数据竞赛:第四届工业大数据竞赛-虚拟测量
原文首发于我的公众号
背景
注塑成型作为做常见的一种塑料制品加工工艺,它所加工的产品在生活中随处可见,例如电子产品、汽车配件、玩具以及其他众多消费品。由于成型系统较为复杂并且对环境较为敏感,注塑成型加工过程中的不稳定因素很容易导致产品不良的发生,造成经济损失。所以我们建立注塑成型大数据,来感知这些不可见的干扰因素,然后通过分析建模解决甚至避免现场痛点问题。比如成型过程的异常检测预警及不良品的识别,有助于减少甚至避免不合格品的产生,对于管控产品质量、降低生产成本有重要的作用。同时,针对异常产生现场人员因经验差异导致调机无法规范化的问题,如果能够根据成型过程数据和异常事件进行建模分析,改进调机策略,将会节省大量的时间成本和经济成本。
任务
要求选手针对成型工艺品质异常中尺寸超规问题进行虚拟量测。根据训练集所提供所有模次产品的过程数据和相对应的实际量测值(标签)进行虚拟量测模型建模,然后对测试集中的产品进行尺寸预测,即虚拟量测。
数据
本次竞赛的数据集包含以下多种来源:
传感器高频数据:该数据来自于模温机及模具传感器采集的数据,文件夹内每一个模次对应一个csv文件,单个模次时长为40~43s,采样频率根据阶段有20Hz和50Hz两种,含有24个传感器采集的数据;
成型机状态数据(data_spc):该数据来自成型机机台,均为表征成型过程中的一些状态数据,每一行对应一个模次,数据维度为86维;
机台工艺设定参数(data_set):文件夹中含有注塑成型的81种工艺设定参数;
产品测量尺寸(size):文件夹内含有每个模次产品的3维尺寸;
分析
首先根据任务与数据简单查看数据。查看所有特征列,列名,类型,空值统计,基本describe信息。
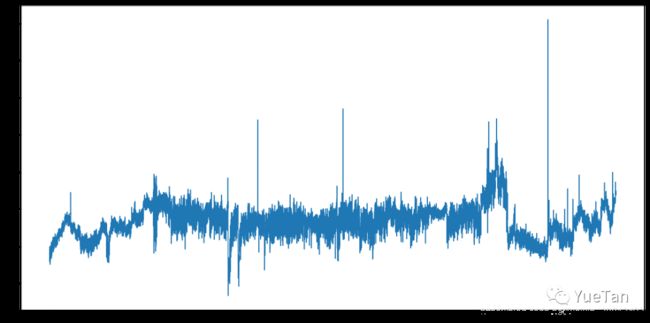
查看目标列的信息。首先是趋势:
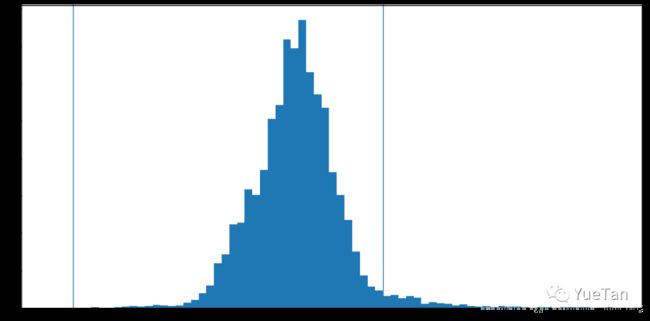
目标列的分布:
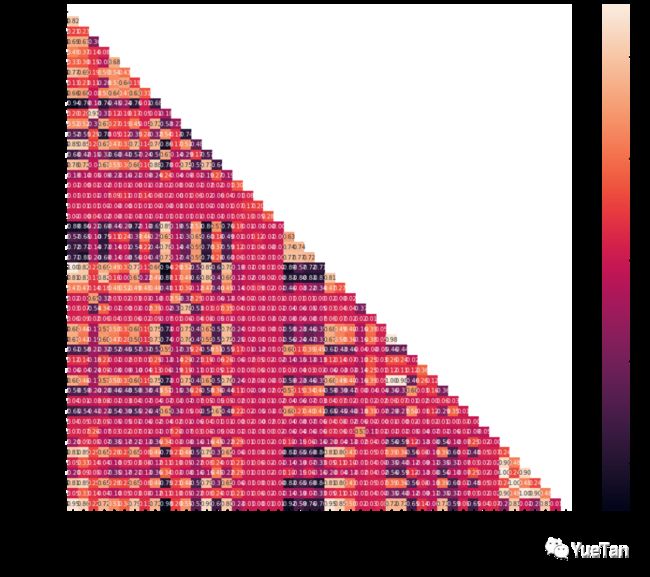
查看各个特征与目标的关系,以及各个特征训练集与测试集分布的不同。

建模
在数据探索性分析基础上,就是建模过程。首先,可以把metrics函数写出来。然后是特征导入,模型、验证、提交各个部分。baseline写完之后,首先保证验证部分是合理的,判断依据是本地测试结果与线上提交结果的同步,允许微小不同,但应保持同步。
对于常规的表格问题,首选尝试自然是lightgbm,除了性能好之外,还可以方便的输出特征重要性,进行特征选型。我的基本模型是这样的,lightgbm和交叉验证融合到一起。
def model():
predictions = np.zeros(len(X_test))
for i, (train_index, val_index) in enumerate(skf.split(X_train,y_train)):
print("fold {}".format(i))
X_tr, X_val = X_train.iloc[train_index], X_train.iloc[val_index]
y_tr, y_val = y_train.iloc[train_index], y_train.iloc[val_index]
lgb_train = lgb.Dataset(X_tr, y_tr)
lgb_val = lgb.Dataset(X_val, y_val)
clf = lgb.train(lgb_params, lgb_train, num_round=2000, valid_sets = [lgb_train, lgb_val],verbose_eval=50,
early_stopping_rounds = 50)
print('best iteration = ', clf.best_iteration)
predictions += clf.predict(X_test, num_iteration=clf.best_iteration) / skf.n_splits
return predictions
迭代与后处理
从数据、特征、模型去考虑细致深入的改进。错误分析,尝试寻找tricks。
也值得纪念一下自己第一次认真参加的数据比赛。决赛的翻车自然就是另一个故事了。
比赛的总结
常规套路
- lightgbm baseline
- nn baseline
- 训练与测试集同分布检测
- 特征筛选(同分布也可以认为是一种提前筛选)
- 本地交叉验证
- 特征工程
以上做的细致一点,初赛可以达到1e5以下。虽然离第一结果很远,但可以维持在top20以内。但是决赛前三天,风云突变,这个成绩只能排50以外了。
弯路
我的大多尝试都越来越差,即使本地测试提高了,排行榜也可能差远了。
其实没什么弯路,只是尝试了太多不起作用的调整,目标后来甚至是能坚持完赛,别放弃就好。若干年后的一个秋天,当我回想起我第一次参加数据比赛的经历,因为好好了解了一下注塑机的历史,大概只记得注塑机的发明动力源自以前的台球都是昂贵的象牙做的。
欢迎关注,我是YueTan