目标检测:Yolov5集百家之长
首发于:公众号YueTan
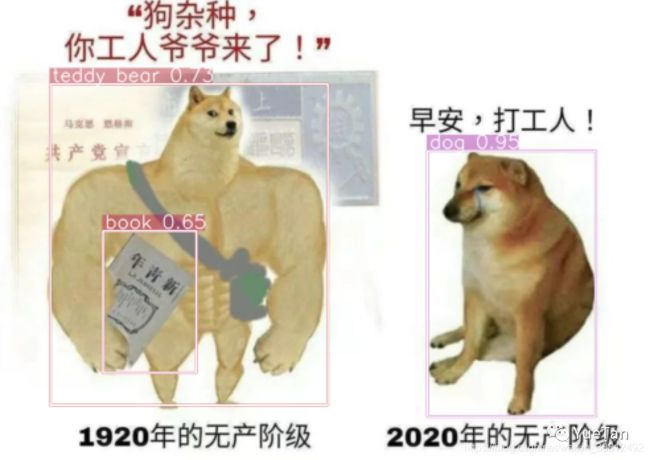
(1920,被识别为泰迪熊?有排面)
背景
2017年底,我已毕业多年了。用起Excel和PPT、研究车的质量问题俨然老手的样子。有一晚,照着一个帖子跑了一下Yolov1的inference,惊为天人。蹑手蹑脚的搞环境、下模型、跑一下clone的程序,就把摄像头前的物体都用框框标记了出来。在不懂原理的我看来,大概惊叹了一晚上。
那份惊叹,也让我和许多年轻人一起决定加入AI的行列。我现在常常吹嘘,自己大学七年对航空和汽车发动机多了解,工作五年对汽车掌握的多透彻,彷佛放弃了十二年优异的经验,其实都是人设啊。我根本就学不好,现在也完全不记得了。(当然,搞AI也只是现在的人设罢了,不要当真)
时过境迁,在AI方面我还是小学生,Yolo已经从V1发展到了V5,并有各种衍生和优化版本。我们津津乐道它的名字是You only look once的简写,原意“你只看一遍”是为了区分看“两遍”的faster-rcnn等二阶段模型,其简写Yolo又寓意着另一句谚语"You only live once",生命只有一次。就像食神里说的“不仅好吃,还有噱头,我也忍不住买了一碗“。
充满噱头的除了性能、名字外甚至还有作者本身,作者年初时宣布因为对技术滥用的担忧放弃视觉研究了,颇有高人之风。而且明明是个大胡子,个人网站却是满满粉色独角兽的萌妹风格。写的论文中,为了突出速度之快,甚至故意把图画到坐标轴外面去了。
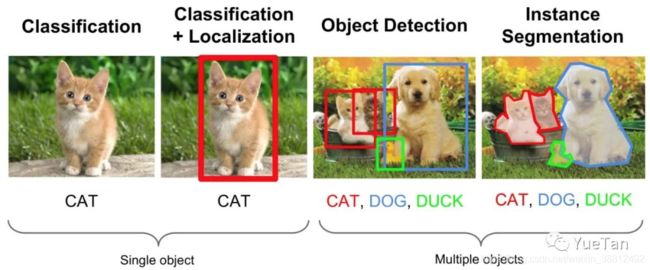
机器视觉任务,常见的有分类、检测、分割。而Yolo正是检测中的佼佼者,在工业界,Yolo兼顾精度和速度,往往是大家的首选。
效果
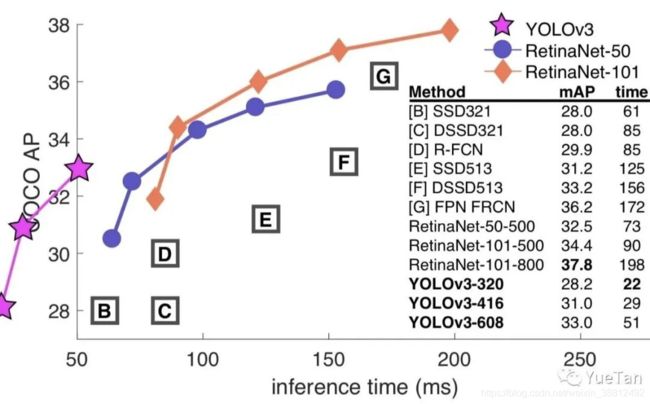
V5的效果也是非常不错:
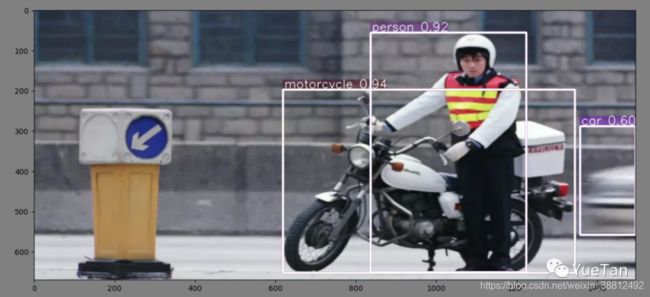


其实,yolov4刚出来的时候,大家还对名字争议了一番。毕竟原作者已经弃坑,新作看上去又是一个trick集合。马上yolov5出现之后,似乎对v4的质疑就消失了,因为v5这个名字起的似乎更离谱了。这里就不讨论名字争议了。
原理
作为一阶段end2end的检测算法代表作,我们简单回顾一下Yolo从V1到V5的主要改进措施,当然backbone也一直在进化着。
v1: 划分网格负责检测,confidence loss
v2: 加入k-means的anchor,两阶段训练,全卷积网络
v3: FPN多尺度检测
v4: spp,mish激活函数,数据增强mosaic\mixup,giou损失函数
v5: 对模型大小灵活控制,hardswish激活函数,数据增强
v1/v2因为对小目标检测效果不佳,在v3中加入了多尺度检测。v3大概可以比作iphone界的iphone6,是前后代广受好评的大成者,至今仍活跃在一线,“等等党永远不亏”。Yolov4把整个流程中可能进行的优化都梳理和尝试了了一遍,并找到了各个排列组合中的最好效果。v5可以灵活的控制从10+M到200+M的模型,其小模型非常惊艳。
v3到v5的整体网络图相差不多,可以清晰的看到:模型从三个不同尺度分别对大小不同的物体有重点的进行检测。
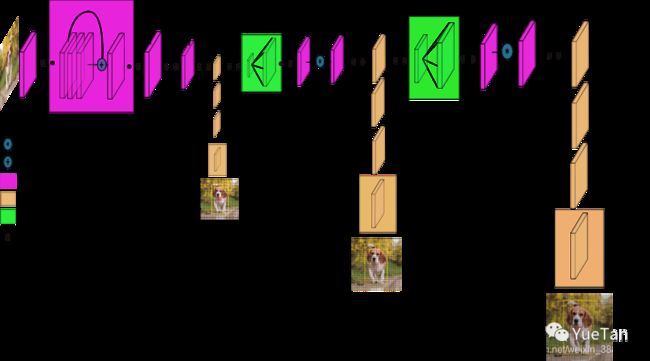
细节
数据增强和预处理
由于模型需要图片尺寸相同,因此可以采用resize、padding resize和letterbox的方法。letterbox训练的时候不用,只是在推理时候用。数据增强(data augmentation)是提升模型泛化能力的重要手段。
flip: 翻转

perspective:仿射变换
hsv augment:颜色变换

mosaic:马赛克数据增强把原来的四幅图组在一起

当然后面可以试试albumentations包里的方法。
获取anchor:k-means
早就在机器学习中学过最基础的聚类算法k-means,没想到第一次用上是在目标检测里。果然没有免费的午餐啊,在合适的地方用上合适的算法就好。k-means的两个关键超参数是k的选择和距离的选择,所以在Yolo中的k等于n_scale(尺度,一般为3)* anchor_per_scale (每个尺度的anchor,一般也为3)。V5做了一点小小的改进:训练时自动获取。
匹配anchor和网格
虽然讨论的时候,经常看见的都是改了哪些fancy的模型,真正写程序时比较困难的反而是这种数据前处理的pipeline。yolo的关键思想通过标记物体的中心点落在哪个网格里,就由这个网格负责检测,就是通过设置目标来实现的。
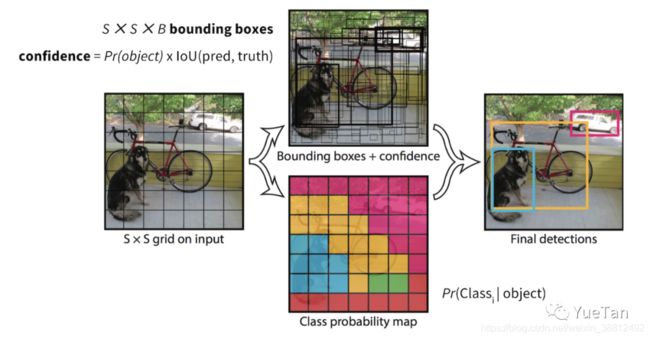
1)计算这张图片所有ground truth与每一个anchor的IOU,从而得到对每一个ground truth匹配最好的anchor id。可以根据真实框和锚矿的IOU或者长宽比来选择,v4与v5中做的改进是根据宽高比来进行anchor的匹配。
2)对每一个ground truth循环。找到这个anchor对应的尺度,和这个anchor对应的哪一个anchor。
3)模型最终输出的是三个尺度,每个尺度下每个网格带下的三个anchor对应的box。所以将标记的box也要放置到对应的grid里,对应的是三个anchor里的哪一个。根据上面找到对应grid,对应anchor,将标记的box尺寸和class 信息设置到目标里,其他设置为0。
另外两个改进点,一个改进点是正样本增强。通过正样本的增强可以减轻正负样本的不均衡。另一个改进点是标注框对anchor的encoding(编码方式)。从v2中引入anchor以来,一直通过如下编码方式
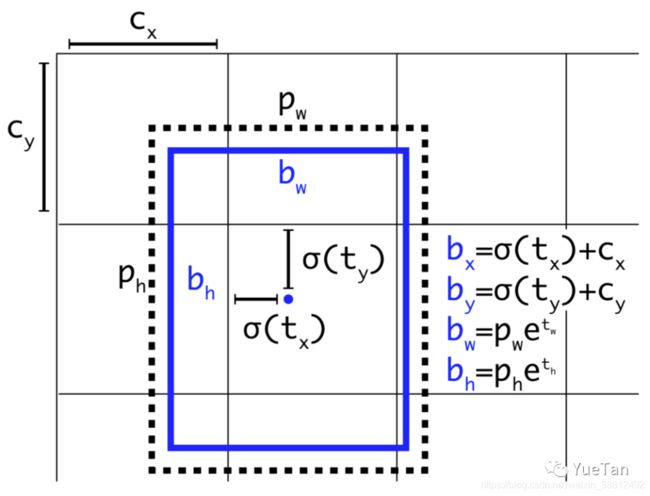
为了解决网格的敏感性,v4的作者发现简单的编码方式就可以提高结果。
x = (logistic(in) * 2 - 0.5 + grid_x) / grid_width
y = ...
w = pow( logistic(in)*2, 2) * anchor / network_width
h = ...
模型主体
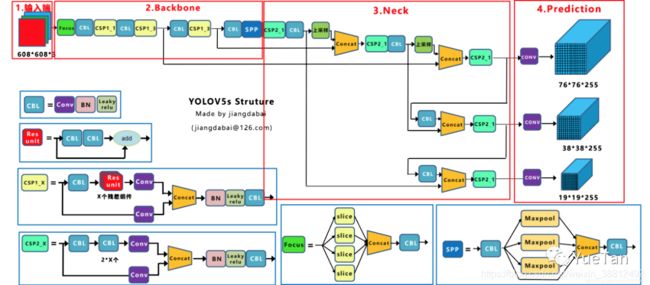
(来自dabai同学)
v5的模型通过类似EfficientNet的两个系数来控制模型的宽度和深度,在yaml文件的depth_multiple和width_multiple中调节。
Focus:是v5相对v4的改进。
CSPNet:跨阶段局部融合网络
PANet:之前FPN是把传统视觉任务的图像金字塔改进到了深度学习的特征金字塔,来自论文Path Aggregation Network for Instance Segmentation。
损失函数
Yolo的损失函数比较惊艳,通过损失函数的设定把目标检测任务转化为一个回归任务。
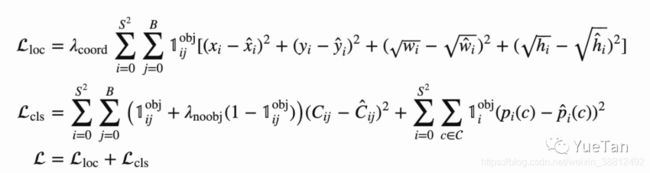
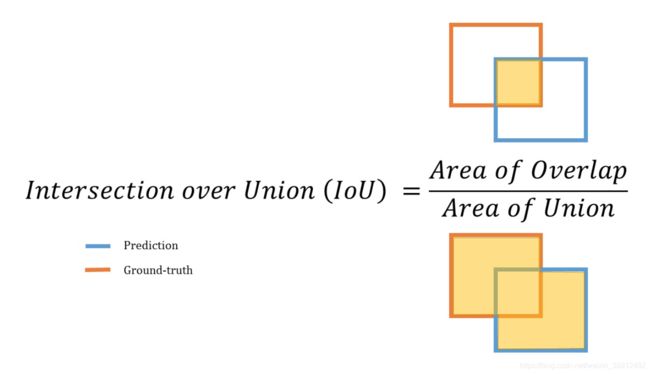
第一部分为box的损失函数,可以用过smoth L1损失函数计算xywh,也可以通过iou、giou、ciou等。类似的giou、diou和ciou都是在交并比iou的基础上发展而来的优化方法,解决了iou在两个候选框完全没有交集时,损失为0不可优化的状况。第二部分为有无物体的损失:yolo独特的设置了一个有无物体的confidence,目标中有的自然设置为1。预测的值用sigmoid转化为(0,1)的概率,然后计算binary cross entropy。第三部分为分类损失部分,虽然是多分类,也采用binary corss entropy。
同时,为了平衡不同尺度的输出,v5中对以上三部分加了人工痕迹比较明显的系数。
后处理
极大值抑制(nms)。分三个尺度进行检测,且分配不同的anchor,那么同一个物体有可能被多个尺度、anchor所检测到。所以通过极大值抑制来从中选择最佳的候选框。也有soft-nms、matrix-nms等改进方式可以试一试。
训练
训练过程就比较平平无奇了,可以添加如下技巧:梯度累积、遗传算法、EMA滑动平均、算子融合。
展望
检测之外,之后还可以继续拓展和优化的方向:
- tensorrt推理加速
- deepsort物体追踪,可以稳定视频中检测框的抖动
- 针对小目标分割patch检测,例如卫星遥感图像的改进you only look twice
- 多尺度scalable yolov4
致谢
更多内容可以关注我的公众号YueTan