC攻击、黄牛刷单、爬虫等,都有可能带来流量的暴增异常。不同人员的关注点不同:运维人员关注流量的暴增是否带来了系统压力;用户则关注流量的异常是否存在某种刷单,是否会带来经济损失;安全人员则关心是否存在某种攻击及信息泄露。要做到一种检测,多方满足,实则难度很大。
l 流量预测需要较高的实时性、有效性。及时感知异常流量,方能及时的进行有效的流控。易购业务总流量TPS大,大促期间流量暴增。需要一种实时高效的计算框架,进行流量的实时计算、在线训练,及时发出异常预警,流量的预测检测才有实际意义。
2. 应用系统流量趋势特征分析
2.1. 横向流量的按天规律性波动
流量受到不同时间段的用户行为影响较大。不同时间段的流量阈值、峰值不同。白天08-18点用户多、流量大,夜间00-08流量下降。
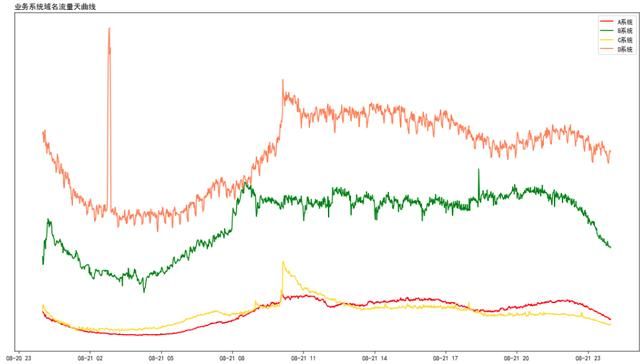
2.2. 横向阶段性流量规律分析
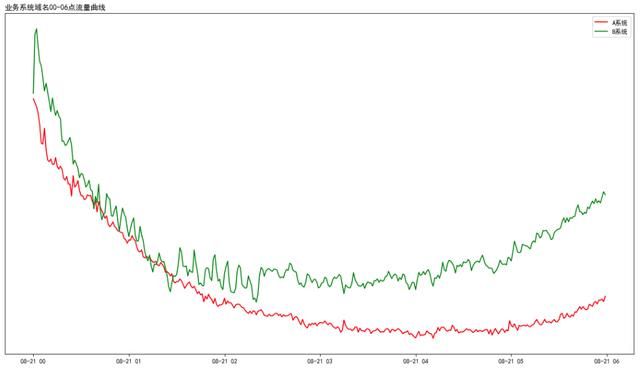
a. 夜间流量小,波动大,如下图所示夜间00-06点流量图(按分钟统计):
b. 白天流量大,波动小。如下图所示白天11-18点流量图(按分钟统计):

2.3. 纵向按分钟周特征分析
取某系统每天同时刻流量数据,取一周数据(按分钟统计):

由上图可知,同系统按天同时刻流量,一周时间内,波动很大,无明显时间规律,因此不利于进行未知流量预测。
2.4. 纵向按分钟月特征分析
取某系统每天同时刻流量数据,取一个月数据(按分钟统计):

由上图可知,同系统按天同时刻流量,一个月时间内,波动很大,无明显时间规律,因此不利于进行未知流量预测。
3. 异常流量预测算法
对于业务域名系统流量的研究,本质是基于时间序列的研究。我们分别使用ARMA(自回归滑动平均模型)/LSTM(长短期记忆网络)/MAD(绝对中位差)+Mean(均值)进行了深入探索。
3.1. ARMA模型
l 算法简介
自回归滑动平均模型(Autoregressive moving average model),是自回归模型(简称AR模型)与移动平均模型(简称MA模型)的组合模型。
将预测指标随时间排列而形成的数据序列看作是一个随机序列,这组随机变量所具有的依存关系体现着原始数据在时间上的延续性。一方面,影响因素的影响,另一方面,又有自身变动规律,假定影响因素为 , ,…, ,由回归分析:
其中Y是预测对象的观测值,Z为误差。作为预测对象 受到自身变化的影响,其规律可由下式体现:
误差项在不同时期具有依存关系,由下式表示,
由此,获得ARMA模型表达式:
l 拟合误差方程
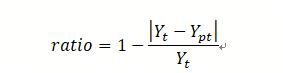
其中t时刻的准确率ratio,真实值 ,预测值 。
l 特征工程
a. 取某业务系统域名某一天08-10点的按分钟统计的流量总量时序数据进行训练,流量趋势如下:(时序数据的统计时间间隔可以为天/小时/分钟/秒等,按分钟统计及预测是最符合系统流量预测场景需求的,以下研究都是基于按分钟统计的时序数据)

b. 平稳性判断及处理,对序列进行一阶差分处理,序列处于平稳状态,处理后的流量趋势图如下(判断/处理平稳性方法略):

l 效果查看
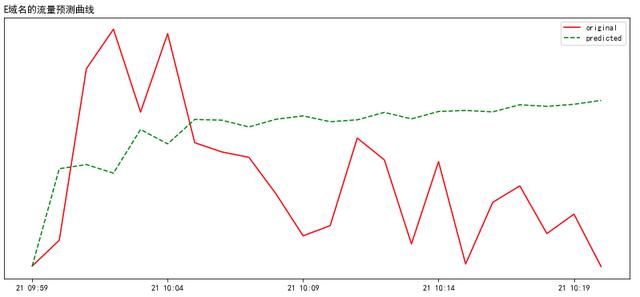
按分钟预测,不同时间长度后的预测拟合效果如下:
l 优缺点分析
优点:
a) 存在成熟的预测接口,可直接预测多步时间间隔数据
b) 距离当前时间越近,准确率越高
缺点:
a) 距离当前时间越久,准确性越差
b) 波动较大的序列经过二阶差分后仍然不平稳,序列平稳性处理有误差,导致模型预测出现误差
c) 模型训练耗时长,不适合大规模批量实时预测
d) 不同系统的流量趋势不同,存在众多域名系统,难以训练某一个模型可以全部满足所有的流量系统
3.2. LSTM模型
l 算法简介
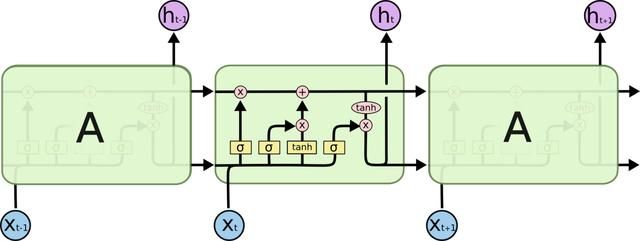
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络。它是RNN的优化模型,可以解决RNN模型的梯度消失与不可记忆长时间依赖问题,是目前解决序列问题最常用的方式。
l 拟合误差方程
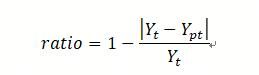
其中t时刻的准确率ratio,真实值 ,预测值 。
l 特征工程
同ARMA模型一致,选取某业务域名系统某一天08-10点的按分钟统计的流量总量时序数据进行训练,并切割训练集、测试集,流量序列趋势不再赘述,特征工程处理步骤如下:

a. 差分处理:基于平稳性的考虑,进行一阶差分处理
b. 监督式转换:使用pandas shift操作,进行1位位移,X为序列的一阶差分结果(a中的结果),Y为一阶差分后的shift(1),如下所示

c. 数据集切割:略
d. 标准化转换:MinMaxScaler将数据处理至[-1,1区间]
l 效果查看
a. 将数据集转换成有监督学习后,测试集数据的预测结果表现如下:

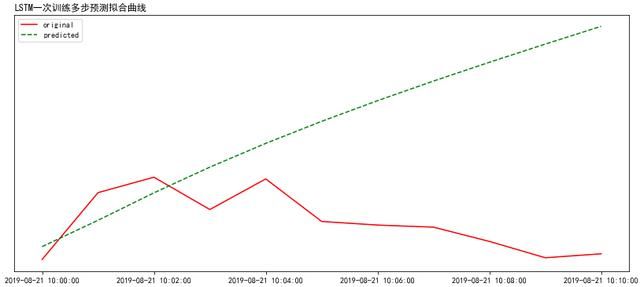
b. 一次训练,多步叠加预测结果:(注:LSTM无多步预测接口,可讲新预测数据添加到原始数据序列最后,又作为原始数据进行预测,如此反复循环,得到多步预测结果)
l 优缺点分析
优点:
a) 距离当前时间越近,准确率越高
缺点:
a) 距离当前时间越久,准确性越差
b) 无多步预测接口。需以新预测数据为新的时序数据,不断叠代方可预测完成
c) 模型训练耗时长,不适合大规模批量实时预测
d) 不同系统的流量趋势不同,存在众多域名系统,难以训练某一个模型可以全部满足所有的流量系统
3.3. MAD估计值模型
l 算法简介
采用统计学习方法对流量进行预测,计算MAD(绝对中位差)估计值,算法原理如下:

k 为比例因子常量(可视为流量预测的波动系数),值取决于分布类型,流量预测具体值为离散型随机变量。流量序列繁多,统一按正态分布数据计算,对于正态分布,k值为:
也就是标准正态分布 的分位函数的倒数(也称为逆累积分布函数)。数值3/4是为了 包含标准正态累积分布函数的50%(从1/4到3/4的范围值)
l 误差方程
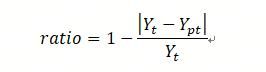
其中t时刻的准确率ratio,真实值 ,预测值 。
l 特征工程

l 效果查看
a. 预测2min的数据拟合情况:

b. 预测4min的数据拟合情况:

c. 预测8min的数据拟合情:

a/b/c三幅图分别为预测2min/4min/8min以后的拟合曲线,通过开始时间、峰值等时间点可以看出,时间步长越长,拟合效果越差。
l 优缺点分析
优点:
a) 特征工程简单
b) 支持实时快速计算,可进行所有流量序列的实时预测
缺点:预测步长距离当前时间越久,准确性越差。因为后2min的预测强依赖当前总量,步长越长,当前总量的关联性越弱
4. 分析总结
本篇主要介绍了流量预测的横向分析,因为横向数据与当前时间点的流量关联最为密切。纵向数据时间跨度大,具有一定的规律性,但是实时关联性不高。比如大促期间流量较平时会成倍增长。因此纵向数据波动性大,不确定因素众多,不利于进行流量预测。
易购的众多业务系统流量存在两大普遍特征:1.白天流量趋势稳定,数据量大;夜间流量趋势波动大,数量量小;2.以天为单位,业务系统呈现规律性波动。
算法最终选择了统计模型,原因为特征工程简单、时效性强、拟合准确率高。ARMA、LSTM均不能满足时效性要求。不论是选择机器学习算法、深度学习神经网络,或者统计模型,在多步长预测问题上,预测效果均会变差。
本例中未使用RMSE、MAE、MSE等方差类统计指标进行模型评估,原因为不同的业务系统,流量趋势、总量不一致,计算出的均方误差等结果差别大,难以确定统一的阈值评判预测结果的好坏。本篇采用了自定义的误差结果计算方法:

对单用户的预测结果进行误差判别,实践中可以取得良好效果。
5. 展望
正如开篇所讲流量预测的几大难点之一,不同用户对流量波动的关注点不同,流量预测难以满足所有场景需求。促销、CC攻击、黄牛刷单、爬虫、用户轨迹异常等,都有可能带来流量的暴增异常。针对异常行为做机器学习分类判断、建立统计学模型等,借助与flink、spark等大数据分析框架,实现快速异常定位,是流量预测的下一阶段——异常检测的重要研究方向。
作者信息:
苏宁科技集团云计算研发中心算法工程师脱利锋,毕业于江西理工大学信息安全专业,目前致力于苏宁AI方向的web安全防护工作,主要研究方向为异常流量的预