triton inference server翻译之Model Configuration
link
Model Configuration
模型库中的每个模型都必须包括一个模型配置,该配置提供有关该模型的必需和可选信息。 通常,此配置在指定为ModelConfig protobuf的config.pbtxt文件中提供。 在某些情况下,如生成的模型配置中所述,模型配置可以由推理服务器自动生成,因此不需要显式提供。
最小的模型配置必须指定name, platform, max_batch_size, input, output。
示例:
name: "mymodel"
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "input0"
data_type: TYPE_FP32
dims: [ 16 ]
},
{
name: "input1"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
PyTorch命名约定:由于模型中没有输入和输出的名称,因此配置中输入和输出的“名称”属性都必须遵循特定的命名约定,即INPUT__0,INPUT__1和OUTPUT__0,OUTPUT__1,以使INPUT__0表示第一输入,INPUT__1表示第二输入。
模型的名称必须与包含模型的模型库目录的名称匹配。该平台必须是tensorrt_plan,tensorflow_graphdef,tensorflow_savedmodel,caffe2_netdef,onnxruntime_onnx,pytorch_libtorch或custom之一。
输入和输出张量允许的数据类型根据模型的类型而变化。参见
由dims指定的输入形状表示推理API期望的输入形状,dims指定的输出形状表示推理API返回的输出形状。输入和输出形状都必须满足rank >= 1,即,不允许使用空形状[]。如果基础框架模型或自定义后端要求输入或输出的形状为空,则必须使用reshape属性。
对于支持批量输入的模型,max_batch_size值必须大于等于1。Triton Inference Server假定批量沿着输入或输出中未列出的第一维进行。对于以上示例,服务器希望接收形状为[x,16]的输入张量,并生成形状为[x,16]的输出张量,其中x是请求的批处理大小。
对于不支持批量输入的模型,max_batch_size值必须为零。如果上面的示例将max_batch_size指定为零,则推理服务器将期望接收形状为[16]的输入张量,并会生成形状为[16]的输出张量。
对于支持尺寸可变的输入和输出张量的模型,这些尺寸可以在输入和输出配置中列为-1。例如,如果模型需要二维输入张量,其中第一维必须为大小4,而第二维可以为任意大小,则该输入的模型配置将包括dims:[4,-1]。然后,如果输入张量的第二维是任何值> = 0,则推理服务器将接受推理请求。模型配置的限制可能比基础模型所允许的限制更大。例如,即使模型允许第二维为任意大小,模型配置也可以特定为dims:[4,4]。在这种情况下,推理服务器将仅接受输入张量的形状正好为[4,4]的推理请求。
对于支持形状张量的模型,必须为输入适当设置is_shape_tensor,并为输出正确设置is_shape_tensor。考虑以下示例配置,以了解如何在批处理中使用形状张量:
name: "myshapetensormodel"
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "input0"
data_type: TYPE_FP32
dims: [ -1 ]
},
{
name: "input1"
data_type: TYPE_INT32
dims: [ 1 ]
is_shape_tensor: true
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ -1 ]
}
]
如前所述,Triton Inference Server假定沿第一维进行批处理,该维未在输入或输出张量暗中列出。 但是,对于形状张量,批量发生在第一个形状值处。 对于上面的示例,推理请求必须提供具有以下形状的输入:
"input0": [ x, -1]
"input1": [ 1 ]
"output0": [ x, -1]
其中x是请求的批量大小。 使用批处理时,服务器要求将形状张量标记为模型中的形状张量。 注意,input1具有形状[1]而不是[2]。 在发出建模请求之前,服务器将在input1处添加形状值x。
Generated Model Configuration
默认情况下,每个模型都必须提供包含所需设置的模型配置文件。但是,如果使用--strict-model-config = false选项启动服务器,则在某些情况下,推理服务器可以自动生成模型配置文件的所需部分。模型配置的必需部分是上面的示例最小配置中显示的那些设置。特别:
- TensorRT Plan模型不需要模型配置文件,因为推理服务器可以自动导出所有必需的设置。
- TensorFlow SavedModel模型不需要模型配置文件,因为推理服务器可以自动导出所有必需的设置。
- ONNX Runtime ONNX模型不需要模型配置文件,因为推理服务器可以自动导出所有必需的设置。但是,如果模型支持批处理,则所有输入和输出的初始批处理尺寸必须为可变大小。
- PyTorch TorchScript模型在模型配置文件中具有可选的输出配置,以支持存在可变数量和/或输出数据类型的情况。
使用--strict-model-config = false时,您可以看到使用状态API为模型生成的模型配置。
Triton Inference Server仅生成模型配置文件的必需部分。 如有必要,您仍必须提供模型配置的可选部分,例如version_policy, optimization, scheduling and batching, instance_group, default_model_filename, cc_model_filenames, tags。
提供分类模型时,请记住不能自动生成label_filename。 您将需要创建一个config.pbtxt文件,该文件指定所有必需的输出以及label_filename,或者直接在客户端代码中处理从模型输出到label的映射。
Datatypes
下表显示了Triton Inference Server支持的张量数据类型。 第一列显示在模型配置文件中显示的数据类型的名称。 其他列显示了服务器支持的模型框架和Python numpy库的相应数据类型。 如果模型框架没有给定数据类型的条目,则推理服务器不支持该模型的数据类型。
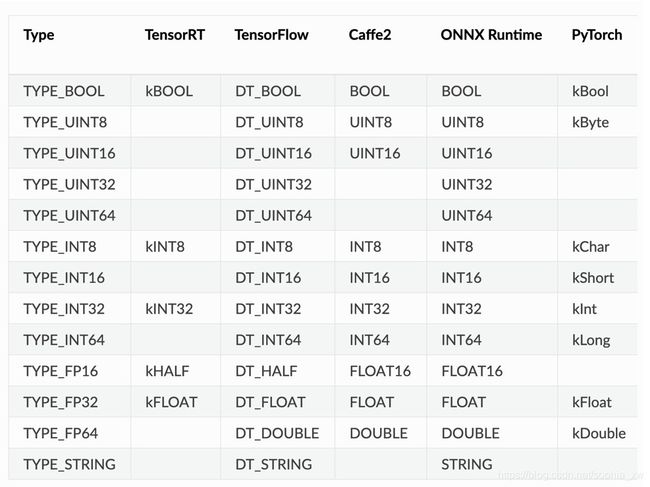

- TensorRT 参数类型在
nvinfer1::DataType命名空间。例如,nvinfer1::DataType::kFLOAT就是 32-bit floating-point。 - TensorFlow 参数类型在
tensorflow命名空间。例如,tensorflow::DT_FLOAT就是 32-bit floating-point。 - Caffe2 参数类型在
caffe2命名空间且带前缀TensorProto_DataType_。例如,caffe2::TensorProto_DataType_FLOAT就是 32-bit floating-point。 - ONNX Runtime 参数类型前缀
ONNX_TENSOR_ELEMENT_DATA_TYPE_。例如,ONNX_TENSOR_ELEMENT_DATA_TYPE_FLOAT就是 32-bit floating-point。 - PyTorch 参数类型在
torch命名空间。例如,torch::kFloat就是32-bit floating-point。 - Numpy参数类型在numpy模块。例如,
numpy.float32就是32-bit floating-point。
Reshape
模型配置输入或输出上的ModelTensorReshape属性用于标示推理API接受的输入或输出形状与基础框架模型或自定义后端预期或产生的输入或输出形状不同。
对于输入,可以使用reshape将输入张量reshape为框架或后端期望的其他形状。 一个常见的用例是支持批处理的模型期望批处理输入的形状为[batch-size],这意味着批处理尺寸完全描述了形状。 对于推理API,必须指定等效形状[batch-size,1],因为批次中的每个输入都必须指定非空形状。 对于这种情况,输入应指定为:
input [
{
name: "in"
dims: [ 1 ]
reshape: { shape: [ ] }
}
...
对于输出,可使用reshape将框架或后端产生的输出张量reshape为推理API返回的不同形状。 一个常见的用例是支持批处理的模型期望批处理的输出具有形状[batch-size],这意味着批处理尺寸完全描述了形状。 对于推理API,必须指定等效形状[batch-size,1],因为批次中的每个输出都必须指定非空形状。 对于这种情况,输出应指定为:
output [
{
name: "in"
dims: [ 1 ]
reshape: { shape: [ ] }
}
...
Version Policy
每个模型可以在模型仓库中有1个或多个版本,nvidia::inferenceserver::ModelVersionPolicy提供的版本策略是:
- All: 模型存储库中可用的所有模型版本均可用于推理。
- Latest: 仅可使用存储库中模型的最新
n版本进行推理。 该模型的最新版本是数字上最大的版本号。 - Specific: 仅模型的特定列出的版本可用于推理。
如果未指定版本策略,则将“最新”(num_version = 1)用作默认值,指示推理服务器仅提供模型的最新版本。 在所有情况下,从模型存储库中添加或删除版本子目录都可以更改在后续推理请求上的使用模型版本。
继续上面的示例,以下配置指定该模型的所有版本都可以从服务器获得:
name: "mymodel"
platform: "tensorrt_plan"
max_batch_size: 8
input [
{
name: "input0"
data_type: TYPE_FP32
dims: [ 16 ]
},
{
name: "input1"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
output [
{
name: "output0"
data_type: TYPE_FP32
dims: [ 16 ]
}
]
version_policy: { all { }}
Instance Groups
Triton Inference Server可以提供一个模型的多个执行实例,以便可以同时处理对该模型的多个同时推理请求。 模型配置ModelInstanceGroup用于指定应提供的执行实例数以及这些实例应使用的计算资源。
默认情况下,为系统中可用的每个GPU创建一个模型的执行实例。 instance-group设置可用于在每个GPU或仅某些GPU上放置模型的多个执行实例。 例如,以下配置会将模型的两个执行实例放置在每个系统GPU上:
instance_group [
{
count: 2
kind: KIND_GPU
}
]
以下配置会在GPU0上放1个实例,在GPU1和GPU2上放2个实例:
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
},
{
count: 2
kind: KIND_GPU
gpus: [ 1, 2 ]
}
]
模型实例同样可以配置在CPU上,模型除了可在GPU执行之外,也可在CPU执行。以下配置会将模型的两个执行实例放置在每个系统CPU上:
instance_group [
{
count: 2
kind: KIND_CPU
}
]
Scheduling And Batching
Triton Inference Server通过允许单个推理请求指定一批输入来支持批量推理。 批输入的推理是同时执行的,这对于GPU尤其重要,因为它可以大大提高推理吞吐量。 在许多用例中,各个推理请求没有进行批处理,因此,它们无法从批处理的吞吐量优势中受益。
推理服务器包含多种调度和批处理算法,这些算法支持许多不同的模型类型和用例。 有关模型类型和调度程序的更多信息,参见。
Default Scheduler
如果未指定schedule_choice配置,则将默认调度程序用于模型。 该调度程序将推理请求分配给为该模型配置的所有实例。
Dynamic Batcher
动态批处理是推理服务器的一项功能,它允许推理请求由服务器进行组合,以便动态创建批处理,从而使批量推理请求的吞吐量得到相同的提高。 动态批处理程序应用于无状态模型。 动态创建的批次将分发到为模型配置的所有实例。
使用模型配置中的ModelDynamicBatching设置,可以为每个模型独立启用和配置动态批处理。 这些设置控制动态创建的批次的首选大小,调度程序中可以延迟请求以允许其他请求加入动态批次的最大时间,以及队列属性,例如队列大小,优先级和超时 。
Preferred Batch Sizes
preferred_batch_size设置指示动态批处理程序应尝试创建的批处理大小。 例如,以下配置启用了动态批处理,首选批量大小为4和8。
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
}
当模型实例可用于推理时,动态批处理程序将尝试根据调度程序中可用的请求创建批处理。 按照收到请求的顺序将请求添加到批处理中。 如果动态批处理程序可以形成一个首选大小的批次,它将创建一个最大可能首选大小的批次并将其发送以进行推理。 如果动态批处理程序无法形成首选大小的批处理,它将发送最大可能的批处理,该批处理小于模型允许的最大批处理大小。
可以使用Count指标汇总检查生成的批次的大小,请参阅Metrics,推理服务器的详细日志记录可用于检查单个批次的大小。
Delayed Batching
可以将动态批处理程序配置为允许在调度程序中将请求延迟有限的时间,以允许其他请求加入动态批处理。 例如,以下配置将请求的最大延迟时间设置为100微秒:
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
max_queue_delay_microseconds: 100
}
当无法创建首选大小的批处理时,max_queue_delay_microseconds设置会更改动态批处理程序的行为。 当无法从可用请求中创建首选大小的批次时,只要没有延迟时间超过配置的max_queue_delay_microseconds设置,动态批次器就会延迟发送批次。 如果在此延迟期间收到新请求,并允许动态批处理程序形成具有首选批处理大小的批处理,则将立即发送该批处理以进行推断。 如果延迟到期,则动态批处理程序将按原样发送批处理,即使这不是首选大小。
Preserve Ordering
reserve_ordering设置用于强制所有响应以与接收请求相同的顺序返回。 有关详细信息,请参见protobuf文档。
Priority Levels
默认情况下,动态批处理程序维护一个队列,该队列保存模型的所有推理请求。 这些请求将按顺序进行处理和批处理。 priority_levels设置可用于在动态批处理程序中创建多个优先级,以便允许优先级较高的请求绕过优先级较低的请求。 相同优先级的请求将按顺序处理。 未设置优先级的推理请求使用default_priority_level进行调度。
Queue Policy
动态批处理程序提供了几种设置,用于控制如何将请求排队以进行批处理。
如果未定义priority_levels,则可以使用default_queue_policy设置单个队列的ModelQueuePolicy。
定义priority_levels时,每个优先级级别可以具有由default_queue_policy和priority_queue_policy指定的不同的ModelQueuePolicy。
ModelQueuePolicy允许使用 max_queue_size设置来设置最大队列大小。队列策略timeout_action,default_timeout_microseconds和allow_timeout_override设置允许配置队列,以便单个请求在队列中的时间超过指定的超时时被拒绝或推迟。
Sequence Batcher
与动态批处理程序类似,序列批处理程序结合了非批处理推断请求,因此可以动态创建批处理。 与动态批处理程序不同,序列批处理程序应用于有状态模型,在该状态模型中,推理请求序列必须路由到同一模型实例。 动态创建的批次将分发到为模型配置的所有实例。
使用模型配置中的ModelSequenceBatching设置,可以为每个模型独立启用和配置序列批处理。 这些设置控制序列超时以及配置推理服务器如何将控制信号发送到模型,指示序列开始,结束,准备就绪和相关性ID。 有关更多信息和示例,请参见模型和调度程序。
可以使用“Count”指标汇总检查生成的批次的大小,请参阅“Metrics”。 推理服务器的详细日志记录可用于检查单个批次的大小。
Ensemble Scheduler
集成调度程序必须用于集成模型,而不能用于任何其他类型的模型。
使用模型配置中的ModelEnsembleScheduling设置,可以为每个模型独立启用和配置集成调度程序。 这些设置描述了集成中包含的模型以及模型之间的张量值的流动。 有关更多信息和示例,请参见集成模型。
Optimization Policy
模型配置ModelOptimizationPolicy用于指定模型的优化和优先级设置。 这些设置控制后端框架是否/如何优化模型,以及推理服务器如何调度和执行模型。 有关当前可用的设置,请参阅protobuf文档。
TensorRT Optimization
TensorRT优化是一种特别强大的优化,可以为TensorFlow和ONNX模型启用。 为模型启用后,TensorRT优化将在加载时或首次接收推理请求时应用于模型。 TensorRT优化包括专门化和融合模型层,并使用降低的精度(例如16位浮点数)来显着提高吞吐量和延迟。
Model Warmup
对于某些框架后端,模型初始化可能会延迟到请求第一个推断之前,例如TF-TRT优化,这会导致客户端看到意外的延迟。 模型配置ModelWarmup用于指定模型的预热设置。 这些设置定义了一系列推理请求,推理服务器应创建这些推理请求以预热每个模型实例。 仅当模型实例成功完成请求时,才会提供模型实例。 请注意,预热模型的效果因框架后端而异,这将导致服务器对模型更新的响应较慢,因此用户应进行试验并选择适合其需求的配置。 有关当前可用的设置,请参阅protobuf文档。