python实现Canopy算法
序
前两个月在做项目突然发现Canopy算法发现网上直接用python实现的不多,因为Mahout已经包含了这个算法,需要使用的时候仅需要执行Mahout几条命令即可,并且多数和MapReduce以及Hadoop分布式框架一起使用,感兴趣的可以在网上查阅。但出于学习和兴趣的态度,我更想尝试用python来亲自实现一些底层算法。
简介
The canopy clustering algorithm is an unsupervised pre-clustering algorithm introduced by Andrew McCallum, Kamal Nigam and Lyle Ungar in 2000.[1]
It is often used as preprocessing step for the K-means algorithm or the Hierarchical clustering algorithm. It is intended to speed up clustering operations on large data sets, where using another algorithm directly may be impractical due to the size of the data set.
以上面出自于维基百科.
Canopy算法是2000年由Andrew McCallum, Kamal Nigam and Lyle Ungar提出来的,它是对k-means聚类算法和层次聚类算法的预处理。众所周知,kmeans的一个不足之处在于k值需要通过人为的进行调整,后期可以通过肘部法则(Elbow Method)和轮廓系数(Silhouette Coefficient)来对k值进行最终的确定,但是这些方法都是属于“事后”判断的,而Canopy算法的作用就在于它是通过事先粗聚类的方式,为k-means算法确定初始聚类中心个数和聚类中心点。
Canopy算法过程:
The algorithm proceeds as follows, using two thresholds
T1 (the loose distance) and T2(the tight distance), whereT1>T2[1][2]
1.Begin with the set of data points to be clustered.
2.Remove a point from the set, beginning a new ‘canopy’.
3.For each point left in the set, assign it to the new canopy if the distance less than the loose distance T1.
4.If the distance of the point is additionally less than the tight distance T2, remove it from the original set.
5.Repeat from step 2 until there are no more data points in the set to cluster.
6.These relatively cheaply clustered canopies can be sub-clustered using a more expensive but accurate algorithm.
中文说明可以参考Canopy聚类算法(经典,看图就明白)。
代码实现
使用的包:
# -*- coding: utf-8 -*-
# @Author: Alan Lau
# @Date: 2017-09-05 22:56:16
# @Last Modified by: Alan Lau
# @Last Modified time: 2017-09-05 22:56:16
import math
import random
import numpy as np
from datetime import datetime
from pprint import pprint as p
import matplotlib.pyplot as plt1.首先我在算法中预设了一个二维(为了方便后期画图呈现在二维平面上)数据dataset。当然也可以使用高纬度的数据,并且我将canopy核心算法写入了类中,后期可以通过直接调用的方式对任何维度的数据进行处理,当然只是小批量的,大批量的数据可以移步Mahout和Hadoop了,反正我的算法肯定没它们好哈哈。
# 随机生成500个二维[0,1)平面点
dataset = np.random.rand(500, 2)2.然后生成个类,类的属性如下
class Canopy:
def __init__(self, dataset):
self.dataset = dataset
self.t1 = 0
self.t2 = 0加入设定t1和t2初始值以及判断大小函数
# 设置初始阈值
def setThreshold(self, t1, t2):
if t1 > t2:
self.t1 = t1
self.t2 = t2
else:
print('t1 needs to be larger than t2!')3.距离计算,各个中心点之间的距离计算方法我使用的欧式距离。
# 使用欧式距离进行距离的计算
def euclideanDistance(self, vec1, vec2):
return math.sqrt(((vec1 - vec2)**2).sum())4.再写个从dataset中根据dataset的长度随机选择下标的函数
# 根据当前dataset的长度随机选择一个下标
def getRandIndex(self):
return random.randint(0, len(self.dataset) - 1)5.核心算法
def clustering(self):
if self.t1 == 0:
print('Please set the threshold.')
else:
canopies = [] # 用于存放最终归类结果
while len(self.dataset) != 0:
rand_index = self.getRandIndex()
current_center = self.dataset[rand_index] # 随机获取一个中心点,定为P点
current_center_list = [] # 初始化P点的canopy类容器
delete_list = [] # 初始化P点的删除容器
self.dataset = np.delete(
self.dataset, rand_index, 0) # 删除随机选择的中心点P
for datum_j in range(len(self.dataset)):
datum = self.dataset[datum_j]
distance = self.euclideanDistance(
current_center, datum) # 计算选取的中心点P到每个点之间的距离
if distance < self.t1:
# 若距离小于t1,则将点归入P点的canopy类
current_center_list.append(datum)
if distance < self.t2:
delete_list.append(datum_j) # 若小于t2则归入删除容器
# 根据删除容器的下标,将元素从数据集中删除
self.dataset = np.delete(self.dataset, delete_list, 0)
canopies.append((current_center, current_center_list))
return canopies为了方便后面的数据可视化,我这里的canopies定义的是一个数组,当然也可以使用dict。
6.main()函数
def main():
t1 = 0.6
t2 = 0.4
gc = Canopy(dataset)
gc.setThreshold(t1, t2)
canopies = gc.clustering()
print('Get %s initial centers.' % len(canopies))
#showCanopy(canopies, dataset, t1, t2)Canopy聚类可视化代码
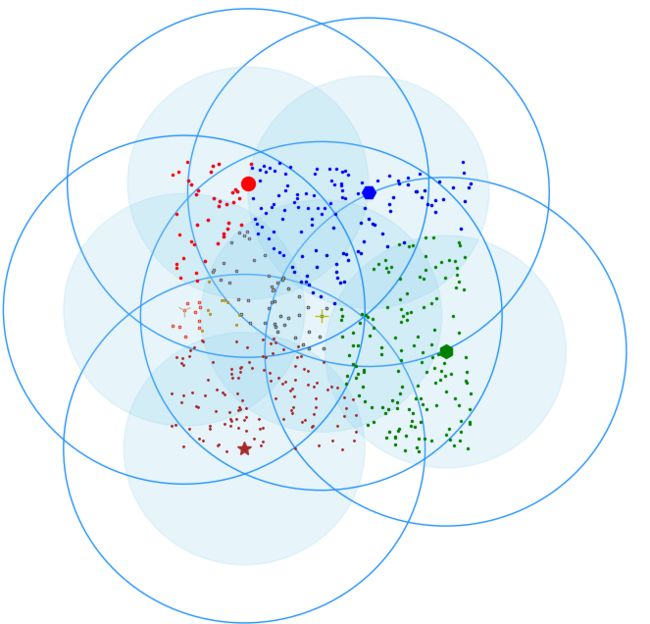
def showCanopy(canopies, dataset, t1, t2):
fig = plt.figure()
sc = fig.add_subplot(111)
colors = ['brown', 'green', 'blue', 'y', 'r', 'tan', 'dodgerblue', 'deeppink', 'orangered', 'peru', 'blue', 'y', 'r',
'gold', 'dimgray', 'darkorange', 'peru', 'blue', 'y', 'r', 'cyan', 'tan', 'orchid', 'peru', 'blue', 'y', 'r', 'sienna']
markers = ['*', 'h', 'H', '+', 'o', '1', '2', '3', ',', 'v', 'H', '+', '1', '2', '^',
'<', '>', '.', '4', 'H', '+', '1', '2', 's', 'p', 'x', 'D', 'd', '|', '_']
for i in range(len(canopies)):
canopy = canopies[i]
center = canopy[0]
components = canopy[1]
sc.plot(center[0], center[1], marker=markers[i],
color=colors[i], markersize=10)
t1_circle = plt.Circle(
xy=(center[0], center[1]), radius=t1, color='dodgerblue', fill=False)
t2_circle = plt.Circle(
xy=(center[0], center[1]), radius=t2, color='skyblue', alpha=0.2)
sc.add_artist(t1_circle)
sc.add_artist(t2_circle)
for component in components:
sc.plot(component[0], component[1],
marker=markers[i], color=colors[i], markersize=1.5)
maxvalue = np.amax(dataset)
minvalue = np.amin(dataset)
plt.xlim(minvalue - t1, maxvalue + t1)
plt.ylim(minvalue - t1, maxvalue + t1)
plt.show()
我把每个点都染上了其归属聚类中心点的颜色,还是挺漂亮的,这就是所谓的数据之美吧…
当然也有人问,t1和t2的初始值如何设定,后期的聚类中心点完全依赖这两个值的变化。t1和t2可以通过交叉验证的方式获得,具体怎么做,得视乎数据以及用户的需求,具体可以参考相关的论文。
Github链接
CanopyByPython