数仓工具—Hive语法之map join、reduce join、smb join(8)
常见的join实现方式
开始之前我们先说一下join 的定义,然后我们后面在说不同的join,有时候我们需要同时获取两张表或三张表或更多表的信息,我们需要把不同的表关联起来,然后获取数据,这个就是join, 关联的过程就是join 的过程
笼统的说,Hive中的Join可分为Common Join(Reduce阶段完成join)和Map Join(Map阶段完成join),以及Sort Merge Bucket Join 这种划分方式体现在是实现功能的方式上是不同的
除此之外还有不同类型的join,例如 ,oin、 LEFT|RIGTH|FULL OUTER JOIN、 LEFT SEMI JOIN、主要体现在实现的功能是不一样的
Map-side Join
map Join的主要思想就是,当关联的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的表直接放到内存中去,然后再对比较大的表格进行map操作,join就发生在map操作的时候,每当扫描大的表中的中的一行数据,就要去查看小表的数据,哪条与之相符,继而进行连接。
这样的join并不会涉及reduce操作,自然没有shuffle减少了数据通过网络传输造成的高成本和高延迟了,因为Join 是在map 端完成的,所以又叫做map join
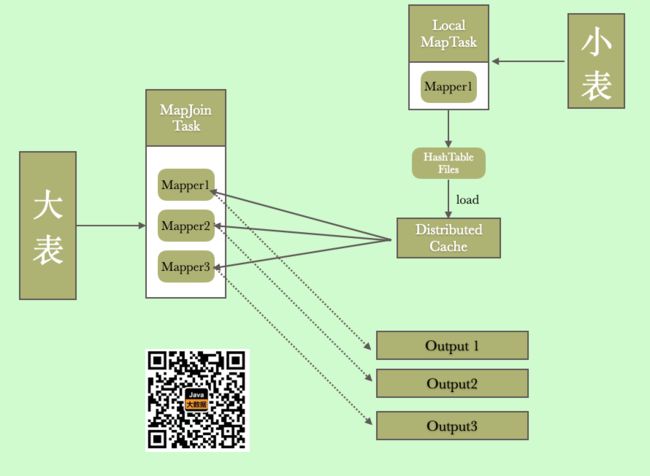
从上面我们看到,处理小表的是一个local task ,它首先将我们的数据封装成了HashTable(key,value),然后将其输出到文件,然后由DistributedCache 进行加载,加载只有其他大表的Mapper 就可以远程拉去DistributedCache中的数据,因为DistributedCache本身是用HashTable 的数据结构存储的,所以真个join 的算法复杂度和大表的大小
并不是所有的场景都适合用MapJoin,它通常会用在如下的一些情景:
-
在两个个要连接的表中,有一个很大,有一个很小,这个小表可以存放在内存中而不影响性能。这样我们就把小表文件复制到每一个Map任务的本地,再让Map把文件读到内存中待用。
-
用来解决数据清洗,例如我们的大表有数据倾斜,那这样的话,某些Reduce 处理的数据就会非常多,因为mapjoin 发生在map端 ,直接没有了reduce 这一环节了
-
mapjoin还有一个很大的好处是能够进行不等连接的join操作,如果将不等条件写在where中(hive 不支持不等值连接,你只能将条件卸载where 中),那么mapreduce过程中会进行笛卡尔积,运行效率特别低,然后再在where 中过滤出需要的数据
我们可以通过下面两个参数来设置map join ,第一个参数是开启map join ,第二个是限制小表的大小
set hive.auto.convert.join=true; //设置 MapJoin 优化自动开启,默认是开启的
set hive.mapjoin.smalltable.filesize=25000000 //设置小表不超过多大时开启 mapjoin 优化,即25M
Hive0.7之前,需要使用hint提示 /*+ mapjoin(table) */才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true,有时候可能会由于map join导致OOM的异常,需要关闭map join
首先我们创建一张稍微比较大的表,大概500M
create table ods_user_log(
id int,
name string,
city string,
phone string,
acctime string)
row format delimited fields terminated by '\t'
stored as textfile;
LOAD DATA LOCAL INPATH '/Users/liuwenqiang/access.log' OVERWRITE INTO TABLE ods_user_log;
然后我们创建一个小表,就是从上面的表中抽取100条
create table ods_user_log_small as select * from ods_user_log limit 100;
接下来,我们创建一条join 语句查询一下
select
a.*
from
ods_user_log a
inner join
ods_user_log_small b
on
a.id=b.id
limit 10
;

我们看到查询耗时 28.614s,我截取了部分处理日志
2021-01-02 14:40:50,409 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:50,409 INFO [main] exec.FilterOperator (Operator.java:initialize(344)) - Initializing operator FIL[13]
2021-01-02 14:40:50,639 INFO [main] exec.SelectOperator (Operator.java:initialize(344)) - Initializing operator SEL[5]
2021-01-02 14:40:50,642 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:50,642 INFO [main] exec.SelectOperator (SelectOperator.java:initializeOp(73)) - SELECT struct
2021-01-02 14:40:50,642 INFO [main] exec.HashTableSinkOperator (Operator.java:initialize(344)) - Initializing operator HASHTABLESINK[15]
2021-01-02 14:40:50,642 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:50,642 INFO [main] mapjoin.MapJoinMemoryExhaustionHandler (MapJoinMemoryExhaustionHandler.java:(61)) - JVM Max Heap Size: 239075328
2021-01-02 14:40:50,653 INFO [main] persistence.HashMapWrapper (HashMapWrapper.java:calculateTableSize(97)) - Key count from statistics is -1; setting map size to 100000
2021-01-02 14:40:50,675 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - No unit for dfs.client.datanode-restart.timeout(30) assuming SECONDS
2021-01-02 14:40:50,675 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:50,654 INFO [main] mr.MapredLocalTask (MapredLocalTask.java:initializeOperators(516)) - fetchoperator for $hdt$_1:b initialized
2021-01-02 14:40:51,258 INFO [main] Configuration.deprecation (Configuration.java:logDeprecation(1395)) - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
2021-01-02 14:40:51,321 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:51,320 INFO [main] mapred.FileInputFormat (FileInputFormat.java:listStatus(259)) - Total input files to process : 1
2021-01-02 14:40:51,352 INFO [main] sasl.SaslDataTransferClient (SaslDataTransferClient.java:checkTrustAndSend(239)) - SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-01-02 14:40:51,423 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:51,423 INFO [main] exec.TableScanOperator (Operator.java:logStats(1038)) - RECORDS_OUT_OPERATOR_TS_3:100, RECORDS_OUT_INTERMEDIATE:0,
2021-01-02 14:40:51,423 INFO [main] exec.SelectOperator (Operator.java:logStats(1038)) - RECORDS_OUT_OPERATOR_SEL_5:100, RECORDS_OUT_INTERMEDIATE:0,
2021-01-02 14:40:51,423 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:51,423 INFO [main] exec.FilterOperator (Operator.java:logStats(1038)) - RECORDS_OUT_INTERMEDIATE:0, RECORDS_OUT_OPERATOR_FIL_13:100,
2021-01-02 14:40:51,423 INFO [main] exec.HashTableSinkOperator (HashTableSinkOperator.java:flushToFile(293)) - Temp URI for side table: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3
2021-01-02 14:40:51 Dump the side-table for tag: 1 with group count: 9 into file: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable
2021-01-02 14:40:51,423 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main-LocalTask-MAPREDLOCAL-stdout] mr.MapredLocalTask (LogRedirector.java:run(65)) - 2021-01-02 14:40:51,423 INFO [main] exec.HashTableSinkOperator (SessionState.java:printInfo(1227)) - 2021-01-02 14:40:51 Dump the side-table for tag: 1 with group count: 9 into file: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable
2021-01-02 14:40:51 Uploaded 1 File to: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable (789 bytes)
2021-01-02 14:40:51,456 INFO [main] exec.HashTableSinkOperator (SessionState.java:printInfo(1227)) - 2021-01-02 14:40:51 Uploaded 1 File to: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01--.hashtable (789 bytes)
上面的处理日志中有几条重要信息,可以帮助我们理解map join 的执行过程
- mr.MapredLocalTask Initializing operator
- Initializing operator HASHTABLESINK
- Dump the side-table for tag: 1 with group count: 9 into file: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01–.hashtable
- Uploaded 1 File to: file:/tmp/hive/local/66c753b7-56d4-429c-bb87-14eed166a61a/hive_2021-01-02_14-40-36_550_872109057128790183-2/-local-10004/HashTable-Stage-3/MapJoin-mapfile01–.hashtable (789 bytes)
从面的执行执行日志中我们看到确实使用的实map join 的实现,也可以得出map join是自动开启的,下面我们关闭掉map join 再执行一次
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
1 苏健柏 渭南 14730379051 2020-03-29 21:12:15
2021-01-02 14:49:06,853 INFO [66c753b7-56d4-429c-bb87-14eed166a61a main] exec.ListSinkOperator (Operator.java:logStats(1038)) - RECORDS_OUT_INTERMEDIATE:0, RECORDS_OUT_OPERATOR_LIST_SINK_14:10,
Time taken: 43.117 seconds, Fetched: 10 row(s)
因为这次关闭了map join,所以你就看不到map join相关的日志输出,并且执行时间也长了很多,其实数据量越大,map join 的效果越明显
Reduce-side(Common) Join
hive join操作默认使用的就是reduce join,reduce side join是一种最简单的join方式,其主要思想如下:
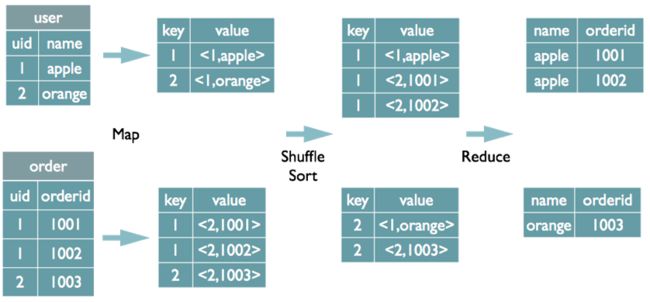
在map阶段,map函数同时读取两个文件File1和File2,为了区分两种来源的key/value数据对,对每条数据打一个标签(tag)接下来通过shuffle 操作,就保证了相同key 的数据落在了桶一个reducer 中,然后在这个reducer 中完相应的join 逻辑
select u.name, o.orderid from order o join user u on o.uid = u.uid; 在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源,然后根据SQL的select 顺序依次将需要的数据读取出来进行返回
SMB Join(sort merge bucket)
前面我们学习过分桶,桶的物理意义就是表目录下的一个文件,前面我们也提到过关于桶可以提高join 的效率Hive的数据组织管理方式,但是我们没有细讲,今天我们看一下,桶可以保证相同key 的数据都分在了一个桶里,这个时候我们关联的时候不需要去扫描整个表的数据,只需要扫描对应桶里的数据(因为key 相同的一定在一个桶里),smb的设计是为了解决大表和大表之间的join的,核心思想就是大表化成小表,然后map side join 解决是典型的分而治之的思想。
这里有一点要注意,那就是数据落在那个桶里不止和key 的值相关,还和桶的个数相关,因为我们是根据key 的哈希值然后对桶的个数取余数获得一个值,然后根据这个值将数据放到对应的桶里去的,所以看出来这个是和桶的个数是相关的,所以一般情况下我们要求不止是两个分桶表的分桶字段是相等的,还要求桶的个数是倍数关系(相等也是可以的)
set hive.enforce.bucketing=true;
set hive.enforce.sorting=true;
表优化数据目标:相同数据尽量聚集在一起
那我们就在就从上面例子的表中,取数据建两个新表
create table ods_user_bucket_log(
id int,
name string,
city string,
phone string,
acctime string)
CLUSTERED BY (`id` ) INTO 5 BUCKETS
row format delimited fields terminated by '\t'
stored as textfile;
create table ods_user_bucket_2_log(
id int,
name string,
city string,
phone string,
acctime string)
CLUSTERED BY (`id` ) INTO 5 BUCKETS
row format delimited fields terminated by '\t'
stored as textfile;
insert overwrite table ods_user_bucket_log select * from ods_user_log;
insert overwrite table ods_user_bucket_2_log select * from ods_user_log;
因为我们是分了5个桶,所以在HDFS 上应该也是有5个文件的

下面我们执行一下SQL 看看
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
select
a.id,b.name
from
ods_user_bucket_log a
inner join
ods_user_bucket_2_log b
on
a.id=b.id
limit 10;
-- 非分桶表
reset;
select
a.id,b.name
from
ods_user_log a
inner join
ods_user_log_2 b
on
a.id=b.id
limit 10;
下面是桶表的执行情况
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vGiDV4HA-1609641870072)(/Users/liuwenqiang/Library/Application%20Support/typora-user-images/image-20210102204950105.png)]
下面是非桶表的执行情况

我们发现桶表的执行虽然快一些,但是差距不是很多,这是因为我们的表不是很大,表越大,效果越明显
总结
- map join 对性能优化有特别明显的效果,而且有很多的适用场景,例如大小表关联、不等值连接、处理数据倾斜
- 关于SMB join主要用来处理大表关联,hive并不检查两个join的表是否已经做好bucket且sorted,需要用户自己去保证join的表,否则可能数据不正确
- Reduce-side(Common) Join 是我们最常见的join 类型,通过shuffle 来完成数据的分发