scrapy爬取链家二手房存到mongo数据库
1.创建项目
scrapy startproject lianjiahouse
2.创建crawl爬虫模板
scrapy genspider -t crawl house lianjia.com
3.然后开始编写item设置需要抓取的字段
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 发布信息名称
house_name = scrapy.Field()
# 小区名称
community_name = scrapy.Field()
# 所在区域
location = scrapy.Field()
# 链家编号
house_record = scrapy.Field()
# 总售价
total_amount = scrapy.Field()
# 单价
unit_price = scrapy.Field()
# 房屋基本信息
# 建筑面积
area_total = scrapy.Field()
# 套内面积
area_use = scrapy.Field()
# 厅室户型
house_type = scrapy.Field()
# 朝向
direction = scrapy.Field()
# 装修情况
sub_info = scrapy.Field()
# 供暖方式
heating_method = scrapy.Field()
# 产权
house_property = scrapy.Field()
# 楼层
floor = scrapy.Field()
# 总层高
total_floors = scrapy.Field()
# 电梯
is_left = scrapy.Field()
# 户梯比例
left_rate = scrapy.Field()
# 户型结构
structure = scrapy.Field()
# 房屋交易信息
# 挂牌时间
release_date = scrapy.Field()
# 上次交易时间
last_trade_time = scrapy.Field()
# 房屋使用年限
house_years = scrapy.Field()
# 房屋抵押信息
pawn = scrapy.Field()
# 交易权属
trade_property = scrapy.Field()
# 房屋用途
house_usage = scrapy.Field()
# 产权所有
property_own = scrapy.Field()
# 图片地址
images_urls = scrapy.Field()
# 保存图片
images = scrapy.Field()
4.编写pipelines.py 一个用来保存数据库,另一个用来存图片
class LianjiahousePipeline(object):
collection_name = 'lianjiahouse'
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri= crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE','lianjia')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self,spider):
self.client.close()
def process_item(self,item,spider):
self.db[self.collection_name].insert(dict(item))
return item
class LianjiaImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['images_urls']:
yield Request(image_url,meta={'item':item})
def file_path(self, request, response=None, info=None, *, item=None):
item = request.meta['item']
image_folder = item['house_name']
image_guild = request.url.split('/')[-1]
image_sava = u'{0}/{1}'.format(image_folder,image_guild)
return image_sava
5.在settings.py中激活pipeline,设置图片的存储信息,mongo数据库信息,robots协议改成false
# -*- coding: utf-8 -*-
# Scrapy settings for lianjiahouse project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'lianjiahouse'
SPIDER_MODULES = ['lianjiahouse.spiders']
NEWSPIDER_MODULE = 'lianjiahouse.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'lianjiahouse (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'lianjiahouse.middlewares.LianjiahouseSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lianjiahouse.middlewares.LianjiahouseDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'lianjiahouse.pipelines.LianjiahousePipeline': 300,
'lianjiahouse.pipelines.LianjiaImagePipeline':400
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
# 图片存储配置
IMAGES_STORE = 'D:\\Scrapy\\chapter5\\5_04\\lianjia\\images'
IMAGES_URLS_FIELD = 'images_urls'
IMAGES_RESULT_FIELD = 'images'
# MongoDB配置信息
MONGO_URI = 'localhost:27017'
MONGO_DATABASE = 'lianjia'
6.然后开始编写爬虫规则
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from lianjiahouse.items import LianjiahouseItem
class HouseSpider(CrawlSpider):
name = 'house'
allowed_domains = ['lianjia.com']
start_urls = ['https://bj.lianjia.com/ershoufang/']
rules = (
Rule(LinkExtractor(allow='/ershoufang/\d{12}.html'), callback='parse_item'),
)
def parse_item(self, response):
i = LianjiahouseItem()
# 二手房名称
i['house_name'] = response.css('title::text').extract_first().replace(' ','')
# 所在小区
i['community_name'] = response.css('.communityName a::text').extract_first()
# i['location'] = response.css()
# 链家编号
i['house_record'] = response.css('.houseRecord .info::text').extract_first()
# 总价
i['total_amount'] = response.css('.overview .total::text').extract_first()
# 房屋信息
# 单价
i['unit_price'] = response.css('.unitPriceValue::text').extract_first()
# 建筑总面积
i['area_total'] = response.xpath('//div[@class="base"]//ul/li[3]/text()')\
.re_first('\d+.\d+')
# 使用面积
i['area_use'] = response.xpath('//div[@class="base"]//ul/li[5]/text()')\
.re_first('\d+.\d+')
# 房屋类型
i['house_type'] = response.xpath('//div[@class="base"]//ul/li[1]/text()')\
.extract_first()
# 房屋朝向
i['direction'] = response.xpath('//div[@class="base"]//ul/li[7]/text()')\
.extract_first()
# 装修情况
i['sub_info'] = response.xpath('//div[@class="base"]//ul/li[9]/text()')\
.extract_first()
# 供暖方式
i['heating_method'] = response.xpath('//div[@class="base"]//ul/li[11]/text()')\
.extract_first()
# 产权
i['house_property'] = response.xpath('//div[@class="base"]//ul/li[13]/text()')\
.extract_first()
# 楼层
i['floor'] = response.xpath('//div[@class="base"]//ul/li[2]/text()')\
.extract_first()
# 总楼层
i['total_floors'] = response.xpath('//div[@class="base"]//ul/li[2]/text()')\
.re_first(r'\d+')
# 是否有电梯
i['is_left'] = response.xpath('//div[@class="base"]//ul/li[12]/text()')\
.extract_first()
# 户梯比例
i['left_rate'] = response.xpath('//div[@class="base"]//ul/li[10]/text()')\
.extract_first()
# 挂牌时间
i['release_date'] = response.xpath('//div[@class="transaction"]//ul/li[1]'
'/span[2]/text()').extract_first()
# 最后交易时间
i['last_trade_time'] = response.xpath('//div[@class="transaction"]//ul/li[3]'
'/span[2]/text()').extract_first()
# 房屋使用年限
i['house_years'] = response.xpath('//div[@class="transaction"]//ul/li[5]'
'/span[2]/text()').extract_first()
# 房屋抵押信息,抵押信息中有空格及换行符,先通过replace()将空格去掉,再通过strip()将换行符去掉
i['pawn'] = response.xpath('//div[@class="transaction"]//ul/li[7]/span[2]'
'/text()').extract_first().replace(' ','').strip()
# 交易权属
i['trade_property'] = response.xpath('//div[@class="transaction"]//ul/li[2]'
'/span[2]/text()').extract_first()
# 房屋用途
i['house_usage'] = response.xpath('//div[@class="transaction"]//ul/li[4]'
'/span[2]/text()').extract_first()
# 产权所有
i['property_own'] = response.xpath('//div[@class="transaction"]//ul/li[6]'
'/span[2]/text()').extract_first()
# 图片url
i['images_urls'] = response.css('.smallpic > li::attr(data-pic)').extract()
yield i
7.运行爬虫 可以看到相关数据 也可以连接mongod
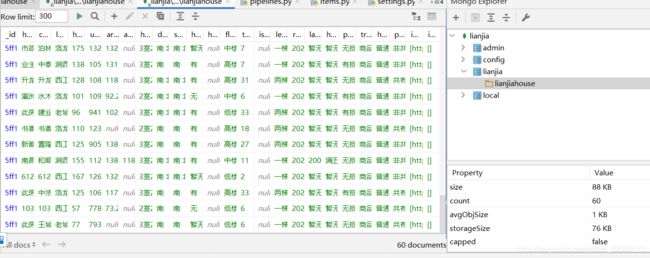
可以看到图片

链家还是比较容易爬取的 完整版代码连接如下