Mysql数据库相关
1. SQL 的 select 语句完整的执行顺序
SQL Select 语句完整的执行顺序:
- from 子句组装来自不同数据源的数据;
- where 子句基于指定的条件对记录行进行筛选;
- group by 子句将数据划分为多个分组;
- 使用聚集函数进行计算;
- 使用 having 子句筛选分组;
- 计算所有的表达式;
- select 的字段;
- 使用 order by 对结果集进行排序。
SQL 语言不同于其他编程语言的最明显特征是处理代码的顺序。在大多数据库语言中,代码按编码顺序被处理。但在 SQL 语句中,第一个被处理的子句式 FROM,而不是第一出现的 SELECT。SQL 查询处理的步骤序号:
- FROM
JOIN - ON
- WHERE
- GROUP BY
- (6) WITH {CUBE | ROLLUP}
- HAVING
- SELECT
- DISTINCT
- ORDER BY
以上每个步骤都会产生一个虚拟表,该虚拟表被用作下一个步骤的输入。这些虚拟表对调用者(客户端应用程序或者外部查询)不可用。只有最后一步生成的表才会会给调用者。如果没有在查询中指定某一个子句,将跳过相应的步骤。
逻辑查询处理阶段简介:
- FROM:对 FROM 子句中的前两个表执行笛卡尔积(交叉联接),生成虚拟表 VT1。
- ON:对 VT1 应用 ON 筛选器,只有那些使为真才被插入到 TV2。
- OUTER (JOIN):如果指定了 OUTER JOIN(相对于 CROSS JOIN 或 INNER JOIN),保留表中未找到
匹配的行将作为外部行添加到 VT2,生成 TV3。如果 FROM 子句包含两个以上的表,则对上一个联接生成的
结果表和下一个表重复执行步骤 1 到步骤 3,直到处理完所有的表位置 - WHERE:对 TV3 应用 WHERE 筛选器,只有使为 true 的行才插入 TV4。
- GROUP BY:按 GROUP BY子句中的列列表对 TV4 中的行进行分组,生成 TV5
- CUTE|ROLLUP:把超组插入 VT5,生成 VT6。
- HAVING:对 VT6 应用 HAVING 筛选器,只有使为 true 的组插入到 VT7。
- SELECT:处理 SELECT 列表,产生 VT8。
- DISTINCT:将重复的行从 VT8 中删除,产品 VT9。
- ORDER BY:将 VT9 中的行按 ORDER BY 子句中的列列表顺序,生成一个游标(VC10)
- TOP:从 VC10 的开始处选择指定数量或比例的行,生成表 TV11,并返回给调用者。
2.SQL 之聚合函数
聚合函数是对一组值进行计算并返回单一的值的函数,它经常与 select 语句中的 group by 子句一同使用。
- avg():返回的是指定组中的平均值,空值被忽略。
- count():返回的是指定组中的项目个数。
- max():返回指定数据中的最大值。
- min():返回指定数据中的最小值。
- sum():返回指定数据的和,只能用于数字列,空值忽略。
- group by():对数据进行分组,对执行完 group by之后的组进行聚合函数的运算,计算每一组的值。
最后用having去掉不符合条件的组,having子句中的每一个元素必须出现在select列表中(只针对于mysql)
3. SQL 之连接查询(左连接和右连接的区别)
左连接(左外连接):以左表作为基准进行查询,左表数据会全部显示出来,右表如果和左表匹配的数据则显示相应字段的数据,如果不匹配则显示为 null。
右连接(右外连接):以右表作为基准进行查询,右表数据会全部显示出来,左表如果和右表匹配的数据则显示相应字段的数据,如果不匹配则显示为 null。
4. SQL 之 sql 注入
通过在 Web 表单中输入(恶意)SQL 语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行 SQL 语句。举例:当执行的 sql 为 select * from user where username = “admin”or “a”=“a”时,sql 语句恒成立,参数 admin 毫无意义。
防止 sql 注入的方式:
- 预编译语句:如,select * from user where username = ?,sql 语句语义不会发生改
变,sql 语句中变量用?表示,即使传递参数时为“admin or ‘a’= ‘a’”,也会把这整体当
做一个字符创去查询。 - Mybatis 框架中的 mapper 方式中的 # 也能很大程度的防止 sql 注入($无法防止 sql 注 入)。
5. Mysql 性能优化
- 当只要一行数据时使用 limit 1
查询时如果已知会得到一条数据,这种情况下加上 limit 1 会增加性能。因为 mysql 数据库引擎会在找到一条结果停止搜索,而不是继续查询下一条是否符合标准直到所有记录查询完毕。 - 选择正确的数据库引擎
Mysql 中有两个引擎 MyISAM 和 InnoDB,每个引擎有利有弊。
MyISAM 适用于一些大量查询的应用,但对于有大量写功能的应用不是很好。甚至你只需要update 一个字段整个表都会被锁起来。而别的进程就算是读操作也不行要等到当前 update 操作完成之后才能继续进行。另外,MyISAM 对于 select count(*)这类操作是超级快的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用会比 MyISAM 还慢,但是支持“行锁”,所以在写操作比较多的时候会比较优秀。并且,它支持很多的高级应用,例如:事物。 - 用 not exists 代替 not in。
Not exists 用到了连接能够发挥已经建立好的索引的作用,not in 不能使用索引。Not in 是最慢的方式要同每条记录比较,在数据量比较大的操作红不建议使用这种方式。 - 对操作符的优化,尽量不采用不利于索引的操作符。
如:in not in is null is not null <> 等某个字段总要拿来搜索,为其建立索引。Mysql 中可以利用 alter table 语句来为表中的字段添加索引,语法为:alter table 表明
add index (字段名);
6. 经典sql(学生表_课程表_成绩表_教师表)
添加链接描述
7. Mysql 事务
MySQL 和其它的数据库产品有一个很大的不同就是事务由存储引擎所决定,例如 MYISAM,MEMORY,ARCHIVE都不支持事务,事务就是为了解决一组查询要么全部执行成功,要么全部执行失败。
MySQL 事务默认是采取自动提交的模式,除非显示开始一个事务。
SHOW VARIABLES LIKE ‘AUTOCOMMIT’;

修改自动提交模式,0=OFF,1=ON
注意:修改自动提交对非事务类型的表是无效的,因为它们本身就没有提交和回滚的概念,还有一些命令是会强制自动提交的,比如 DLL 命令、lock tables 等。
SET AUTOCOMMIT=OFF 或 SET AUTOCOMMIT=0
7.1 事务的四大特征是什么
数据库事务 transanction 正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离性(Isolation)、持久性(Durability)。
- 原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执
行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。 - 一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
- 隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相 同的时间内,执行相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称 为串行化,为了防止事务操作间的混淆,必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
- 持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
7.2 Mysql 中四种隔离级别

读未提交(READ UNCOMMITTED):未提交读隔离级别也叫读脏,就是事务可以读取其它事务未提交的数据。
读已提交(READ COMMITTED):在其它数据库系统比如 SQL Server 默认的隔离级别就是提交读,已提交读隔离级别就是在事务未提交之前所做的修改其它事务是不可见的。
可重复读(REPEATABLE READ):保证同一个事务中的多次相同的查询的结果是一致的,比如一个事务一开始查询了一条记录然后过了几秒钟又执行了相同的查询,保证两次查询的结果是相同的,可重复读也是 mysql 的默认隔离级别。
可串行化(SERIALIZABLE):可串行化就是保证读取的范围内没有新的数据插入,比如事务第一次查询得到某个范围的数据,第二次查询也同样得到了相同范围的数据,中间没有新的数据插入到该范围中
8. MySQL 语句优化
8.1 where 子句中可以对字段进行 null 值判断吗?
可以,比如 select id from t where num is null 这样的 sql 也是可以的。但是最好不要给数据库留 NULL,尽可能的使用 NOT NULL 填充数据库。不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了,不管是否插入值(NULL 也包含在内),都是占用 100 个字符的空间的,如果是 varchar 这样的变长字段,null 不占用空间。可以在 num 上设置默认值 0,确保表中 num 列没有 null 值,然后这样查询:select id from t where num = 0。
8.2 select * from admin left join log on admin.admin_id = log.admin_id where log.admin_id>10 如何优化?
优化为: select * from (select * from admin where admin_id>10) T1 lef join log on T1.admin_id =
log.admin_id。使用 JOIN 时候,应该用小的结果驱动大的结果(left join 左边表结果尽量小如果有条件应该放到左边先处理,right join 同理反向),同时尽量把牵涉到多表联合的查询拆分多个 query(多个连表查询效率低,容易到之后锁表和阻塞)
8.3 limit 的基数比较大时使用 between
例如:select * from admin order by admin_id limit 100000,10
优化为:select * from admin where admin_id between 100000 and 100010 order by admin_id。
8.4 尽量避免在列上做运算,这样导致索引失效
例如:select * from admin where year(admin_time)>2014
优化为: select * from admin where admin_time> '2014-01-01′
9. MySQL 中文乱码问题完美解决方案
解决乱码的核心思想是统一编码。我们在使用 MySQL 建数据库和建表时应尽量使用统一的编码,强烈推荐的是 utf8 编码,因为该编码几乎可以兼容世界上所有的字符。
数据库在安装的时候可以设置默认编码,在安装时就一定要设置为 utf8 编码。设置之后再创建的数据库和表如果不指定编码,默认都会使用 utf8 编码,省去了很多麻烦。
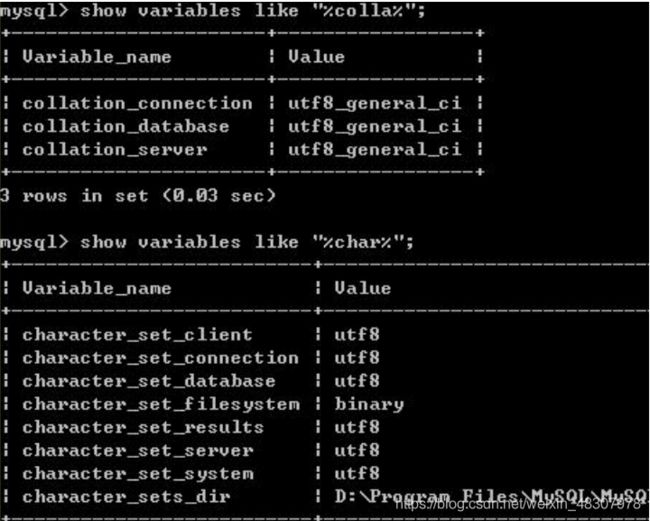
数据库软件安装好之后可以通过如下命令查看默认编码:
1. 查询数据库软件使用的默认编码格式
show variables like “%colla%”;
show varables like “%char%”
其中 collation,代表了字符串排序(比较)的规则,如果值是 utf8_general_ci,代表使用 utf8 字符集大小写不敏感的自然方式比较。
如果 character_set 的值不为 utf8,那么可以使用如下命令修改为 utf8。
2. 修改数据库默认编码为 utf8
SET character_set_client=‘utf8’;
SET character_set_connection=‘utf8’;
SET character_set_results=‘utf8’;
如果不想设置数据库软件的全局默认编码,也可以单独修改或者设置某个具体数据库的编码也可以单独修改 或设置某个数据库中某个表的编码。
3. 创建数据库的时候指定使用 utf8 编码
CREATE DATABASE
test
CHARACTER SET ‘utf8’
COLLATE ‘utf8_general_ci’;
4、创建表的时候指定使用 utf8 编码
CREATE TABLE
database_user(
IDvarchar(40) NOT NULL default ‘’,
UserIDvarchar(40) NOT NULL default ‘’,
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如果数据库已经创建好了,可以使用 show database 数据库名;和 show create table 表名;查看一下数 据库和表的字符集是否为 utf8 ,如果不是则在命令行下面可以用如下命令,将数据库和表编码修改为 utf8.
5、修改具体某数据库或表的编码
ALTER DATABASE
db_nameDEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLEtb_nameDEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;