三十三、Hive中的查询语句
前面几章分别讲了Hive的数据定义和数据操作,本章主要讲一下Hive的查询。关注专栏《破茧成蝶——大数据篇》,查看更多相关的内容~
目录
一、基础查询
1.1 全表查询
1.1.1 全表查询
1.1.2 查询指定列
1.2 别名
1.3 算术运算符
1.4 常用基础函数
二、LIMIT语句
三、WHERE语句
3.1 比较运算符
3.2 逻辑运算符
四、分组函数
4.1 GROUP BY语句
4.2 HANING子句
五、JOIN语句
六、排序
6.1 Order by语句
6.2 Sort by语句
6.3 Distribute By语句
6.4 Cluster By语句
七、分桶查询
一、基础查询
首先,查询语句的语法可以概括为如下:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY col_list]
]
[LIMIT number]我们先来看下基础的查询操作,即不包含任何筛选条件的查询。还是用一个例子开始说明吧。还是以咱们之前建的people表为例吧,里面包含三列,分别是:id、姓名和性别。为了方便读者,这里再将其创建过程贴出一下,当然,也可以翻阅咱们之前的博客,里面都有介绍过。
1、首先创建people表:
create table if not exists people(
id string,
name string,
sex string
)
row format delimited fields terminated by ',';2、构造测试数据:

3、加载数据到people表:
load data local inpath '/root/files/p.txt' into table people;
1.1 全表查询
1.1.1 全表查询
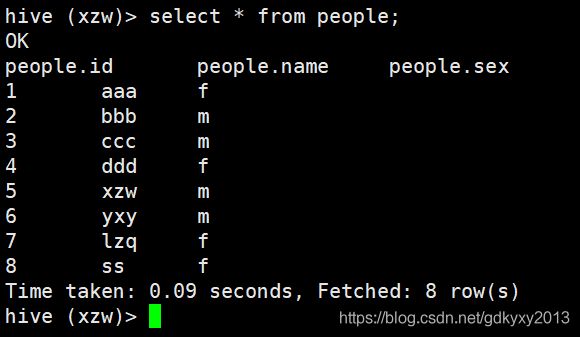
1.1.2 查询指定列

1.2 别名
可以通过给查询列起别名的方式来更改原有列的名称:

1.3 算术运算符
可以通过算术运算符对查询的内容进行基础的操作,常用的算术运算符如下所示:
| 运算符 |
描述 |
| A+B |
A和B相加 |
| A-B |
A减去B |
| A*B |
A和B相乘 |
| A/B |
A除以B |
| A%B |
A对B取余 |
| A&B |
A和B按位取与 |
| A|B |
A和B按位取或 |
| A^B |
A和B按位取异或 |
| ~A |
A按位取反 |
1.4 常用基础函数
通过函数,可以对查询的内容进行相应的操作,下面是常用的一些基础函数:
| 函数 |
描述 |
| count() |
求记录数 |
| max() |
求最大值 |
| min() |
求最小值 |
| avg() |
求平均值 |
| sum() |
求和 |
二、LIMIT语句
可以使用LIMIT语句限制查询的条数:

三、WHERE语句
使用WHERE语句可以过滤不满足条件的数据:

3.1 比较运算符
以下是常用的比较运算符:
| 操作符 |
支持的数据类型 |
描述 |
| A=B |
基本数据类型 |
如果A等于B则返回TRUE,反之返回FALSE |
| A<=>B |
基本数据类型 |
如果A和B都为NULL,则返回TRUE,其他的和等号(=)操作符的结果一致,如果任一为NULL则结果为NULL |
| A<>B, A!=B |
基本数据类型 |
A或者B为NULL则返回NULL;如果A不等于B,则返回TRUE,反之返回FALSE |
| A |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于B,则返回TRUE,反之返回FALSE |
| A<=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A小于等于B,则返回TRUE,反之返回FALSE |
| A>B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于B,则返回TRUE,反之返回FALSE |
| A>=B |
基本数据类型 |
A或者B为NULL,则返回NULL;如果A大于等于B,则返回TRUE,反之返回FALSE |
| A [NOT] BETWEEN B AND C |
基本数据类型 |
如果A,B或者C任一为NULL,则结果为NULL。如果A的值大于等于B而且小于或等于C,则结果为TRUE,反之为FALSE。如果使用NOT关键字则可达到相反的效果。 |
| A IS NULL |
所有数据类型 |
如果A等于NULL,则返回TRUE,反之返回FALSE |
| A IS NOT NULL |
所有数据类型 |
如果A不等于NULL,则返回TRUE,反之返回FALSE |
| IN(数值1, 数值2) |
所有数据类型 |
使用 IN运算显示列表中的值 |
| A [NOT] LIKE B |
STRING 类型 |
B是一个SQL下的简单正则表达式,也叫通配符模式,如果A与其匹配的话,则返回TRUE;反之返回FALSE。B的表达式说明如下:‘x%’表示A必须以字母‘x’开头,‘%x’表示A必须以字母’x’结尾,而‘%x%’表示A包含有字母’x’,可以位于开头,结尾或者字符串中间。如果使用NOT关键字则可达到相反的效果。 |
| A RLIKE B, A REGEXP B |
STRING 类型 |
B是基于java的正则表达式,如果A与其匹配,则返回TRUE;反之返回FALSE。匹配使用的是JDK中的正则表达式接口实现的,因为正则也依据其中的规则。例如,正则表达式必须和整个字符串A相匹配,而不是只需与其字符串匹配。 |
3.2 逻辑运算符
WHERE语句中常用的逻辑运算符如下所示:
| 操作符 |
描述 |
| AND |
并 |
| OR |
或 |
| NOT |
否 |
四、分组函数
4.1 GROUP BY语句
GROUP BY语句通常会跟聚合函数一起使用,下面的例子统计了people表中所有不同性别的总人数:
select sex,count(*) from people group by sex;
4.2 HANING子句
HAVING子句只能用于GROUP BY子句之后,且与WHERE不同的是,HAVING后面可以使用分组函数。
select sex,count(*) sl from people group by sex having sex = 'm';
五、JOIN语句
JOIN语句代表多表关联,这里需要注意的是它只支持等值连接,不支持非等值连接。那我们再建一张favorite表的,表示用户的兴趣爱好。favorite表有三个字段,分别是id、姓名和兴趣。
create table if not exists favorite(
id string,
name string,
fav string
)
row format delimited fields terminated by ',';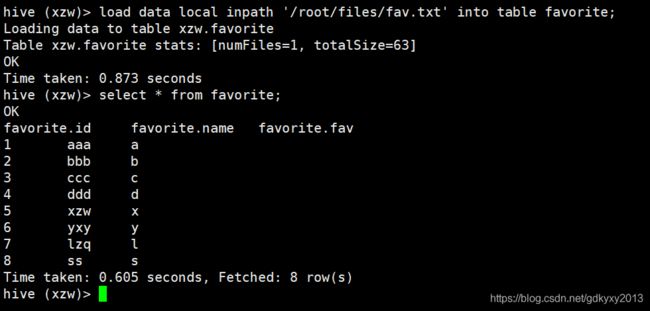
下面是一个JOIN的例子:
select p.name,p.sex,f.fav from people p join favorite f on p.name = f.name;
上例就是一个内连接的例子,内连接是指只有进行连接的两个表中都存在与连接条件相匹配的数据才会被保留下来。左外连接(LEFT JOIN)是指JOIN操作符左边表中符合WHERE子句的所有记录将会被返回。右外连接(RIGHT JOIN)是指JOIN操作符右边表中符合WHERE子句的所有记录将会被返回。满外连接(FULL JOIN)将会返回所有表中符合WHERE语句条件的所有记录。如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代。Hive会对每对JOIN连接对象启动一个MapReduce任务。
六、排序
6.1 Order by语句
使用Order by进行全局排序,它只有一个Reducer。默认是升序排序,即ASC(ascend)。也可以使用DESC(descend)指定为降序排列。
select * from people order by sex desc;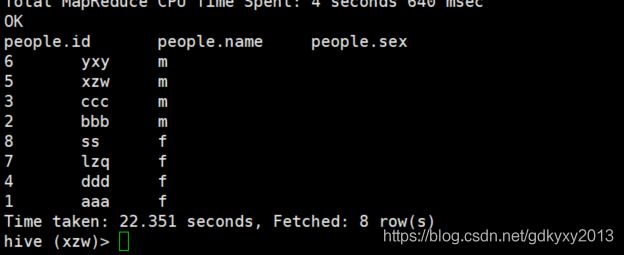
可以指定多个列排序:
select * from people order by sex,id desc;
6.2 Sort by语句
对于大规模的数据集来说order by的效率非常低。在很多情况下,并不需要全局排序,此时可以使用sort by进行排序。Sort by为每个reducer产生一个排序文件,每个Reducer内部进行排序,对全局结果集来说并不是有序的。下面来看一个例子:将people表中的数据根据id降序排序输出到文件中。
因为使用Sort by可能会有多个Reducer,可以使用如下语句在命令行指定Reducer的个数,此命令只对当前命令行有效。
set mapreduce.job.reduces=3 # 设置Reducer的个数为3insert overwrite local directory '/root/files/people.txt' select * from people sort by id desc;
6.3 Distribute By语句
在有些情况下,我们需要控制某个特定行应该到哪个reducer,通常是为了进行后续的聚集操作。分区排序(Distribute By)可以用来处理这种情况。分区排序类似MapReduce中的自定义分区,它结合sort by使用。对于distribute by进行测试,一定要分配多reduce进行处理,否则无法看到distribute by的效果。distribute by的分区规则是根据分区字段的hash码与reduce的个数进行模除后,余数相同的分到一个区。来看个例子:先按照性别分区,然后按照id降序输出。
set mapreduce.job.reduces=3;
select * from people distribute by sex sort by id desc;
6.4 Cluster By语句
当distribute by和sorts by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。例如,以下两种写法是等价的:
select * from people cluster by sex;
select * from people distribute by sex sort by sex;七、分桶查询
分区提供一个隔离数据和优化查询的便利方式。不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive可以进一步组织成桶,也就是更为细粒度的数据范围划分。分桶是将数据集分解成更容易管理的若干部分的另一个技术。分区针对的是数据的存储路径;分桶针对的是数据文件。下面来看一个分桶表的例子。
1、首先来构造测试数据,数据分为两列,一列是id,一列是name。如下所示:

2、创建分桶表,这里需要注意的是,在创建分桶表之前,需要设置强制分桶属性。属性设置如下:
set hive.enforce.bucketing=true;在建表之前需要注意的是,因为分桶表加载数据必须得走MapReduce,所以使用load的方式加载数据是不会进行分桶的,故得需要使用insert的方式加载其他表中的数据。建表语句如下:
1、普通表
create table stu(id int, name string) row format delimited fields terminated by ',';
2、分桶表
create table students(id int, name string) clustered by(id) into 4 buckets row format delimited fields terminated by ',';
3、加载数据
1、使用load的方式将构造的数据加载到stu普通表中
load data local inpath '/root/files/stu.txt' into table stu;
2、使用insert方式将stu中的数据加载到students中
insert into table students select id, name from stu;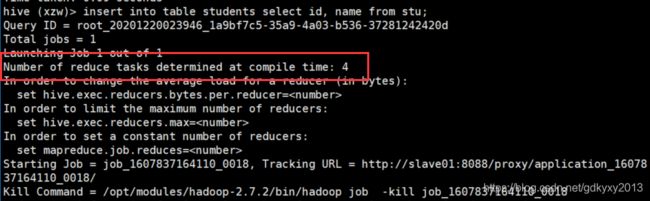
4、加载数据完成后查看监控界面,发现已经将数据分成了四个桶。
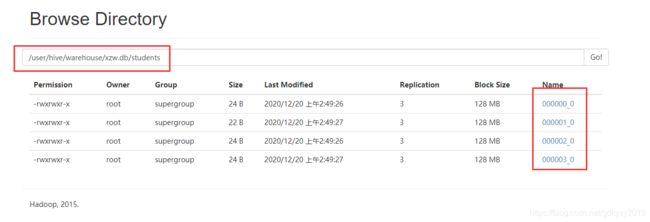
对于大数据量的数据集,有时候我们需要对其进行抽样查询,此时可以使用桶表来完成这个需求操作。其语法如下:
TABLESAMPLE(BUCKET x OUT OF y)其中,y必须是table总bucket数的倍数或者因子。Hive根据y的大小,决定抽样的比例。x表示从哪个bucket开始抽取,如果需要取多个分区,以后的分区号为当前分区号加上y。例如,table总bucket数为4,tablesample(bucket 1 out of 2),表示总共抽取(4/2=)2个bucket的数据,抽取第1(x)个和第3(x+y)个bucket的数据。这里必须注意的是x的值必须小于等于y的值。例如:
select * from students tablesample(bucket 1 out of 4 on id);
本文到这就接近尾声了,你们在此过程中遇到了什么问题,欢迎留言,让我看看你们都遇到了哪些问题~