硬核!地铁大数据客流分析系统
这个硬核项目最近势头正猛,作者把项目开源到 GitHub 和码云上,连续多日登上 Gitee 热榜。
老逛联系上了这个项目的作者,作者初衷:“最开始我接触到深圳市政府数据开放平台,主要是为了了解参赛题目数据源,无意间看到这个深圳通刷卡数据,感觉可以挖掘的潜在信息很多,于是就开发了这个项目。”
这个项目主要分析深圳通刷卡数据,通过大数据技术角度来研究深圳地铁客运能力,探索深圳地铁优化服务的方向。
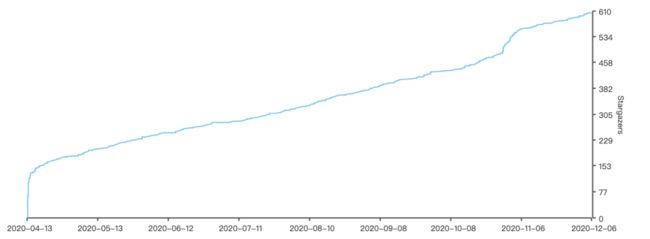
GitHub Star 趋势图
下面是 GitHub 和 Gitee 的开源地址,欢迎大家 Star,该项目使用的数据也在项目里面,国内建议访问 Gitee 速度快一点。
-
https://github.com/geekyouth/SZT-bigdata
-
https://gitee.com/geekyouth/SZT-bigdata
1. 前言
对于刚入门的大数据工程师来说,这个项目是不错的实战项目,因为这个项目使用了较多的常用技术框架,能加深对各技术栈的理解运用。只有在使用过程中才能体验各框架的差异和优劣,从而为以后的项目开发技术选型做基础。
数据来源是深圳市政府数据开放平台,深圳通刷卡数据 133.7 万条离线数据,貌似官网已经停止服务,作者提供了备用数据源,可以在项目中下载。该项目采用离线 + 实时思路 多种方案处理。
2. 效果
快来看看现阶段搭建完成后的效果:
图中可以看出 2018-09-01 这一天刷卡记录集中在上午6点~12点之间,早高峰数据比较吻合,虽然这一天是周六,高峰期不是特别明显。我们继续缩放 kibana 时间轴看看更详细的曲线:
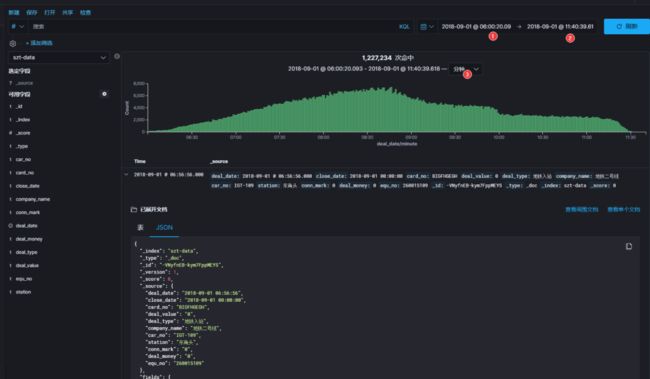
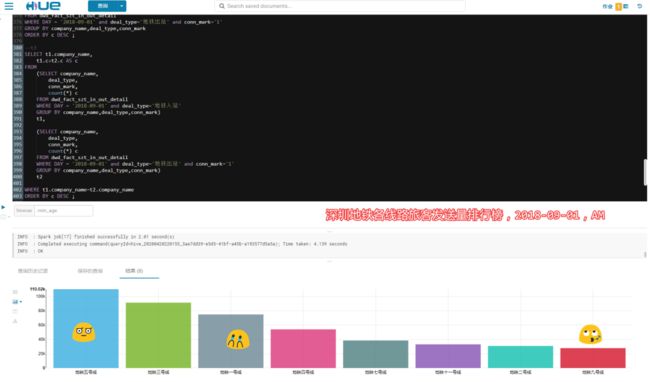
2018-09-01,当天车站吞吐量排行榜:
五和站、布吉站(深圳东火车站)、罗湖站(深圳火车站)、深圳北(深圳北高铁站)
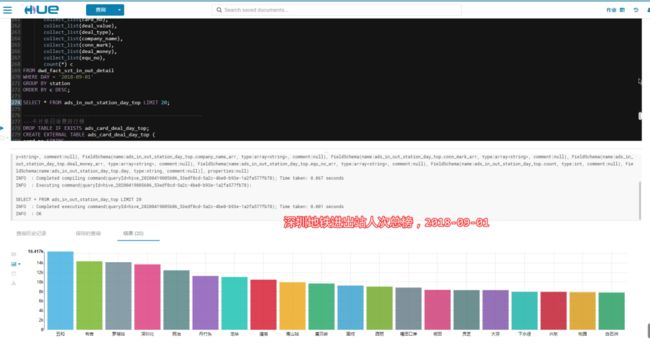
2018-09-01,当天车费最高的乘客花了 48 元人民币。
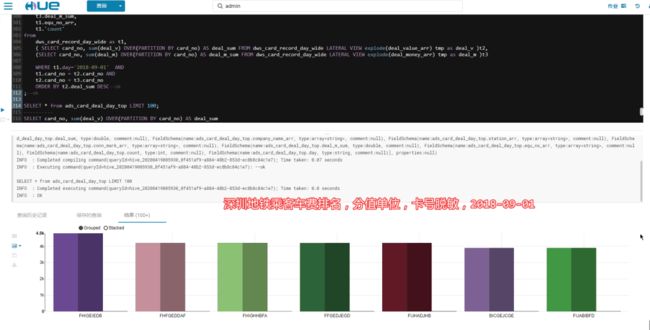
2018-09-01,当天五号线客运量遥遥领先,龙岗线碾压一号线,心疼龙岗人民!
还有很多比如:
-
每日运输乘客最多的区间排行榜
-
每条线路单程直达乘客耗时平均值排行榜
-
所有乘客通勤时间平均值
-
所有乘客通勤时间排行榜
-
每个站点进出站闸机数量排行榜
-
各线路进出站闸机数量排行榜
-
各站收入排行榜
-
各线路收入排行榜
-
各线路换乘出站乘客百分比排行榜
-
各线路直达乘客优惠人次百分比排行榜
-
换乘时间最久的乘客排行榜等等
3. 技术选型
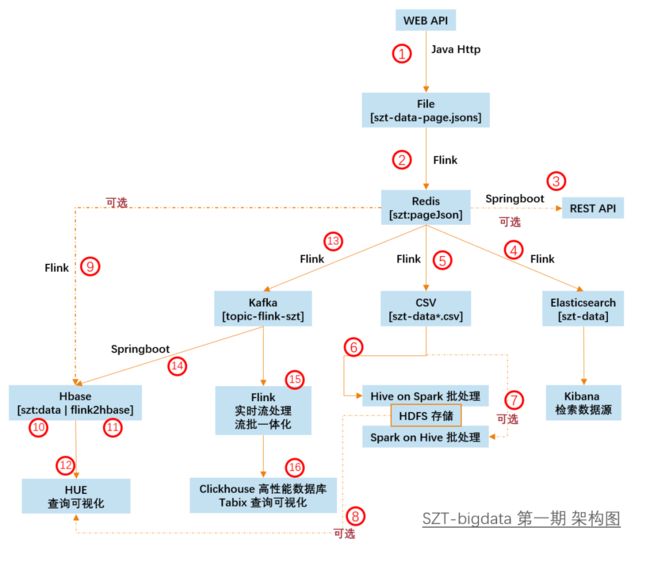
这个项目整体架构是这样的:
技术栈,下图就是这个项目用到的常用技术:

Java-1.8/Scala-2.11:生态丰富,轮子够多;
Flink-1.10:流式业务、ETL 首选。发展势头如日中天,阿里巴巴背书,轻快灵活、健步如飞;
Redis-3.2:天然去重,自动排序,除了快还是快。廉价版硬盘实现同类产品 SSDB。Win10|CentOS7|Docker Redis-3.2:三选一,CentOS REPL yum 安装默认使用3.2版本;
Kafka-2.1:消息队列业务解耦、流量消峰、订阅发布场景首选。最佳 CP:
-
kafka-eagle-1.4.5:集生产、消费、Ksql、大屏、监控、报警于一身,同时监控 zk。其他我用过的 Kafka 监控组件最后都放弃了:
-
KafkaOffsetMonitor 问题太多,丑拒;
-
Kafka Manager,已更名为 CMAK,老外写的软件用起来就觉得很别扭,而且最高只兼容 Kafka 0.11,但是 Kafka 官方已经升级到 2.4 了啊喂;
Zookeeper-3.4.5:集群基础依赖,选举时 ID 越大越优势,通过会话机制维护各组件在线状态;
CDH-6.2:解决了程序员最难搞的软件兼容性问题,全家桶服务一键安装
Docker-19:最快速度部署一款新软件,无侵入、无污染、快速扩容、服务打包。如果当前没有合适的运行环境,那么 docker 一定是首选;
Spring Boot-2.13:通用 JAVA 生态,敏捷开发必备;
knife4j-2.0:前身为 swagger-bootstrap-ui,REST API 项目调试简直不要太方便,秒杀原版丝袜哥十个数量级;
Elasticsearch-7:全文检索领域唯一靠谱的数据库,搜索引擎核心服务,亿级数据毫秒响应,真实时,坑也多。
Kibana-7.4:ELK 全家桶成员,前端可视化,小白也不怕;
ClickHouse:家喻户晓的 nginx 服务器就是俄罗斯的代表作,接下来大红大紫的 clickhouse 同样身轻如燕,但是性能远超目前市面所有同类数据库,存储容量可达PB级别。目前资料还不多,正在学习中;
MongoDB-4.0:文档数据库,对 Json 数据比较友好,主要用于爬虫数据库;
Spark-2.3:目前国内大数据框架实时微批处理、离线批处理主流方案。这个组件太吃资源了,曾经在我开发时,把我的笔记本搞到蓝屏,于是我直接远程提交到 spark 集群了。
Hive-2.1:Hadoop 生态数仓必备,大数据离线处理 OLAP 结构化数据库,准确来说是个 HQL 解析器,查询语法接近 Mysql,就是窗口函数比较复杂。
Impala-3.2:像羚羊一样轻快矫健,同样的 hive sql 复杂查询,impala 毫秒级返回,hive 却需要80秒左右甚至更多;
HBase-2.1 + Phoenix:Hadoop 生态下的非结构化数据库,HBase 的灵魂设计就是 rowkey 和多版本控制,凤凰嫁接 hbase 可以实现更复杂的业务;
Kylin-2.5:麒麟多维预分析系统,依赖内存快速计算,但是局限性有点多啊,适用于业务特别稳定,纬度固定少变的场景,渣渣机器就别试了,内存太小带不起;
HUE-4.3:CDH 全家桶赠送的,强调用户体验,操作数仓很方便,权限控制、hive + impala 查询、hdfs 文件管理、oozie 任务调度脚本编写全靠他了;
阿里巴巴 DataX:异构数据源同步工具,主持大部分主流数据库,甚至可以自己开发插件,如果你觉得这还满足不了你的特殊业务需求,那么推荐你用 FlinkX,基于 Flink 的分布式数据同步工具。理论上你也可以自己开发插件;
Oozie-5.1:本身 UI 奇丑,但是配合 HUE 食用尚可接受,主要用来编写和运行任务调度脚本;
Sqoop-1.4:主要用来从 Mysql 导出业务数据到 HDFS 数仓,反过来也行;
Mysql-5.7:程序员都要用的吧,如果说全世界程序员都会用的语言,那一定是 SQL。Mysql 8.0 普及率不够高,MariaDB 暂不推荐,复杂的函数不兼容 Mysql,数据库这么基础的依赖组件出了问题你就哭吧;
Hadoop3.0(HDFS+Yarn):HDFS 是目前大数据领域最主流的分布式海量数据存储系统,这里的 Yarn 特指 hadoop 生态,主要用来分配集群资源,自带执行引擎 MR;
阿里巴巴 DataV 可视化展示;
作者选择较新的软件版本,因为新版踩坑比老版更多,坑踩的多了,技能也就提高了,遇到新问题可以见招拆招、对症下药。
4. 开发环境
Win10 IDEA 2019.3 旗舰版:JAVA|Scala 开发必备,集万般功能于一身;
Win10 DBeaver 企业版 6.3:秒杀全宇宙所有数据库客户端,几乎一切常用数据库都可以连,选好驱动是关键;
Win10 Sublime Text3:地表最强轻量级编辑器,光速启动,无限量插件,主要用来编辑零散文件、markdown 实时预览、写前端特别友好。
CentOS7 CDH-6.2 集群:包含如下组件,对应的主机角色和配置如图,集群至少需要40 GB 总内存,才可以满足基本使用,不差钱的前提下,RAM 当然是合理范围内越大越好啦,鲁迅都说“天下武功唯快不破”;我们的追求是越快越好;
推荐阅读
0. 逛逛GitHub交流群限时加入
1. 2020 年 GitHub 年度总结出炉!
2. 程序员找工作黑名单
3. 程序员的网易云是什么样的?
4. CentOS 7 安装教程(图文详解)