论文浅尝 | 融入知识的弱监督预训练语言模型
论文笔记整理:叶群,浙江大学计算机学院,知识图谱、NLP方向。
 会议:ICLR 2020
会议:ICLR 2020
链接:https://arxiv.org/pdf/1912.09637.pdf
Abstract
预训练语言模型不仅在传统的语言学任务上取得了很好的表现,在一些涉及到背景知识的任务上,也取得了一些提升。本文首先在zero-shot fact completion任务上探究了预训练语言模型捕获知识的能力,并提出了一种弱监督的训练目标,使模型学习到更多的背景知识。在新的预训练方式下,模型在fact completion任务上取得了显著的提升。下游任务表现中,在QA和entity typing两个任务上分别比BERT提升2.7和5.7个百分点。
Introduction
预训练语言模型例如ELMo, BERT和XLNet在大量的NLP任务上取得了新的SOTA。在大规模的自监督训练过程中,预训练模型学习到了句法和语义的信息。有趣的是,在一些需要背景知识和推理的任务上,预训练模型也取得了不错的效果。比如在WNLI,RECoRD和SWAG任务上,预训练模型都取得了SOTA,说明模型在预训练中也学习到了背景知识。本文首先在zero-shot fact completion任务上评估预训练模型捕获知识的能力,并提出了一种新的弱监督的训练目标。实验证明该训练目标下,模型可以捕获到更多的real-world knowledge。
Method
本文设计了一种弱监督训练目标,给定输入文本,首先将原始文本链接到维基百科的实体,然后将部分实体随机替换为同类型其他实体。训练时模型对文本中实体是否替换进行预测,损失函数为二元交叉熵损失函数,即
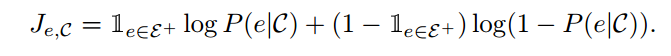
训练数据为所有的英文的维基百科文本,文本中的实体由anchor link标注好。除了对实体进行替换,训练目标还保留了BERT中mask language modeling目标,即对字符进行随机替换,但是替换的比例下降由15%降低为5%。模型架构上,选择了12层的BERT base。
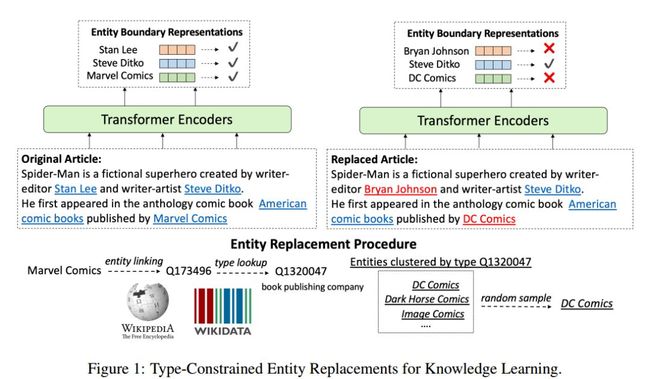
图1 实体替换策略
Experiments
1. Zero-shot fact completion
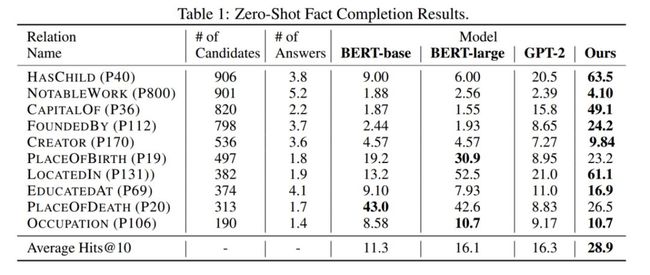
数据集来源于Wikidata,每条数据为一个三元组,例如{Paris, Capitalof, France}。去除尾实体,将三元组转换成query的形式,例如the capital of France is ? 并让模型对尾实体进行预测。评估指标采用Hits@10。这里的zero-shot指的是模型只有预训练过程,没有在具体任务上微调。
实验结果如表1所示,本文的模型在10个relation中的8个中达到了最佳。
表1 zero-shot fact completion实验结果
2. Question answering
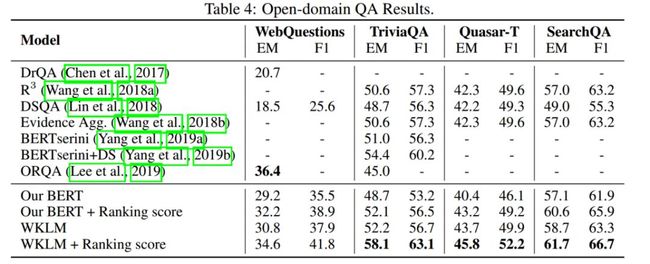
实验在以下4个数据集上进行:WebQuestions、Trivial QA、Quasar-T、SeachQA;对比的baseline有:DrQA、、DSQA、Evidence Aggregation、 BERTserini、OROA。训练过程即为对模型参数的微调。
实验结果如表2所示,本文的模型在大多数数据集上都比Baseline方法有所提升。
表2 QA实验结果
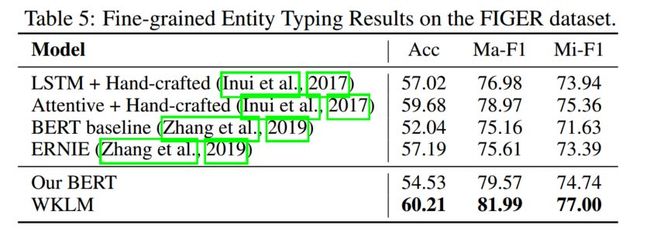
3. Entity typing
实验采用了FIGER数据集,对比了ERNIE模型、BERT、LSTM+Hand-craft、Attentative+Hand-craft。实验结果如表3所示,ERNIE作为同样融入知识的模型,比BERT提升了5.15%,而本文的模型在BERT的基础上提升了5.68%。
表3 Entity typing实验结果
Conclusion
本文提出了一种弱监督方法,使预训练模型学习到entity-level的知识。实验证明相比于传统的预训练模型,本文的模型可以从非结构化文本中更好地学习到entity-level的知识。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。