Linux内核之 内核同步
一、同步介绍
1、临界区与竞争条件
所谓 临界区 ( critical regions )就是访问和操作共享数据的代码段。为了避免在临界区中并发访问,编程者必须保证这些代码原子地执行——也就是说,代码在执行结束前不可被打断,就如同整个临界区是一个不可分割的指令一样。如果两个执行线程有可能处于同一个临界区中同时执行,那么就是程序包含一个 bug ,如果这种情况发生了,我们就称之为 竞争条件 ( race conditions,简称竞态 ), 避免并发和防止竞争条件被称为同步(synchronization) 。
在 linux 中,主要的竞态发生在如下几种情况:
(1)对称多处理器(SMP) 多个CPU
特点是多个CPU使用共同的系统总线,因此可访问共同的外设和存储器。
(2)单CPU内 进程与抢占它的进程
(3) 中断 (硬中断、软中断、Tasklet、中断下半部)与进程之间
只要并发的多个执行单元存在对共享资源的访问,竞态就有可能发生。
如果中断处理程序访问进程正在访问的资源,则竞态也会发生。
多个中断之间本身也可能引起并发而导致竞态(中断被更高优先级的中断打断)。
2、死锁
死锁的产生需要一定条件:要有一个或多个执行线程和一个或多个资源,每个线程都在等待其中的一个资源,但所有的资源都已经被占用了, 所有线程都在相互等待 ,但它们永远不会释放已经占有的资源,于是任何线程都无法继续,这便意味着死锁的发生。
最简单的死锁例子是 自死锁 :
- 获得锁
- 再次试图获得锁
- 等待锁重新利用
- …
这种情况属于一个线程一把锁,自己等自己,一般是一个函数等另一个函数,从广义上说就是一种嵌套使用。我曾经的经验总结《 踩坑经验总结(四):死锁 》就属于这种情况。
最常见的死锁例子是 ABBA锁 :
- 线程1
- 获得锁A
- 试图获得锁B
- 等待锁B
- …
- 线程2
- 获得锁B
- 试图获得锁A
- 等待锁A
- …
这种问题确实很常见。
3、加锁规则
预防死锁非常重要,那该注意些什么呢?
(1) 按顺序加锁 。使用嵌套锁是必须保证以正确的顺序获取锁,这样可以阻止致命的 拥抱类 死锁,即ABBA锁。最好能记录下锁的顺序,后续都按此顺序使用。
(2) 防止发生饥饿 。特别是在一些大循环中,尽量将锁移入内部,否则外面等太久。如果发生死循环,就会出现饥饿。
(3) 不要重复请求同一把锁 。这是针对自死锁的情况,但是一旦出现这种情况,往往不明显,即不是很明显的嵌套,转了几个弯弯,就叫曲线嵌套吧。
(4) 设计应力求简单 。越复杂的加锁方案越有可能造成死锁。
这里的每一项都很重要,对于应用程序同样适合。再重点说下设计。
在最开始设计代码的时候,就应该考虑加锁;越往后考虑,付出代价越大,效果反而越不理想。那么设计阶段加锁时一定要考虑,为什么要加锁,为了保护什么数据?我认为这是一个定位的问题。 需求阶段对一个产品的定位,设计阶段对数据的定位,决定了后续一系列的动作比如采用的方案、采用的算法、采用的结构体…开始经验之谈了:)。
那么到底该如何加锁, 记住:要给数据而不是给代码加锁 。我认为这是一个 黄金规则 ,在《死锁》也这么强调过。
4、争用与扩展性
锁的争用(lock contention) ,简称争用,是指当锁正在被占用时,有其他线程试图获得该锁。
说一个锁处于高度争用状态,就是指有多个其他线程在等待获得该锁。
由于锁的作用是使程序以 串行方式对资源进行访问 ,所以使用锁无疑会降低系统的性能。 被高度争用 (频繁被持有,或者长时间持有——两者都有就更糟糕)的锁 会成为系统的瓶颈,严重降低系统性能 。
扩展性(scalability) 是对系统可扩展程度的一个量度。
对于操作系统,我们在谈及可扩展性时就会和大量进程、大量处理器或是大量内存等联系起来。其实任何可以被计量的计算机组件都可以涉及可扩展性。 理想情况下,处理器的数量加倍应该会使系统处理性能翻倍。而实际上, 这是不可能达到的。
自从2.0版内核引入多处理支持后,Linux对集群处理器的可扩展性大大提高了。在Linux刚加入对多处理器支持的时候,一个时刻只能有一个任务在内核中执行; 在2.2版本中,当 加锁机制发展到细粒度加锁 后,便取消了这种限制,而在2.4和后续版本中, 内核加锁的粒度变得越来越精细 。如今,在Linux 2.6版内核中, 内核加的锁是非常细的粒度,可扩展性也很好 .
加锁粒度用来描述加锁保护的数据规模。
一个过粗的锁保护大块数据——比如,一个子系统用到的所有的数据结构:相反,一个过于精细的锁保护很小的一块数据——比如,一个大数据结构中的一个元素。在实际使用中,绝大多数锁的加锁范围都处于上述两种极端之间,保护的既不是一个完整的子系统也不是一个独立元素,而可能是一个单独的数据结构。 许多锁的设计在开始阶段都很粗,但是当锁的争用问题变得严重时,设计就向更加精细的加锁方向进化 。
在前面讨论过的运行队列,就是一个锁从粗到精细化的实例。
在2.4版和更早的内核中,调度程序有一个单独的调度队列(回忆一下,调度队列是一个由可调度进程组成的链表),在2.6版内核系列的早期版本中,O(1)调度程序为每个处理器单独配备一个运行队列,每个队列拥有自己的锁,于是 加锁由一个全局锁精化到了每个处理器拥有各自的锁 。这是一种重要的优化,因为运行队列锁在大型机器上被争着用,本质上就是要在调度程序中每次都把整个调度进程下放到单个处理器上执行。在2.6版内核系列的版本中, CFS调度器进一步提升了锁的可扩展性 。
一般来说,提高可扩展性是件好事,因为它可以提高Linux在更大型的、处理能力更强大的系统上的性能。
但是 一味地“提高”可扩展性,却会导Linux在小型SMP和UP机器上的性能降低,这是因为 小型机器 可能用不到特别精细的锁, 锁得过细只会增加复杂度,并加大开销 。
考虑一个链表,最初的加锁方案可能就是用一个锁来保护链表 ,后来发现,在拥有集群处理器机器上,当各个处理器需要频繁访问该链表的时候,只用单独一个锁却成了扩展性的瓶颈。为解决这个瓶颈,我们将原来加锁的整个链表变成为链表中的 每一个结点都加入自己的锁 ,这样一来, 如果要对结点进行读写,必须先得到这个结点对应的锁。将加锁粒度变细后,多处理器访问同一 个结点时,只会争用一个锁。可是这时锁的争用仍然没有完全避免,那么,能不能为每个结点中的每个元素都提供一个锁呢?(答案是:不能)严格地讲,即使这么细的锁可以在大规模SMP机器上执行得很好,但它在双处理器机器上的表现又会怎样呢?如果在双处理器机器锁争用表现 得并不明显,那么多余的锁会加大系统开销,造成很大的浪费。
不管怎么说, 可扩展性都是很重要的,需要慎重考虑 。关键在于,在设计锁的开始阶段就应该考虑到要保证良好的扩展性。 因为即使在小型机器上,如果对重要资源锁得太粗,也很容易造成系统性能瓶颈。锁加得过粗或过细,差别往往只在一线之间。 当锁争用严重时,加锁太粗会降低可扩展性;而锁争用不明显时,加锁过细会加大系统开销,带来浪费,这两种情况都会造成系统性能下降。 但要记住: 设计初期加锁方案应该力求简单 ,仅当需要时再 进一步细化 加锁方案。 精髓在于力求简单 。
上面这大段话来自书上,分析的很好,介绍了锁的粒度过粗和过细的危害,同时也介绍了内核加锁的一个变化和演进。总之,对于我们设计软件都有参考意义。也是理解内核后面为什么出现了多种同步方法的原因。
需要C/C++ Linux服务器架构师学习资料加qun(563998835)获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
二、同步方法
1、原子操作
原子操作是其他同步方法的基石。 原子操作 可以保证指令以原子的方式执行—— 执行过程不可中断 。在数据库事务中这也是基本的要求。
linux内核提供了 两组原子操作接口 :一组对整数进行操作,一组针对单独的位进行操作。
原子整数操作
针对整数的原子操作只能对 atomic_t类型 的数据进行处理,在这里之所以引入了一个特殊的数据类型,而没有直接使用C语言的int型,主要是出于两个原因:
第一、让原子函数只接受atomic_t类型的操作数,可以确保原子操作只与这种特殊类型数据一起使用,同时,这也确保了该类型的数据不会被传递给其它任何非原子函数;
第二、使用atomic_t类型确保 编译器 不 对相应的值进行访问 优化 ——这点使得原子操作最终接收到正确的内存地址,而不是一个别名,最后就是在不同体系结构上实现原子操作的时候,使用atomic_t可以屏蔽其间的差异。
atomic_t类型定义 在文件
-
typedef struct { -
volatile int counter; -
}atomic_t;
- 1
- 2
- 3
原子整数操作 最常见的用途 就是 实现计数器 。
另一点需要说明原子操作只能保证操作是原子的,要么完成,要么不完成,不会有操作一半的可能, 但原子操作并不能保证操作的顺序性 ,即它不能保证两个操作是按某个顺序完成的。如果要保证原子操作的顺序性,请使用 内存屏障 指令。
原子操作与更复杂的同步方法相比较,给系统带来的开销小,对高速缓存行的影响也小。
原子位操作
针对位这一级数据进行操作的函数,是对 普通的内存地址 进行操作的。它的参数是一个指针和一个位号。
2、自旋锁
Linux内核中 最常见 的锁是自旋锁( spin lock) 。自旋锁最多 只能被一个可执行线程持有 。如果一个执行线程试图获得一个被 争用 (已经被持有)的自旋锁,那么该线程就会 一直进行忙循环 —旋转 —等待锁重新可用 。要是锁未被争用,请求锁的执行线程便能立刻得到它,继续执行。在任意时间,自旋锁都可以防止多于一个的执行线程同时进入临界区。同一个锁可以用在多个位置 —例如,对于给定数据的所有访问都可以得到保护和同步。
一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋(特别浪费处理器时间),即 忙等待 ,这是 自旋锁的要点 。所以自旋锁不应该被长时间持有。 事实上,这点正是使用自旋锁的初衷,在 短期间内进行轻量级加锁 。
自旋锁的实现和体系密切相关,代码往往通过汇编实现。实际用到的接口定义在文件中。自旋锁的基本使用形式如下:
-
DEFINE SPINLOCK(mr_lock); -
spin_lock(&mr_lock); -
/*临界区....*/ -
spin_unlock(&mr_lock);
- 1
- 2
- 3
- 4
- 5
自旋锁可以 使用在中断处理程序中 (此处不能使用信号量,因为它们会导致睡眠),在中断处理程序中使用自旋锁时,一定要在获取锁之前,首先禁止本地中断(在当前处理器上的中断请求)。注意,需要 关闭的只是当前处理器上的中断 ,如果中断发生在不同的处理器上,即使中断处理程序在同一锁上自旋,也不会妨碍锁的持有者(在不同处理器上)最终释放锁。
3、读写自旋锁
有时,锁的用途可以明确的分为读取和写入两个场景。那么读写可以分开处理,读时可以共享数据,写时进行互斥。为此,Linux内核提供了专门的读写自旋锁。
这种读写自旋锁为读和写分别提供了不同的锁,所以它具有 以下特点:
读锁之间是共享的,即一个线程持有了读锁之后,其他线程也可以以读的方式持有这个锁。
写锁之间是互斥的,即一个线程持有了写锁之后,其他线程不能以读或者写的方式持有这个锁。
读写锁之间是互斥的,即一个线程持有了读锁之后,其他线程不能以写的方式持有这个锁,写锁必须等待读锁的释放。
读写自旋锁的使用用法类似于普通的自旋锁:
-
DEFINE_RWLOCK(mr_rwlock); -
read_lock(&mr_rwlock); -
/*critical region, only for read*/ -
read_unlock(&mr_rwlock); -
write_lock(&mr_lock); -
/*critical region, only for write*/ -
write_unlock(&mr_lock);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意:如果写和读不能清晰地进行分离,那么使用一般的自旋锁就够了,不需要使用读写自旋锁。
4、信号量
信号量也是一种锁,和自旋锁不同的是,线程获取不到信号量的时候, 不会像自旋锁一样循环去试图获取锁,而是进入睡眠 ,直至有信号量释放出来时,才会唤醒睡眠的线程,进入临界区执行。
由于使用信号量时,线程会睡眠,所以等待的过程不会占用 CPU 时间。所以信号量 适用于 等待时间较长 的临界区 。
信号量 消耗CPU 时间的地方在于 使线程睡眠和唤醒线程 --两次明显的上下文切换。
如果(使线程睡眠 + 唤醒线程)的 CPU 时间 > 线程自旋等待 CPU 时间,那么可以考虑使用自旋锁。
信号量有二值信号量和计数信号量两种,其中 二值信号量比较常用 。
二值信号量表示信号量只有2个值,即0和1。信号量为1时,表示临界区可用,信号量为0时,表示临界区不可访问。所以也可以称为互斥信号量。
计数信号量有个计数值,比如计数值为5,表示同时可以有5个线程访问临界区。所以 二值信号量就是计数等于1的计数信号量。
5、读写信号量
读写信号量和信号量的关系与读写自旋锁和自旋锁的关系差不多。
读写信号量都是二值信号量,即计数值最大为1,增加读者时,计数器不变,增加写者,计数器才减一。
也就是说读写信号量保护的临界区, 最多只有一个写者,但可以有多个读者 。
6、互斥
互斥体(mutex) 也是一种可以 睡眠 的锁,相当于二值信号量,只是提供的API更加简单, 使用的 场景 也更 严格 一些 ,如下所示:
mutex的 计数值只能为1 ,也就是最多只允许一个线程访问临界区
在 同一个上下文中 上锁和解锁
不能递归的上锁和解锁
持有个mutex时, 进程不能退出
mutex不能在中断或者下半部中使用,也就是mutex只能在 进程上下文 中使用
mutex 只能通过官方API来管理 ,不能自己写代码操作它
在面对互斥体 和 信号量的选择 时,只要满足互斥体的使用场景就 尽量优先使用互斥体 。
在面对互斥体 和 自旋锁的选择 时,参见下表: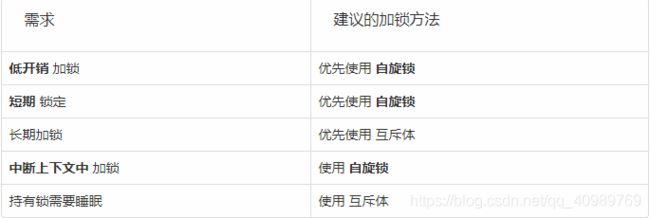
7、完成变量
完成变量的机制类似于信号量,比如一个线程A进入临界区之后,另一个线程B会在完成变量上等待,线程A完成了任务出了临界区之后,使用完成变量来唤醒线程B。
一般在2个任务需要简单同步的情况下,可以考虑使用完成变量。
8、大内核锁
大内核锁已经不再使用,只存在与一些遗留的代码中。
9、 顺序锁
顺序锁为读写共享数据提供了一种简单的实现机制。 之前提到的读写自旋锁和读写信号量,在读锁被获取之后,写锁是不能再被获取的, 也就是说,必须等所有的读锁释放后,才能对临界区进行写入操作。
顺序锁则与之不同,读锁被获取的情况下,写锁仍然可以被获取。 使用顺序锁的读操作在读之前和读之后都会检查顺序锁的序列值,如果前后值不符,则说明在读的过程中有写的操作发生, 那么读操作会重新执行一次,直至读前后的序列值是一样的。
顺序锁优先保证写锁的可用,所以适用于那些读者很多,写者很少,且写优于读的场景。
10、禁止抢占
其实使用自旋锁已经可以防止内核抢占了,但是有时候仅仅需要禁止内核抢占,不需要像自旋锁那样连中断都屏蔽掉。
这时候就需要使用禁止内核抢占的方法了: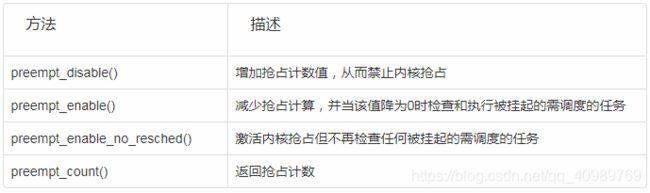
这里的preempt_disable()和preempt_enable()是可以嵌套调用的,disable和enable的次数最终应该是一样的。
11、顺序和屏障
对于一段代码,编译器或者处理器在编译和执行时可能会对执行顺序进行一些优化,从而使得代码的执行顺序和我们写的代码有些区别。
一般情况下,这没有什么问题,但是在并发条件下,可能会出现取得的值与预期不一致的情况。
在某些并发情况下,为了保证代码的执行顺序,引入了一系列屏障方法来阻止编译器和处理器的优化。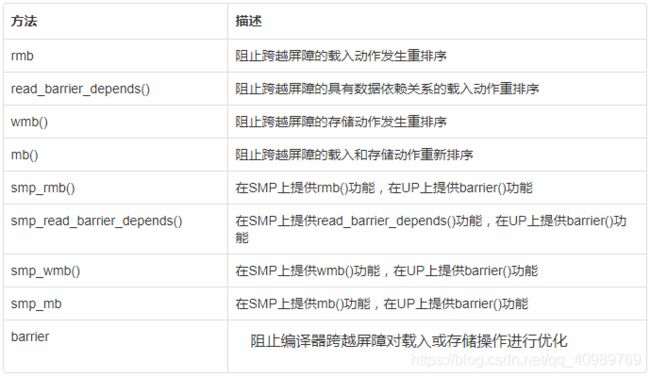
举例如下:
-
void thread_worker() -
{ -
a = 3; -
mb(); -
b = 4; -
}
- 1
- 2
- 3
- 4
- 5
- 6
上述用法就会保证 a 的赋值永远在 b 赋值之前,而不会被编译器优化弄反。在某些情况下,弄反了可能带来难以估量的后果。
12、总结
本节讨论了大约11种内核同步方法,除了大内核锁已经不再推荐使用之外,其他各种锁都有其适用的场景。
了解了各种同步方法的适用场景,才能正确的使用它们,使我们的代码在安全的保障下达到最优的性能。
同步的目的就是为了保障数据的安全,其实就是保障各个线程之间共享资源的安全,下面根据共享资源的情况来讨论一下10种同步方法的选择。
10种同步方法在图中分别用蓝色框标出。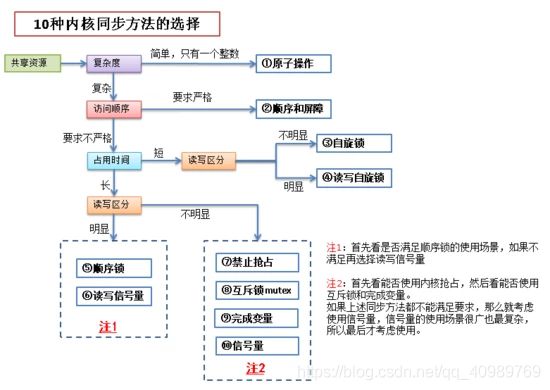
最后,在此图基础上再做个总结。