--序算法汇总--
文章目录
-
- 第三梯队
-
-
- 1.1 冒泡排序
- 1.2 选择排序
- 1.3 插入排序
- 1.4 鸡尾酒排序
-
- 第二梯队
-
-
- 2.1 希尔排序
- 2.2 快速排序
- 2.3 归并排序
- 2.4 堆排序
-
- 第一梯队
-
-
- 3.1 计数排序
- 3.2 基数排序
- 3.3 桶排序
-
第三梯队
1.1 冒泡排序
冒泡排序很形象,即让较大元素想泡泡一样不断往上冒,代码如下。
void bubblesort1(int *array,int n)
{
for(int i = 0;i<n;i++)
for(int j = 0;j<n-i-1;j++)
{
if(array[j]>array[j+1])
swap(array[j],array[j+1]);
}
}
优化一:如图,在进行两轮冒泡后,排序已经完成,所以不需要再进行下去,即当一个循环内无元素的交换,代表序列已经有序了,此时可以跳出,减少循环次数。
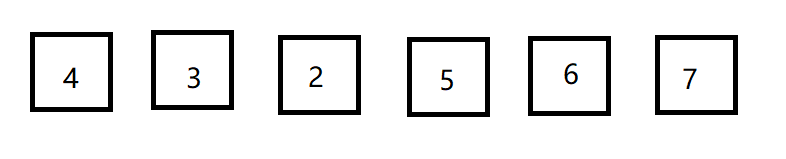
void bubblesort2(int *array, int n)//简单优化
{
for(int i = 0;i<n;i++)
{
bool flag = true;
for(int j = 0;j<n-i-1;j++)
{
if(array[j]>array[j+1])
swap(array[j],array[j+1]);
flag = false;
}
if(flag)
break;
}
}
优化二:同上,每次直接记录最后交换元素的位置,其往后的元素已经有序,故下一次循环只需要比较到此位置即可。
void bubblesort3(int *array,int n)
{
int lastchange = 0;
int sortborder = n-1;
for(int i = 0;i<n;i++)
{
bool flag = true;
for(int j = 0;j<sortborder;j++)
{
if(array[j]>array[j+1])
{
swap(array[j],array[j+1]);
flag = false;
lastchange = j;
}
}
sortborder = lastchange;
if(flag)
break;
}
}
1.2 选择排序
顾名思义,选择排序即每次选择范围内最小的元素,把其放到最前的位置。选择排序和冒泡排序的不同在于,前者没有进行频繁的元素交换,而是在范围内遍历完后,再进行替换。
void choisesort(int *list,int n)
{
for(int i = 0;i<n;i++)
{
bool flag = true;
int m = i;
for(int j = i+1;j<n;j++)
{
if(list[j]<=list[m])
{
m = j;
flag = false;
}
}
if(flag)
break;
swap(list[i],list[m]);
}
}
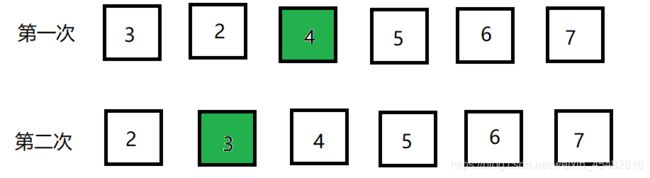
选择排序被称为不稳定的排序,因为对于相同的元素,通过选择排序过后,可能会改变相同元素间的想对位置。如下图,这是选择排序的一个缺陷。
1.3 插入排序
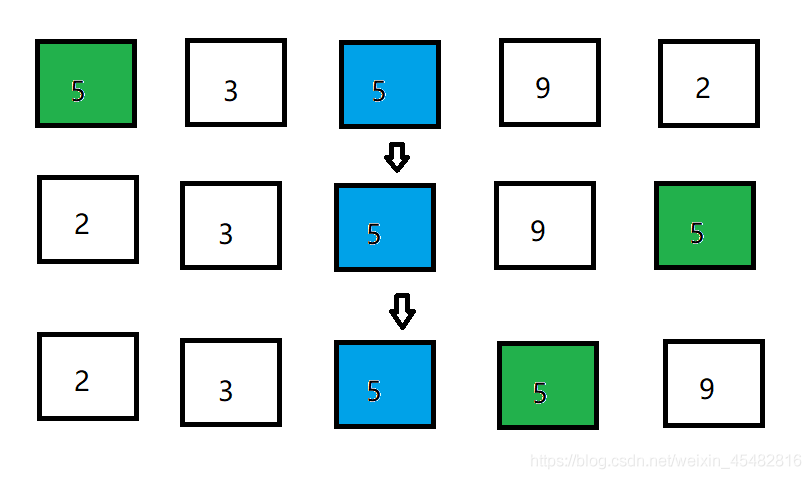
插入排序,即假设前面的序列有序,然后用后面的元素不断与前面的有序序列比较,直到其能“插入”到一个合适的地方,即元素需要不断往后退,腾出空间给元素插入。
void insertsort(int *list,int n)
{
int tmp,i,j;
for(i = 1;i<n;i++)
{
tmp = list[i];
for(j = i-1;j>=0&&list[j]>tmp;j--)
list[j+1] = list[j];
list[j+1] = tmp;
}
}
1.4 鸡尾酒排序
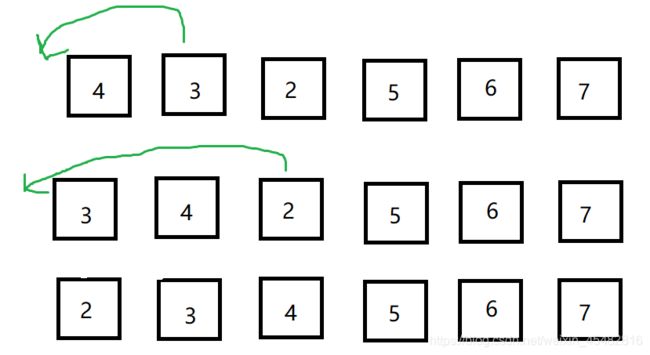
鸡尾酒排序是冒泡排序的一种变式,适用于大部分有序序列的排序,如下图
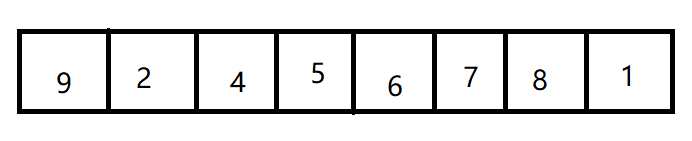
如果使用冒泡排序,那么整个过程是这样的
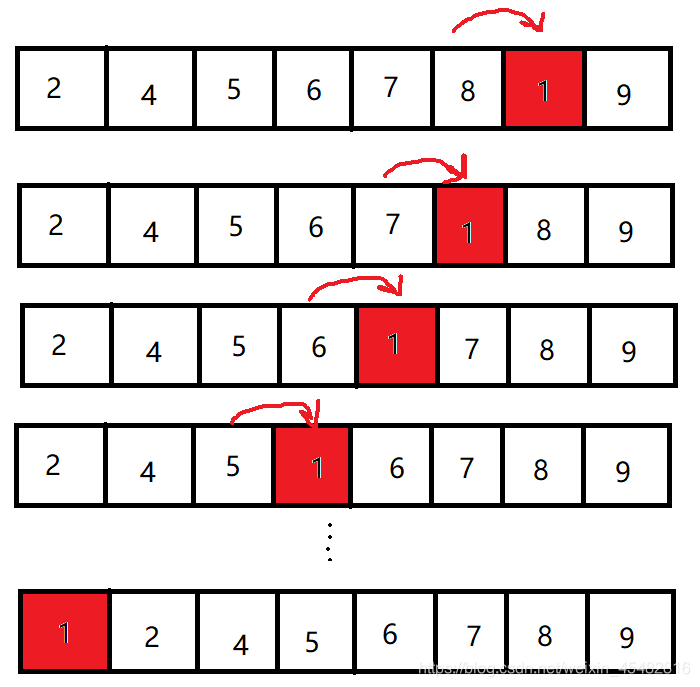
这时我们就会发现,原本1和9中间的元素是有序的,只需要1和9变化即可完成,可是使用冒泡排序却要进行如此多次变化。
这时候鸡尾酒排序就有发挥的作用了,很容易想到,当9排到最后时,只需要对1进行往前的冒泡排序,就可以在一个循环内完成排序了。
即像一个钟摆那样,来回方向进行冒泡排序。
优化方式同前面的冒泡。
void cocktailsort(int *array,int n){
for(int i = 0;i<n/2;i++){
for(int j = i;j<n-1-i;j++){
if(array[j]>array[j+1])
swap(array[j],array[j+1]);
}
for(int j = n-2-i;j>i;j--){
if(array[j]<array[j-1])
swap(array[j],array[j-1]);
}
}
}
第一梯队的排序方法的平均时间复杂度均为O(n^2),空间复杂度O(1)。
上述各种算法没有说哪种最优,只是不同的算法使用与不同的情况。
(1)如插入排序和冒泡排序,两种排序都通过对元素频繁的交换来进行排序,交换的次数,即排序方法的性能取决于序列的有序程度。
插入排序的元素交换是连续的,而冒泡是两两相关,彼此独立的。显然,插入排序可以省去很多无用的比较,基于这个因素,插入排序的性能略高于冒泡排序。
(2)我们再来看选择排序,选择排序与上述两种方法有些不同,选择排序的比较次数是确定的,每次都选取范围内最小元素排到前面,至于序列的有序程度如何,对选择排序的比较次数是无影响的。
所以,对于大部分有序的序列,插入排序优;对于大部分无序的序列,选择排序优。
冒泡和插入是稳定算法,因为值相同的元素排序前后相对位置不会改变。而选择排序可能会改变相同元素的相对位置,所以选择排序不是稳定的排序。
第二梯队
2.1 希尔排序
希尔排序其实就是一种分组的插入排序。回想一下如何去优化插入排序的性能,或者什么样的序列用插入排序会更为高效。
1)更短的序列
2)更为有序的序列
如果满足以上的特点,那么将会大大减低插入排序的工作量。而希尔排序就是利用这两点,利用增量(即分组的跨度)来讲序列分成多个小组,组内进行插入排序。
至于增量的选取则有很多,例如Hibbard增量和Sedgewick增量,这里不讨论。
void hellsort(int *list,int n)//n为增量
{
int d = n;
while(d>1)
{
d = d/2;
for(int i = 0;i<d;i++){
for(int j = i+d;j<n;j = j+d)
{
int tmp = list[j];
int y;
for(y = j-1;y>=0&&list[y]>tmp;y--)
list[y+1] = list[y];
list[y+1] = tmp;
}
}
}
}
2.2 快速排序
快速排序运用一种分治的思想,即选择一个数,排序完成后,该数左边的数都小于该数,该数右边的数都大于该数。然后再分为两个子数组继续递归下去。流程大致如下。
首先定义两个指针left,right,以序列第一个数作为划分序列的边界,从右边向左找到第一个比其小的数,将该值覆盖到L的位置。
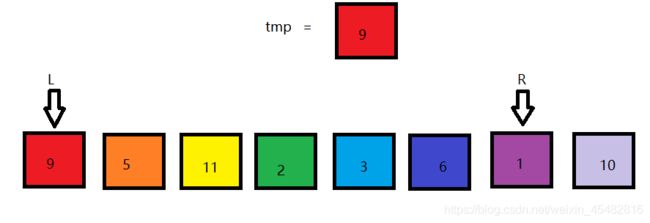

然后从L开始,从左往右遍历,找到第一个比9大的数。覆盖掉R所指元素。
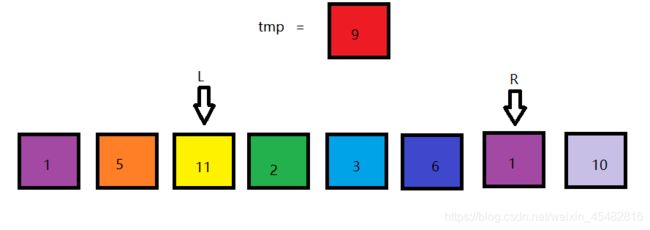
重复上述步骤,最后循环跳出,得以下结果。
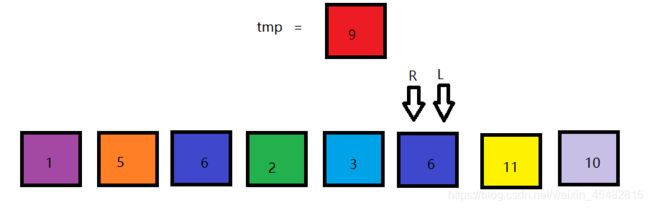
最后将tmp覆盖掉该位置,可看到9左边的元素都小于9,9右边的元素都大于9。
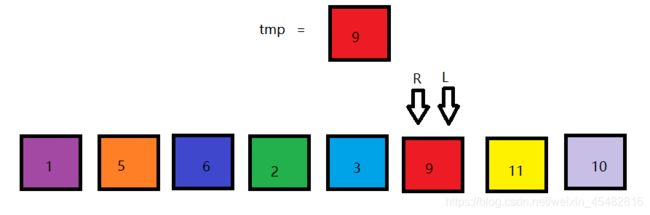
此时序列还没有完成排序,需要以9为界,把序列分成左右子部分,重复上述操作。

int fast_sort(int *list,int left,int right)
{
int tmp = list[left];
while(left<right)
{
while(list[right]>=tmp&&left<right)
right--;
list[left] = list[right];
while(list[left]<=tmp&&left<right)
left++;
list[right] = list[left];
}
list[left] = tmp;
return left;
}
void fastsort(int *list,int left,int right)
{
if(list==NULL||left>right)
return ;
int tmp = fast_sort(list,left,right);
fastsort(list,left,tmp-1);
fastsort(list,tmp+1,right);
}
2.3 归并排序
归并排序,即先拆后并,不断两两分组,把序列拆分成小序列,内部排序后再依次合并继续排序。
流程大致如下,取中间为界不断将序列分割。

分割后再每小组进行排序,一层一层地排下去。

整个流程其实很明了,层数logn层,每层都共有n个元素需要排序,所以时间复杂度为O(nlogn),而空间复杂度为O(n),因为每次拆分排序后,每一层的临时数组都是n,一层过后临时数组都会被释放,所以不需要叠加计算。
void func(int *list,int *tmp,int start,int end)
{
if(start>=end)
return ;
int mid = (start+end)/2;
int start2 = mid+1;
int start1 = start;
int end1 = mid;
int end2 = end;
func(list,tmp,start1,end1);
func(list,tmp,start2,end2);
int k = start;
while(start1<=end1 && start2<=end2)
{
tmp[k++] = list[start1]>list[start2]?list[start2++]:list[start1++];
}
while(start1<=end1)
tmp[k++] = list[start1++];
while(start2<=end2)
tmp[k++] = list[start2++];
for(int i = start;i<=end;i++)
list[i] = tmp[i];
}
void merge(int *list,int n)
{
int tmp[n];
func(list,tmp,0,n-1);
}
2.4 堆排序
堆排序利用了二叉堆这一个数据结构,二叉堆分为两种,有大顶堆和小顶堆。其利用了完全二叉树的特性,以数组作为底层结构,父节点下标为i,则其左节点为2i+1,右节点为2i-1。子节点的父节点为(i-1)/ 2。
在STL中,堆heap有两种基本操作,即上溯和下溯。在堆尾部插入元素,通过上溯使堆更新。下溯即把堆顶往下比较,sort_heap和make_heap都利用了下溯。
堆排序流程:
(1)先把序列构造成大顶堆
(2)然后将非叶子节点进行下溯操作
void _pop_heap(int *array,int parent,int len){
int tmp = array[parent];
int child = parent*2+1;
while(child<len){
if(child+1<len&&array[child]<array[child+1])
child++;
if(array[child]<=tmp)
break;
array[parent] = array[child];
parent = child;
child = parent*2+1;
}
array[parent] = tmp;
}
void _make_heap(int *array,int len){
for(int i = (len-2)/2;i>=0;i--){
_pop_heap(array,i,len);
}
}
void _sort_heap(int *array,int len){
_make_heap(array,len);
for(int i = 0;i<len;i++){
swap(array[0],array[len-1-i]);
_pop_heap(array,0,len-i-1);
}
}
构造堆需要进行n/2次下溯,排序时需要n次下溯,每次下溯logn,故综合起来时间复杂度为O(nlogn),无需额外空间,空间复杂度为O(1)。
第二梯队算法的平均时间复杂度均为O(nlogn),其中希尔排序最快可达O(n^1.3)。
快排最坏情况下复杂度会退化至O(n^2),例如序列 [9,1,2,3,4,5,6,7],需要n次分组。
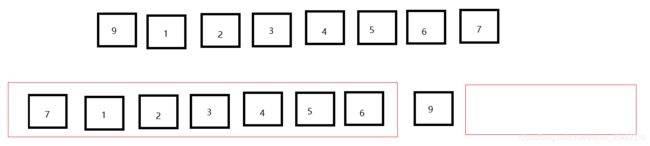
而堆排序相对于归并和快排性能又略低一些,因为二叉堆中父子节点并非是在连续空间上,对于底层的缓存机制来说,不命中率会高一些。
所以堆排序和快速排序都不是稳定的,而归并排序是稳定的,因为无论序列如何,也不会影响其排序的步骤。
不过归并排序需要额外O(n)的空间,而快排和堆排序都为原地算法。
第一梯队
3.1 计数排序
计数排序很好理解,即额外开拓标记数组记录每个数出现的次数,然后再按次序依次排列出来。比如一个序列只有4种数,[1,2,3,4,2,3,1,2,3,2],通过遍历数组可知1出现了两次,2出现了四次,3出现了三次,4出现了一次。
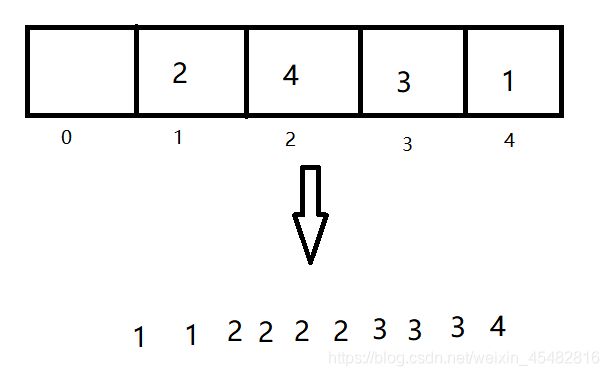
以这种方式(数组大小为序列最大值)开辟数组很容易发现一个问题,如以下序列[90,91,92,97,99,98],若以最大值开辟数组,那么中间大部分的空间都会被浪费。
因此采用一种优化的方法,取最大最小值之差加1来开辟数组,然后元素减去最小值所得的值作为下标。

就目前看来,计数排序算不上是一种排序,它只是记录数据出现次数,然后按序重构序列,对于相同数的相对位置等信息,单纯的计数排序无法保存。下面将介绍如何改良。
如要对下图跳远成绩进行排序。
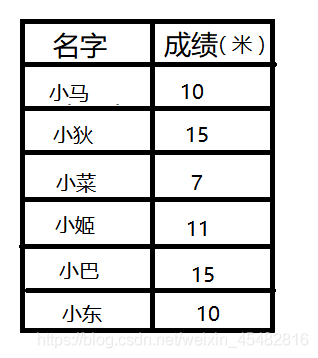
按上述方法先申请标记数组(15-7+1)

在这里要进行特殊处理,即数组元素的值应为前面元素及自身的累加,如下图。
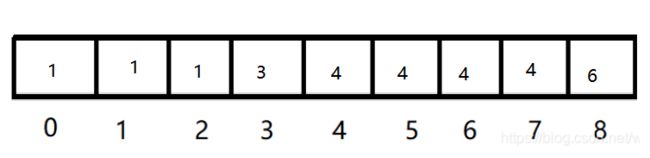
这样做的目的,其实记录出元素在最终结果数组中出现的位置。此时我们再从后往前遍历序列,将上述数组对应下标元素的值减1,即为其在最终结果数组中的位置。执行完后,要在数组相应位置减1。
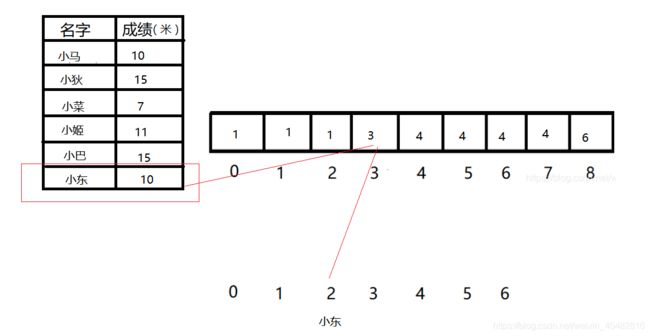
void sort(int* array,int n,int *res){
int max = array[0];
int min = array[0];
for(int i = 1;i<n;i++){
//取最大最小值
max = max(array[i],max);
min = min(array[i],min);
}
int d = max-min+1;
int arr[d] = {
0};
for(int i = 0;i<n;i++)//先正常标记
arr[array[i]-min]++;
for(int i = 1;i<n;i++)//特殊处理数组
arr[i] += arr[i-1];
for(int i = n-1;i>=0;i--){
//插入元素
res[arr[array[i]-min]-1] = array[i];
arr[array[i]-min]--;
}
}
算法时间复杂度很好分析,为O(m+n)其中m为最大值和最小值之差。空间复杂度O(m)
计数排序缺点明显,显示中接触不多,对于排序序列非整数,最大最小值差距较大时,计数排序就没什么使用的必要了。
3.2 基数排序
基数排序是基于计数排序的一种排序,即如果需要对一系列字符串进行排序,只需要由低位到高位开始依次对每一位元素进行计数排序。
3.3 桶排序
桶排序大致是按序列元素情况,申请一定数量的桶,所谓桶,即大小在该区间内的数都会被放到该桶里面,在每个桶里面再各自做排序,最后有序将桶内元素倒出来即可。
以上三种算法均属于线性时间复杂度的排序算法,均稳定。其中
计数排序的时间复杂度是O(n+m)。
桶排序的时间复杂度是O(n),这是在分桶数量是n的前提下。
基数排序的时间复杂度是O(k(n+m)),其中k是元素的最大位数。
参考文章
