Python可视化(7):Pandas—转换与处理时间序列数据
时间序列数据
-
- 1. 什么是时间序列?
-
- 1.1 Timestamp类型(时间戳)
- 1.2 DatetimeIndex与PeriodIndex
- 2. 创建固定频率的时间序列—pandas.date_range()
- 3. 创建时期对象
- 4. 提取时间序列数据信息
-
- 4.1 加减时间数据--Timedelta类
- 【练习】绘制出5个城市的PM2.5随时间的变化情况。
文件在网盘里哟,除此之外还有其他文件资料呐。
链接:11讲 转换与处理时间序列数据
提取码:2p61
数据分析的常用数据类型有数值型、类别型和时间类型。时间类型数据在读入Python后常常以字符串的形式出现,不便于时间数据的分析。因此,在分析时间类型数据前,需要将时间字符串进行转换、信息提取。
1. 什么是时间序列?
时间序列是指多个时间点上形成的数值序列,它既可以是定期出现的,也可以是不定期出现的。
时间序列的数据主要有以下几种:

pandas继承了NumPy库和datetime库的时间相关模块,提供了6种时间相关的类。

1.1 Timestamp类型(时间戳)
to_datatime()函数
该对象与datetime具有高度的兼容性,可以直接通过 to_datetime() 函数将datetime转换为TimeStamp对象。
pd.to_datetime('时间字符串')
# 将datetime转换为Timestamp对象
import pandas as pd
import numpy as np
print(pd.to_datetime('20201102'))
# 读取 meal_order_info.csv 文件内容
# 查看 lock_time 的类型
# 将 lock_time 的类型转换成 Timestamp
order = pd.read_table('./meal_order_info.csv',sep = ',',encoding = 'gbk')
print('进行转换lock_time的类型为:', order['lock_time'].dtypes)
order['lock_time'] = pd.to_datetime(order['lock_time'])
print('转换后lock_time的类型为:',order['lock_time'].dtypes)
1.2 DatetimeIndex与PeriodIndex
(1) 如果 to_datetime() 函数传入的是多个 datetime 组成的列表,则 Pandas会将其强制转换为 DatetimeIndex 类对象。
# 传入多个datetime字符串
date_index = pd.to_datetime(['20201001', '20201010', '20201020'])
print(date_index)
# DatetimeIndex 作为 Series对象的索引
ser_obj = pd.Series(data=[3,4,5], index=date_index)
print(ser_obj)
# 如果希望DataFrame对象具有时间戳索引,也可以采用上述方式进行创建。
data = [[11,22,33],[44,55,66],[77,88,99]]
df = pd.DataFrame(data, date_index)
print(df)
(2)DatetimeIndex与PeriodIndex函数
-
除了将数据从原始 DataFrame 中直接转换为 Timestamp 格式外,还可以将数据单独提取出来将其转换为DatetimeIndex或者PeriodIndex。
-
DatetimeIndex和PeriodIndex两者区别在日常使用的过程中相对较小,其中DatetimeIndex是用来指代一系列时间点的一种数据结构,而PeriodIndex则是用来指代一系列时间段的数据结构。
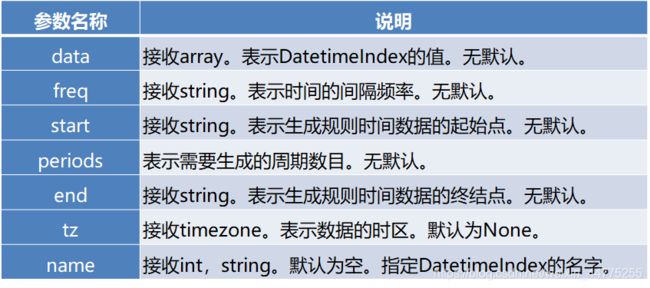
DatetimeIndex与PeriodIndex函数及其参数说明:
# 将 lock_time 数据转换成时间戳索引
dateIndex = pd.DatetimeIndex(order["lock_time"])
print(dateIndex)
(3) 转换为PeriodIndex的时候需要注意,需要通过 freq 参数指定时间间隔,常用的时间间隔有Y为年,M为月,D为日,H为小时,T为分钟,S为秒。两个函数可以用来转换数据还可以用来创建时间序列数据。
periodIndex = pd.PeriodIndex(order["lock_time"], freq="s")
print(periodIndex)
2. 创建固定频率的时间序列—pandas.date_range()
Pandas中提供了一个 date_range() 函数,主要用于生成一个具有固定频率的 DatetimeIndex对象。

(1) 当调用 date_range() 函数创建 DatetimeIndex 对象时,如果只是传入了开始日期(start参数)与结束日期(end参数),则默认生成的时间戳是按天计算的,即freq参数为 D。
# 创建DatetimeIndex对象时,只传入开始日期与结束日期
pd.date_range("20201201", "20210101")
(2) 如果只是传入了开始日期或结束日期,则还需要用 periods 参数指定产生多少个时间戳。
# 创建 DatetimeIndex 对象时,传入 start与 periods参数
pd.date_range(start="20210101", periods=10)
# 创建DatetimeIndex对象时,传入end与periods参数
pd.date_range(end= "20210110", periods=10)
(3)如果希望时间序列中的时间戳都是每周固定的星期一,则可以在创建 DatetimeIndex 时将 freq 参数设为“W-MON”。
pd.date_range(start="20210101", periods=10, freq="W-MON")
时间序列的频率 freq
-
默认生成的时间序列数据是按天计算的,即频率为“D”。
-
“D”是一个基础频率,通过用一个字符串的别名表示,比如“D”是“day”的别名。
-
频率是由一个基础频率和一个乘数组成的,比如,“5D”表示每5天。

3. 创建时期对象
Period类 表示一个标准的时间段或时期,比如某年、某月、某日、某小时等。
创建 Period类对象的方式比较简单,只需要在构造方法 pd.Period() 中以字符串或整数的形式传入一个日期即可。
# 创建Period对象,表示从2020-01-01到2020-12-31之间的时间段
p1 = pd.Period(2020)
print(p1)
# 表示从2020-11-01到2020-11-30之间的整月时间
p2 = pd.Period("2020-11")
print(p2)
# Period对象加上一个整数
p3 = pd.Period("2020-11", freq="M")
p4 = p3 + 1
print(p4)
4. 提取时间序列数据信息
在多数涉及时间相关的数据处理,统计分析的过程中,需要提取时间中的年份,月份等数据。使用对应的Timestamp类属性就能够实现这一目的。
结合Python列表推导式,可以实现对DataFrame某一列时间信息数据的提取。

# 提取 lock_time的年份、月份、日期、星期几 数据前5个
year1 = [i.year for i in order['lock_time']]
print('lock_time中的年份数据前5个为:',year1[:5])
month1 = [i.month for i in order['lock_time']]
print('lock_time中的月份数据前5个为:',month1[:5])
day1 = [i.day for i in order['lock_time']]
print('lock_time中的日期数据前5个为:',day1[:5])
weekday1 = [i.dayofweek+1 for i in order['lock_time']]
print('lock_time中的星期数据前5个为:',weekday1[:5])
# 在DatetimeIndex和PeriodIndex中提取信息
print('dateIndex中的年份数据前5个为:\n',
dateIndex.year[:5])
print('periodIndex中的年份数据前5个为:',
periodIndex.year[:5])
4.1 加减时间数据–Timedelta类
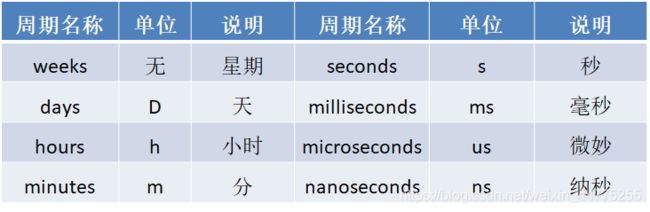
Timedelta是时间相关的类中的一个异类,不仅能够使用正数,还能够使用负数表示单位时间,例如1秒,2分钟,3小时等。使用Timedelta类,配合常规的时间相关类能够轻松实现时间的算术运算。目前Timedelta函数中时间周期中没有年和月。所有周期名称,对应单位及其说明如下表所示。
# 将lock_time数据向后平移一天
time1 = order['lock_time']+pd.Timedelta(days = 1)
print('lock_time在加上一天前前5行数据为:\n',order['lock_time'][:5])
print("-"*40)
print('lock_time在加上一天前前5行数据为:\n',time1[:5])
使用Timedelta ,可以很轻松地实现在某个时间上加减一段时间。
除了使用Timedelta实现时间的平移外,还能够直接对两个时间序列进行相减,从而得出一个Timedelta。
timeDelta = order['lock_time'] - pd.to_datetime('2016-7-1')
print('lock_time减去2016年7月1日0点0时0分后的数据:\n',
timeDelta[:5])
print('lock_time减去time1后的数据类型为:',timeDelta.dtypes)
【练习】绘制出5个城市的PM2.5随时间的变化情况。
1、有5个文件分别存储5个城市的PM2.5数据,如下:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1.读取数据
beijing = pd.read_csv(r"C:\PM2.5\BeijingPM20100101_20151231.csv",encoding="gbk")
chengdu = pd.read_csv(r"C:\PM2.5\CHengduPM20100101_20151231.csv",encoding="gbk")
guangzhou = pd.read_csv(r"C:\PM2.5\GuangzhouPM20100101_20151231.csv",encoding="gbk")
shanghai = pd.read_csv(r"C:\PM2.5\ShanghaiPM20100101_20151231.csv",encoding="gbk")
shenyang = pd.read_csv(r"C:\PM2.5\ShenyangPM20100101_20151231.csv",encoding="gbk")
# print(shanghai)
# 2. 将时间字符串转换成时间序列索引
bj_period = pd.PeriodIndex(year=beijing["year"],month=beijing["month"],day=beijing['day'],hour=beijing['hour'],freq='H')
cd_period = pd.PeriodIndex(year=chengdu["year"],month=chengdu["month"],day=chengdu['day'],hour=chengdu['hour'],freq='H')
gz_period = pd.PeriodIndex(year=guangzhou["year"],month=guangzhou["month"],day=guangzhou['day'],hour=guangzhou['hour'],freq='H')
sh_period = pd.PeriodIndex(year=shanghai["year"],month=shanghai["month"],day=shanghai['day'],hour=shanghai['hour'],freq='H')
sy_period = pd.PeriodIndex(year=shenyang["year"],month=shenyang["month"],day=shenyang['day'],hour=shenyang['hour'],freq='H')
# print(bj_period)
# 3. 时间序列索引
beijing.reset_index(inplace=True)
chengdu.reset_index(inplace=True)
guangzhou.reset_index(inplace=True)
shanghai.reset_index(inplace=True)
shenyang.reset_index(inplace=True)
# 4. 重新设置索引,将添加的时间序列一列设置为行索引。 set_index
beijing=beijing.set_index(bj_period)
chengdu=chengdu.set_index(cd_period)
guangzhou=guangzhou.set_index(gz_period)
shanghai=shanghai.set_index(sh_period)
shenyang=shenyang.set_index(sy_period)
# print(beijing)
# 5.使用 PM_US Post 降维
# 由于数据点太多,先进行重采样
PM_bj=beijing["PM_US Post"].resample('7D').mean()
PM_cd=chengdu["PM_US Post"].resample('7D').mean()
PM_gz=guangzhou["PM_US Post"].resample('7D').mean()
PM_sh=shanghai["PM_US Post"].resample('7D').mean()
PM_sy=shenyang["PM_US Post"].resample('7D').mean()
# 6. 设置r1为X轴,PM_bj.values为Y轴
r1 = range(len(PM_bj.index))
r2 = range(len(PM_cd.index))
r3 = range(len(PM_gz.index))
r4 = range(len(PM_sh.index))
r5 = range(len(PM_sy.index))
# 6. 绘图
plt.figure(figsize=(18,6))
plt.plot(r1,PM_bj.values,color='r',label="北京PM2.5")
plt.plot(r2,PM_cd.values,color='g',label="成都PM2.5")
plt.plot(r3,PM_gz.values,color='y',label="广州PM2.5")
plt.plot(r4,PM_sh.values,color='b',label="上海PM2.5")
plt.plot(r5,PM_sy.values,color='k',label="沈阳PM2.5")
plt.xticks(range(0,len(PM_bj.index),10),list(PM_bj.index)[::10],rotation=45)
plt.legend()
plt.savefig(r"C:\Users\Desktop\PM2.5.png", dpi=800)
plt.show()