Hive项目01-mysql、hbase、hive之间的表迁移、映射和查询
本文任务:创建关系型数据库,导入表。将多表结合起来,导入到hbase,然后通过hive映射hbase的数据进行查询。
目录
- 一、MySql表关联概念
- 二、建表
- 三、多表结合
- 四、数据迁移—mysql->hbase
- 五、建立hive映射
- 六、查询
一、MySql表关联概念
关系型数据库的搭建,需要遵循三大范式,而三大范式反过来逼着我们不可避免的要将多个表关联起来。在表关联这一块,如果稍有差错,可能半个小时就完成的工作会因为不断的删表建表搞两三个小时。先说几个概念,
1、外键:如果一张表中有一个非主键的字段指向了另一张表中的主键,就将该字段叫做外键。一张表中外键可以有多个,也就是不同字段指向了不同表中的主键。
2、主键:指的是一个列或多列的组合,可以唯一的标识表中的每一行,通过它可强制表的实体完整性。主键主要是用于其他表的外键关联,以及本表记录的修改与删除。
可以这样理解,本表的外键,需要是其他表的主键,因为主键在它所在的表里是唯一的,所以可以通过其他表的主键来辅助本表进行分类查询等。
关键点:主键一定是唯一的,因为在mysql里只支持一对多和一对一,如果主键不唯一,就会变成多对多。想象一下,有多个老师,教一个班级,同时每位老师带多个班,这样的关系,是得不到类似“姓名:身份证号”这样的通过身份证号找到姓名的这种关系的
把每张表关联起来,有助于我们进一步分析
二、建表
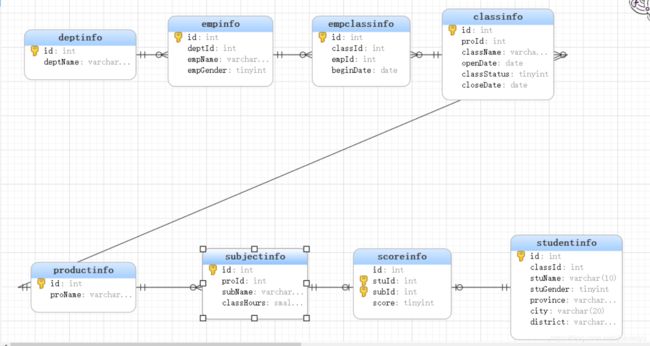
本项目一共八张表
创建数据库
drop database if exists school;
create database school;
use school;
表deptinfo:设置deptinfo.id为自增列主键:auto_increment primary key
create table deptinfo(
id int not null auto_increment primary key,
deptName varchar(20) not null
);
表empinfo:创建empinfo.deptId引用deptinfo.id外键,此时需要确保表deptinfo.deptId在所在表中一定是主键;添加empinfo.empGender默认值为0
create table empinfo(
id int not null auto_increment primary key,
deptId int not null,
empName varchar(10) not null,
empGender tinyint not null default 0,
foreign key(deptId) references deptinfo(id)
on delete cascade
on update cascade
);
表productinfo:添加productinfo.proName为唯一键
create table productinfo(
id int not null auto_increment primary key,
proName varchar(20) not null unique key
);
表subjectinfo:创建subjectinfo.proId引用productinfo.id外键,此时需要确保表productinfo.id在所在表中一定是主键
create table subjectinfo(
id int not null auto_increment primary key,
proId int not null references productinfo (id),
subName varchar(20) not null,
classHours smallint(10) not null,
foreign key(proId) references productinfo(id)
on delete cascade
on update cascade
);
表classinfo:创建classinfo.proId引用productinfo.id外键,此时需要确保表productinfo.id在所在表中一定是主键
create table classinfo(
id int not null auto_increment primary key,
proId int not null,
className varchar(10) not null,
openDate date not null,
classStatus tinyint not null,
closeDate date,
foreign key(proId) references productinfo(id)
on delete cascade
on update cascade
);
表:empclassinfo创建empclassinfo.classId引用classinfo.id外键;创建empclassinfo.empId引用empinfo.id外键。此时需要确保表classinfo.id和empinfo.id在所在表中一定是主键
create table empclassinfo(
id int not null auto_increment primary key,
classId int not null,
empId int not null,
beginDate date not null,
foreign key(classId) references classinfo(id)
on delete cascade
on update cascade,
foreign key(empId) references empinfo(id)
on delete cascade
on update cascade
);
表studentinfo:创建province,city,district组合索引GROIX;添加studentinfo.stuGender默认值为1
create table studentinfo(
id int not null auto_increment primary key,
classId int not null,
stuName varchar(10) not null,
stuGender tinyint not null default 1,
province varchar(20) not null,
city varchar(20) not null,
district varchar(20) not null
);
create index GROIX on studentinfo(province,city,district);
表scoreinfo:创建scoreinfo.stuId引用studentinfo.id外键;创建scoreinfo.subId引用subjectinfo.id外键。此时需要确保表studentinfo.id和subjectinfo.id在所在表中一定是主键
create table scoreinfo(
id int not null unique auto_increment,
stuId int not null,
subId int not null,
score tinyint not null,
primary key(stuId,subId),
foreign key(stuId) references studentinfo(id)
on delete cascade
on update cascade,
foreign key(subId) references subjectinfo(id)
on delete cascade
on update cascade
);
这样我们就把表结构全部创建好了,接下来是导入数据,因数据量较大,本文暂不展示。
三、多表结合
需求:stuName,stuGender,province,city,district,proName,className,openDate,subName,score,将上面这些字段导入到hbase,并映射到hive里。
这里根据业务需求(不用在意为啥只选这些字段,因为业务需要)可以发现,本次任务的前三个表是用不到的,所以可以通过后面5张表的关联,选取上面相应的字段做一个视图。其中分数表是主表,其他信息均可join进去而不会产生更多行的数据。
create view mysql_school as
select sc.id,st.stuName,st.stuGender,st.province,st.city
,st.district,pr.proName,cl.className,cl.openDate,su.subName,sc.score
from scoreinfo sc
inner join studentinfo st on st.id=sc.stuId
inner join subjectinfo su on su.id=sc.subId
inner join productinfo pr on pr.id=su.proId
inner join classinfo cl on cl.id=st.classId;
四、数据迁移—mysql->hbase
业务需求:新建school命名空间,创建mysql_school表,以及basicinfo、classinfo、scoreinfo
然后从数据库根据对应的字段导入到hbase。其中,默认第一个字段为rowkey
需要用到的hbase操作指令:
create_namespace ‘school’
create ‘school:mysql_school’,‘basicinfo’,‘classinfo’,‘scoreinfo’
basicinfo(stuName,stuGender,province,city,district)
sqoop import \
--connect jdbc:mysql://192.168.221.140:3306/school \ #连接mysql,以及对应的数据库school
--username root \ #账户
--password kb10 \ #密码
--table mysql_school \ #要导的表,原表
--columns "id,stuName,stuGender,province,city,district" \ #选择要导的列
--column-family "basicinfo" \ #上面要导的列放在哪个列簇上呢
--hbase-create-table \ #创建表,无论是否已经创建过了
--hbase-row-key "id" \ #指定hbase的rowkey在mysql里对应的字段
--hbase-table "school:mysql_school" \ #指定表名
--num-mappers 1 \ #指定map数量,默认是4
--split-by id #一般用来和num-mappers搭配使用实现任务的并行,这里放这个意义不大
classinfo(proName,className,openDate)
sqoop import \
--connect jdbc:mysql://192.168.221.140:3306/school \
--username root \
--password kb10 \
--table mysql_school \
--columns "id,proName,className,openDate" \
--column-family "classinfo" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "school:mysql_school" \
--num-mappers 1 \
--split-by id
scoreinfo(subName,score)
sqoop import \
--connect jdbc:mysql://192.168.221.140:3306/school \
--username root \
--password kb10 \
--table mysql_school \
--columns "id,subName,score" \
--column-family "scoreinfo" \
--hbase-create-table \
--hbase-row-key "id" \
--hbase-table "school:mysql_school" \
--num-mappers 1 \
--split-by id
导入数据后,通过scan指令检查是否导入成功:
scan ‘NAMESPACE:TABLE’
五、建立hive映射
根据字段(对应mysql和hbase里的字段),stuName,stuGender,province,city,district,proName,className,openDate,subName,score
建一个表结构把数据映射到hive里。
部分概念解释:
1、stored by ‘org.apache.hadoop.hive.hbase.HBaseStorageHandler’:算是固定写法吧
2、with serdeproperties(…):和hbase里列簇的数据一一对应,其中第一个字段默认对应hbase里的主键rowkey,默认不写。
3、tblproperties(“hbase.table.name” = “school:mysql_school”):对应hbase里表的名字
create external table mysql_school(
id int,
stuName string,
stuGender string,
province string,
city string,
district string,
proName string,
className string,
openDate string,
subName string,
score int
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping" = ":key,basicinfo:stuName,basicinfo:stuGender,basicinfo:province
,basicinfo:city,basicinfo:district,classinfo:proName,classinfo:className
,classinfo:openDate,scoreinfo:subName,scoreinfo:score")
tblproperties("hbase.table.name" = "school:mysql_school")
建表的最后是映射数据,因此并不需要往hive里导数据。
对了,hive映射hbase数据,是需要在hbase和hive里jar包互拷的,这个在前一篇文章有讲过。
六、查询
做完上述的准备工作,就可以愉快的查询和解决业务问题啦
有哪些题呢?
为了了解学员学习情况是否存在严重偏科现象
1、查每位学员所有考试中分差最大的两个考试科目、考试成绩、以及分差
create table sub_balance as
with
tab1 as
(
select T1.stuName,T1.subName,T1.score,T1.stuGender
from (
select ms1.stuName,ms1.subName,ms1.score,ms1.stuGender
,row_number() over(distribute by ms1.stuName sort by ms1.score asc) rn1
from mysql_school ms1
)T1
where T1.rn1=1
),
tab2 as
(
select T2.stuName,T2.subName,T2.score
from (
select ms2.stuName,ms2.subName,ms2.score
,row_number() over(distribute by ms2.stuName sort by ms2.score desc) rn2
from mysql_school ms2
)T2
where T2.rn2=1
)
select tab1.stuName,tab1.stuGender,tab1.subName lowsub,tab1.score lowscore,tab2.subName highsub,tab2.score highscore,(tab2.score-tab1.score) diff_score
from tab1
inner join tab2 on tab1.stuName=tab2.stuName
select * from sub_balance
2、根据分差设定偏科类别:分差30分以上为A,20~29为B,10 -19为C,10分以内为D
create table sub_grade as
select *,
if(diff_score>=30,'A',if(diff_score>=20,'B',if(diff_score>=10,'C','D'))) grade
from sub_balance
3、查出A、B类学员班级,姓名,科目Max,科目Min,成绩Min,偏科等级
select * from sub_grade