机器学习——聚类——距离聚类法——K-means
目录
-
-
- 理论部分
-
- 1.1 聚类概念
-
- 1.1.1 定义
- 1.1.2 与分类的区别
- 1.2 相似度测量
-
- 1.2.1 欧式距离
- 1.2.2 马氏距离
- 1.3 聚类准则
-
- 1.3.1 试探方法
- 1.3.2 聚类准则法
- 1.4 常见聚类方法
- 1.5 K均值聚类
-
- 1.5.1 K均值聚类思想
- 1.5.2 K均值聚类流程
- 1.5.3 实例
- 1.5.4 K均值聚类优点
- 1.5.5 K均值聚类缺点
- 1.6 评估指标
- 1.7 K的选取与肘部法则
- 代码部分
-
- 2.1 K均值代码实现
- 2.2 评估指标代码实现
- 2.3 整体实现
-
理论部分
1.1 聚类概念
1.1.1 定义
定义: 对一批没有标出类别的模式样本集,按照样本之间的相似程度分类,相似的归为一类,不相似的归为另一类,这种分类称为聚类,也称为无监督分类。
一个通俗的例子如下:

如上图,现在有若干个样本点,事前我们并不知道每个样本所属的类别(也即不知道各样本的标签),但我们仍希望将这些样本按照某种指标进行相似度划分,将相似的归为一类,不相似的归为另一类,对于未知标签样本点的类别划分过程就称为聚类。
1.1.2 与分类的区别
注意聚类并不等于分类,分类问题中样本标签事前已知,而聚类问题中样本标签事前并不清楚。分类问题属于监督学习,聚类问题属于无监督学习。
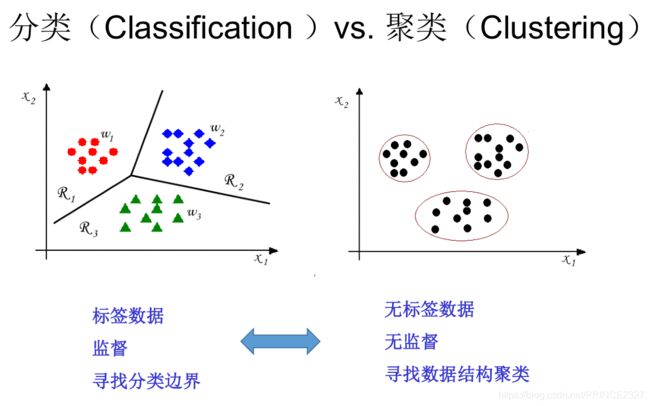
如上图所示。
1.2 相似度测量
前面我们提到了聚类是根据样本间的相似性测度进行划分的,那么这里的相似性一般是以样本点间的距离来衡量的。具体来说:把整个模式样本集的特征向量看成是分布在特征空间中的一些点,点与点之间的距离即可作为模式相似性的测量依据。
通俗的解释如下:
现有两位学生A和B,希望根据他们的身高和体重进行相似度聚类。假设A的身高和体重分别为1.7m,70kg。B的身高和体重分别为1.8m,80kg。那么A和B这两个样本就称为模式, A = [ 1.7 , 70 ] T A=[1.7,70]^{T} A=[1.7,70]T与 B = [ 1.8 , 80 ] T B=[1.8,80]^{T} B=[1.8,80]T分别称为样本A与样本B的特征向量,特征向量所处的二维空间就称为特征空间。衡量样本间的相似性就是通过衡量样本对应特征向量间的距离来决定的。
下面介绍几种常见的距离
1.2.1 欧式距离
定义:欧式距离又称欧几里得距离,是最常用的距离测度。假设两个样本 x , y x,y x,y的特征向量分别为 x = [ x 1 , x 2 , ⋯ , x n ] T x=[x_{1},x_{2},\cdots,x_{n}]^{T} x=[x1,x2,⋯,xn]T, y = [ y 1 , y 2 , ⋯ , y n ] T y=[y_{1},y_{2},\cdots,y_{n}]^{T} y=[y1,y2,⋯,yn]T。则它们的欧式距离定义如下:

欧式距离就是我们常说的两点间距离。
计算样本间欧式距离时要注意不同样本间的相同特征应该保持一致的物理量纲。例如上述例子,当身高以米为单位时,所有样本的身高都应该转换为以米为单位进行衡量。
1.2.2 马氏距离
马氏距离计算公式如下:
d = ( x − y ) T Σ − 1 ( x − y ) d=\sqrt{(x-y)^{T}\Sigma^{-1}(x-y)} d=(x−y)TΣ−1(x−y)
• 马氏距离将协方差考虑进来,排除了样本之间的相关性。
• 马氏距离与欧氏距离相比,就中间多了一项。当协方差为单位矩阵时,马氏距离和欧氏距离相同。
• 欧式距离中,完全是各样本中对应分量相乘,再相加得到,如果某一项的值非常大,那么其值就会掩盖值小的一项所起到的作用,这是欧式距离的不足,当采用马氏距离,就可以屏蔽这一点。因为相关性强的一个分量,对应于协方差矩阵C中对角线上的那一项的值就会大一些。再将这一项取倒数,减小该影响。
• 马氏距离与原始数据的测量单位无关。
一个通俗的例子如下:
如果我们以厘米为单位来测量人的身高,以克(g)为单位测量人的体重。每个人被表示为一个两维向量,如一个人身高 173 c m 173cm 173cm,体重 50000 g 50000g 50000g,表示为 ( 173 , 50000 ) (173,50000) (173,50000),根据身高体重的信息来判断体型的相似程度。
我们已知小明 ( 160 , 60000 ) (160,60000) (160,60000);小王 ( 160 , 59000 ) (160,59000) (160,59000);小李 ( 170 , 60000 ) (170,60000) (170,60000)。根据常识可以知道小明和小王体型相似。但是如果根据欧几里得距离来判断,小明和小王的距离要远远大于小明和小李之间的距离,即小明和小李体型相似。这是因为不同特征的度量标准之间存在差异而导致判断出错。
以克(g)为单位测量人的体重,数据分布比较分散,即方差大,而以厘米为单位来测量人的身高,数据分布就相对集中,方差小。马氏距离的目的就是把方差归一化,使得特征之间的关系更加符合实际情况。
下图(a)展示了三个数据集的初始分布,看起来竖直方向上的那两个集合比较接近。在我们根据数据的协方差归一化空间之后,如图(b),实际上水平方向上的两个集合比较接近。

1.3 聚类准则
聚类准则的选取通常有以下两种:
1.3.1 试探方法
依据经验选择测度和阈值来判别分类,并可以选择一定的训练样本来检验测度和阈值的可靠程度。凭直观感觉,针对实际问题定义一种相似性测度的阈值,然后按最近邻规则指定某些模式样本属于某一个聚类类别。
例如对欧氏距离,它反映了样本间的近邻性,但将一个样本分到不同类别中的哪一个时,还必须规定一个距离测度的阈值作为聚类的判别准则.
1.3.2 聚类准则法
定义一个聚类准则函数,使其转化为最优化问题,比如距离平方和:
J = ∑ i = 1 c ∑ x ∈ S i ∣ ∣ x − m i ∣ ∣ 2 J=\sum\limits_{i=1}^{c}\sum\limits_{x\in S_{i}}||x-m_{i}||^{2} J=i=1∑cx∈Si∑∣∣x−mi∣∣2
x {x} x:模式样本集
S i : i = 1 , 2 , 3 , ⋯ , c {S_{i}:i=1,2,3,\cdots,c} Si:i=1,2,3,⋯,c: 模式类别
m i : m_{i}: mi:样本均值向量
定义如此的聚类函数,将聚类问题转换为求确定函数的最优化问题。
1.4 常见聚类方法
常见的聚类方法有分层聚类法,K-means聚类法,基于密度峰值的聚类方法,均值漂移聚类,凝聚层次聚类等。本篇主要介绍K-means聚类。
1.5 K均值聚类
1.5.1 K均值聚类思想
• 基本思想
1.首先选择若干个样本点作为聚类中心,再按某种聚
类准则(通常采用最小距离准则)使样本点向各中
心聚集,从而得到初始聚类;
2.然后判断初始分类是否合理,若不合理,则修改分
类;
3.如此反复进行修改聚类的迭代算法,直至合理为止。
所用的聚类准则函数是聚类集中每一个样本点到该类中心的距离平方之和,并使其最小化。
1.5.2 K均值聚类流程
- 选择k个聚类中心 z 1 , … , z k {z _{1} ,…, z_{k}} z1,…,zk
- 把样本点分配给最近聚类,即:
x ∈ C i , i f d ( x , C i ) < d ( x , C j ) j ≠ i x\in C_{i},if \ \ d(x,C_{i}) - 更新 z i {z_{i} } zi最小化代价函数,即:
z i = 1 N ∑ C i x = m i z_{i}=\frac{1}{N}\sum\limits_{C_{i}}x=m_{i} zi=N1Ci∑x=mi - 根据新聚类中心更新样本类别
- 直到聚类中心无改变
1.5.3 实例



1.5.4 K均值聚类优点
1.方法简单 方法简单。
2.如果 k 精确且聚类数据可分性好,很容易获得好的聚类效果。
1.5.5 K均值聚类缺点
1.如果k值的选取不正确,那么聚类错误。
2.高度依赖于初始值选取,如下图:
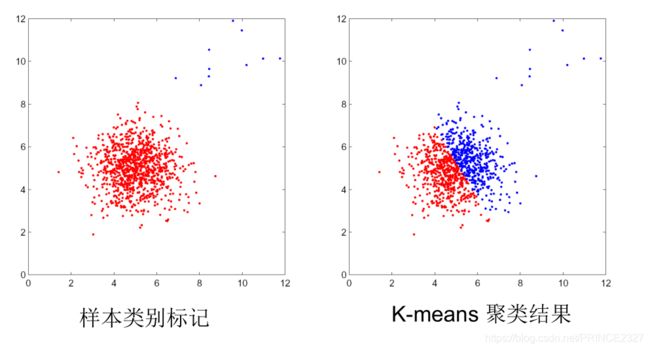
3.更适用“球形”分布的数据,难处理非球形聚类。
1.6 评估指标
聚类的性能评估指标有很多,这里我们着重介绍一种:轮廓系数
轮廓系数的公式如下:
S ( i ) = b ( i ) − a ( i ) m a x ( a ( i ) , b ( i ) ) S(i)=\frac{b(i)-a(i)}{max({a(i),b(i)})} S(i)=max(a(i),b(i))b(i)−a(i)
其中, a ( i ) a(i) a(i)代表样本点的内聚度,公式如下:
a ( i ) = 1 N − 1 ∑ j ≠ i n d ( x i , x j ) a(i)=\frac{1}{N-1}\sum\limits_{j\neq i}^{n}d(x_{i},x_{j}) a(i)=N−11j=i∑nd(xi,xj)
即为样本i与其所属类内其它样本的距离平均值。
b ( i ) b(i) b(i)为样本i与除其所属类外其它类的样本间距离均值的最小值,即:
b ( i ) = m i n ( b 1 ( i ) , b 2 ( i ) , ⋯ , b m ( i ) ) b(i)=min(b_{1}(i),b_{2}(i),\cdots,b_{m}(i)) b(i)=min(b1(i),b2(i),⋯,bm(i))
故有:

当 a ( i ) < b ( i ) a(i)
相反,当 a ( i ) > b ( i ) a(i)>b(i) a(i)>b(i)时,类内的距离大于类间距离,说明聚类的结果很松散。S的值会趋近于-1,越趋近于-1则聚类的效果越差。
一般来说,轮廓系数可以用来选择最合适的类别数k,我们可以绘制横坐标为k取值,纵坐标为轮廓系数的折线图,而后根据这张图选择轮廓系数最接近1的对应k值作为类别数。
1.7 K的选取与肘部法则
1.根据1.6所述的轮廓系数曲线,我们可以画出图像进行选取。
2.除此之外,还可以利用肘部法则进行聚类类别数的选择。具体如下:
将每个簇的质点与簇内样本点的平方距离误差和称为畸变程度(distortions),那么,对于一个簇,它的畸变程度越低,代表簇内成员越紧密,畸变程度越高,代表簇内结构越松散。 畸变程度会随着类别的增加而降低,但对于有一定区分度的数据,在达到某个临界点时畸变程度会得到极大改善,之后缓慢下降,这个临界点就可以考虑为聚类性能较好的点。
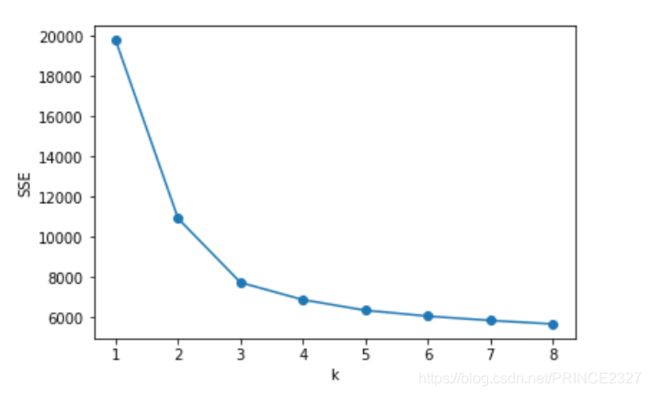
例如上图,横坐标为k值,纵坐标为畸变程度,根据肘部法则,在k=2或3时畸变程度下降最快,而后速度减缓。所以上图所反应出的最佳聚类数应为2或3。
代码部分
2.1 K均值代码实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
def load_data(path):
data=loadmat(path)
#读入数据,这里的数据是mat格式,所以使用loadmat函数
x=data['X']
return data,x
data,x=load_data('ex7data2.mat')
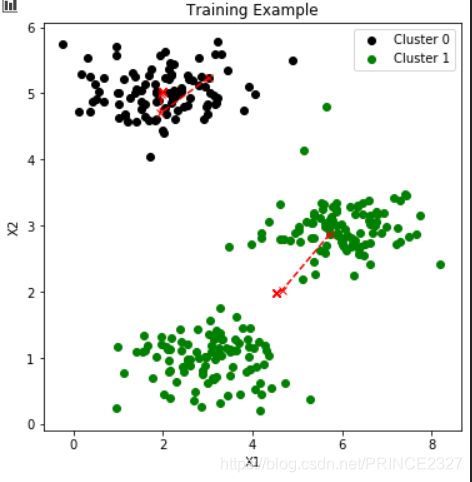
def view_data(x):
fig,ax=plt.subplots(figsize=(6,6))
ax.scatter(x[:,0],x[:,1],c='r')
#画散点图
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_title('Training Example')
plt.show()
#view_data(x)
def get_centroids(x,centroids):
idx=[]
max_distance=10000
for i in range(len(x)):
distance=((x[i]-centroids)[:,0])**2+((x[i]-centroids)[:,1])**2
if distance.min()<max_distance:
ci=np.argmin(distance)
idx.append(ci)
return np.array(idx)
init_cent=np.array([[3,3],[6,2],[8,5]])
idx=get_centroids(x,init_cent)
#返回每个样本所对应的类别
#print(idx,idx.shape)
#print(np.unique(idx))
def computecentroids(x,idx):
centroids=[]
for i in range(len(np.unique(idx))):
u_k=x[idx==i].mean(axis=0)
centroids.append(u_k)
#计算每类中心
return np.array(centroids)
centroids=computecentroids(x,idx)
#print(centroids)
#print(sub,len(sub))
def plot_data(x,centroids,idx):
sub=[]
for i in range(centroids[0].shape[0]):
x_i=x[idx==i]
sub.append(x_i)
colors=['black','g','salmon','black','salmon','yellow','orange','red','green','blue']
fig,ax=plt.subplots(figsize=(6,6))
for i in range(len(sub)):
xx=sub[i]
ax.scatter(xx[:,0],xx[:,1],c=colors[i],label='Cluster {}'.format(i))
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_title('Training Example')
plt.legend()
xx,yy=[],[]
for i in centroids:
xx.append(i[:,0])
yy.append(i[:,1])
# print(xx)
plt.plot(xx,yy,'x--',c='r')
plt.show()
#plot_data(x,[init_cent],idx)
def trainmodel(x,centroids,iters):
K=len(centroids)
centroids_fin=[]
centroids_fin.append(centroids)
centroids_temp=centroids
for i in range(iters):
idx=get_centroids(x,centroids_temp)
centroids_temp=computecentroids(x,idx)
centroids_fin.append(centroids_temp)
return idx,centroids_fin
idx,centroids_fin=trainmodel(x,centroids,10)
#训练模型
#print(centroids_fin)
#plot_data(x,centroids_fin,idx)
def random_init(x,K):
m,n=x.shape
idx=np.random.choice(m,K)
centroids=x[idx]
return centroids
for i in range(1,10):
#尝试聚类簇数
centroids=random_init(x,i)
idx,centroids_fin=trainmodel(x,centroids,10)
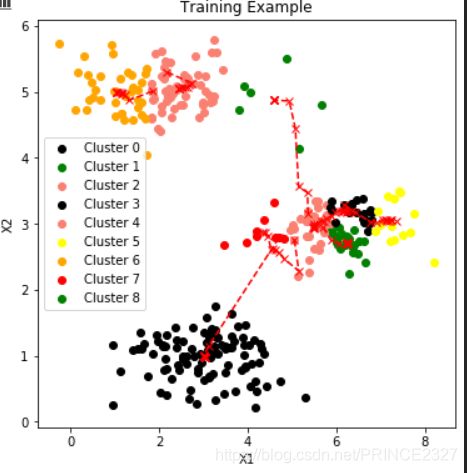
plot_data(x,centroids_fin,idx)
2.2 评估指标代码实现
from sklearn.metrics import silhouette_score
sc_score = silhouette_score(x,idx, metric='euclidean')
这里我们使用sklearn库中的现成评估函数
2.3 整体实现
整体代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.io import loadmat
from sklearn.metrics import silhouette_score
def load_data(path):
data=loadmat(path)
#读入数据,这里的数据是mat格式,所以使用loadmat函数
x=data['X']
return data,x
data,x=load_data('ex7data2.mat')
def view_data(x):
fig,ax=plt.subplots(figsize=(6,6))
ax.scatter(x[:,0],x[:,1],c='r')
#画散点图
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_title('Training Example')
plt.show()
#view_data(x)
def get_centroids(x,centroids):
idx=[]
max_distance=10000
for i in range(len(x)):
distance=((x[i]-centroids)[:,0])**2+((x[i]-centroids)[:,1])**2
if distance.min()<max_distance:
ci=np.argmin(distance)
idx.append(ci)
return np.array(idx)
init_cent=np.array([[3,3],[6,2],[8,5]])
idx=get_centroids(x,init_cent)
#返回每个样本所对应的类别
#print(idx,idx.shape)
#print(np.unique(idx))
def computecentroids(x,idx):
centroids=[]
for i in range(len(np.unique(idx))):
u_k=x[idx==i].mean(axis=0)
centroids.append(u_k)
#计算每类中心
return np.array(centroids)
centroids=computecentroids(x,idx)
#print(centroids)
#print(sub,len(sub))
def plot_data(x,centroids,idx):
sub=[]
for i in range(centroids[0].shape[0]):
x_i=x[idx==i]
sub.append(x_i)
colors=['black','g','salmon','black','salmon','yellow','orange','red','green','blue']
fig,ax=plt.subplots(figsize=(6,6))
for i in range(len(sub)):
xx=sub[i]
ax.scatter(xx[:,0],xx[:,1],c=colors[i],label='Cluster {}'.format(i))
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_title('Training Example')
plt.legend()
xx,yy=[],[]
for i in centroids:
xx.append(i[:,0])
yy.append(i[:,1])
# print(xx)
plt.plot(xx,yy,'x--',c='r')
plt.show()
#plot_data(x,[init_cent],idx)
def trainmodel(x,centroids,iters):
K=len(centroids)
centroids_fin=[]
centroids_fin.append(centroids)
centroids_temp=centroids
for i in range(iters):
idx=get_centroids(x,centroids_temp)
centroids_temp=computecentroids(x,idx)
centroids_fin.append(centroids_temp)
return idx,centroids_fin
idx,centroids_fin=trainmodel(x,centroids,10)
#训练模型
#print(centroids_fin)
#plot_data(x,centroids_fin,idx)
def random_init(x,K):
m,n=x.shape
idx=np.random.choice(m,K)
centroids=x[idx]
return centroids
sc_scores=[]
for i in range(2,10):
#尝试聚类簇数
centroids=random_init(x,i)
idx,centroids_fin=trainmodel(x,centroids,10)
#print(idx)
plot_data(x,centroids_fin,idx)
sc_score = silhouette_score(x,idx, metric='euclidean')
sc_scores.append(sc_score)
fig,ax=plt.subplots(figsize=(6,6))
ax.plot(np.arange(2,10),sc_scores)
ax.grid(True)
ax.set_xlabel('Number of Cluster')
ax.set_ylabel('Silhouette_score')
ax.set_title('Silhouette score for different numer of clusters of k means')
结果如下:

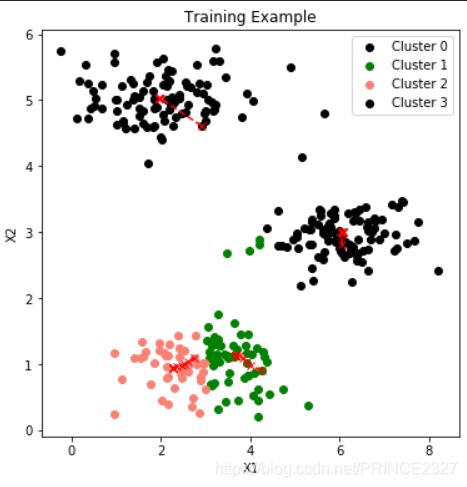
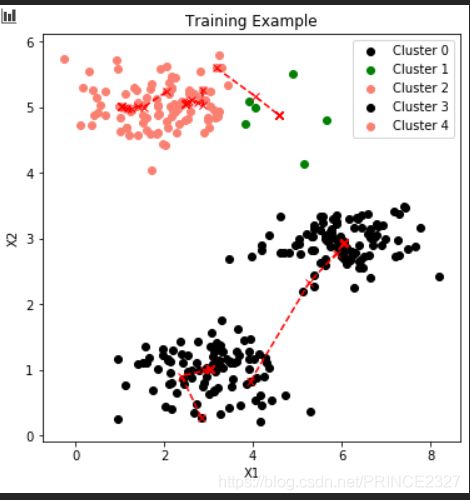
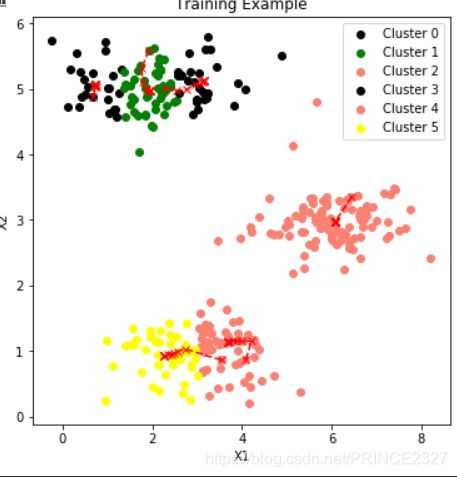
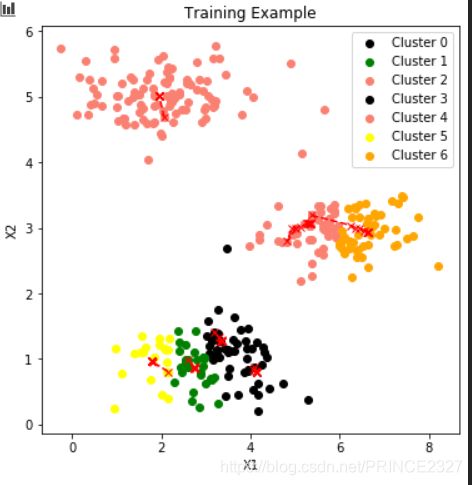

轮廓曲线如下:

可知,这种情况下,K=3最合适。
需要数据集的朋友请私聊我。
未经允许,请勿转载。