数据结构与算法学习④(哈夫曼树 图 分治回溯和递归)
数据结构与算法学习④(哈夫曼树 图 回溯和递归
- 数据结构与算法学习④
-
- 1、哈夫曼树
-
- 1.1、相关概念
- 1.2、哈夫曼树的构建
- 1.3、哈夫曼编码
- 1.4、面试题
- 2、图
-
- 2.1、图的相关概念
- 2.2、图的表示和存储
-
- 2.2.1、邻接矩阵表示法
- 2.2.2、邻接表表示法
- 2.3、图的应用
- 2.4、面试题
- 分治和回溯
-
- 1、递归
-
- 111. 二叉树的最小深度
- 236. 二叉树的最近公共祖先
- 2、算法思想-分治,回溯
-
- 2.1、分治
- 2.2、回溯
- 3、面试实战
-
- 50. Pow(x, n)
- 46. 全排列
- 回溯面试题
-
- 47. 全排列 II
- 78. 子集
- 90. 子集 II
- 77. 组合
- 17. 电话号码的字母组合
- 51. N 皇后
- 169. 多数元素
数据结构与算法学习④
1、哈夫曼树
1.1、相关概念
路径:
在一棵树中,从一个结点到另一个结点所经过的所有结点,被我们称为两个结点之间的路径。
路径长度:
在一棵树中,从一个结点到另一个结点所经过的“边”的数量,被我们称为两个结点之间的路径长度。
节点的权值:
树的每一个结点,都可以拥有自己的“权重”(Weight),其实就是对节点赋予的一个有意义的值,比如:访问的频率,出现的次数,概率等等!
带权路径长度:
结点的带权路径长度,是指树的根结点到该结点的路径长度,和该结点权重的乘积。
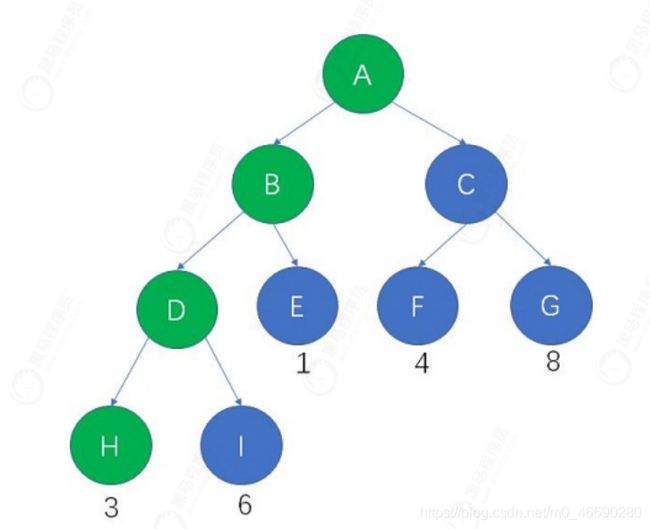
假设:H节点的权值是3,从根节点到该节点的路径长度也是3,则带权路径长度为:3 x 3 = 9
树的带权路径长度:
在一棵树中,所有叶子结点的带权路径长度之和,被称为树的带权路径长度,也被简称为WPL。

则该树的带权路径长度WPL=3X3 + 6X3 + 1X2 + 4X2 + 8X2 = 53。

其中Wk 表示节点k的权值,Lk表示从根节点到节点k的路径长度
哈夫曼树:
给定一组具有确定权值的叶子节点,树的带权路径长度(wpl)最小的二叉树。也称最优二叉树。
比如:给定4个叶子节点,其权值分别为{2,3,4,7},可以构造出的多个形状不同的二叉树如下:

哈夫曼树的特点:
特点1:权值越大的叶子节点越靠近根节点,权值越小的叶子节点越远离根节点。
特点2:只有度为0和度为2的节点,不存在度为1的节点。
如果给定n个带权值的叶子节点,则哈夫曼树的节点数为:2n-1个
解释:
不存在度为1的节点即n1=0,由二叉树的性质,n0=n2 + 1,所以:n2 = n0 -1,现在n0=n,所以n2= n-1,所以二叉树的节点数为:n0+n1+n2 = n + 0 + n-1 = 2n-1;也意味着,如果用线性数组来存储哈夫曼树,给定n个带权值的叶子节点,线性数组的大小应为:2n-1。
1.2、哈夫曼树的构建
(1)**初始化:**由给定的n个权值集合{w1,w2,w3,…wn }构造n棵二叉树(只有根节点),从而得到了一个二叉树集合T={T1,T2,T3,…Tn }。
(2)选区与合并:从集合T中选取根节点权值最小的两棵二叉树分别作为左子树和右子树构造一棵新的二叉树,并且根节点的权值为左右子节点的权值之和。
(3)删除与加入:从集合T中删除刚刚作为左右子节点的二叉树,并将他们新合并的二叉树添加到集合T中
(4)**重复(2)(3)**直到变成一棵二叉树

1.3、哈夫曼编码
哈夫曼树主要是为了哈夫曼编码,这种编码方式应用场景很广,最常见的就是用于文件压缩(zip,jpg底层都采用的一种编码方式)
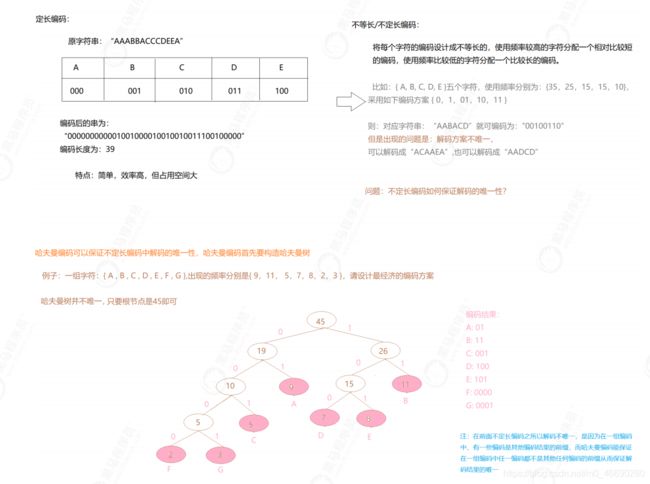
1.4、面试题
题目1:快手2020秋招
由权值分别为{3,8,6,2,5}的叶子结点生成一棵哈夫曼树,它的带权路径长度为
A: 24
B: 48
C: 52
D: 53
解析:按照哈夫曼树的构建过程构建然后计算即可,结果为53

题目2:小米-华为-秋招
下面关于哈夫曼树的描述中,错误的是
A: 哈夫曼树一定是完全二叉树
B: 哈夫曼树一定是平衡二叉树
C: 哈夫曼树中权值最小的两个节点互为兄弟节点
D: 哈夫曼树中左孩子节点小于父节点,右孩子节点大于父节点
题解:根据哈夫曼树的定义可知答案为:ABD
2、图
在前面的章节中我们学习了树这种非线性表数据结构,那么在本章节中我们要讲另一种非线性表数据结构图。
2.1、图的相关概念
图(Graph):
图和树比起来,这是一种更加复杂的非线性表结构,直接说图的定义不是很好理解,那我们直接看下方图示:
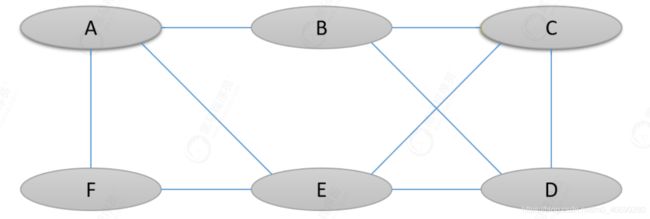
以前学习树的时候,树中的元素我们称之为节点Node,现在在图中的每一个元素我们称之为顶点(Vertex),并且图中的一个顶点可以与其他任意顶点建立连接关系,我们把这种建立的关系叫做边(Edge),或者叫弧,图可以表示为:G = (V,E),其中V是顶点的集合,E是边的集合。
其实生活中就有与这类似的结构:社交网络就是一个非常典型的图的结构,比如微信,qq,微博,每个人都有好友,拿微信来说:
把每个用户看作一个顶点。如果两个用户之间互加好友,那就在两者之间建立一条边。所以,整个微信的好友关系就可以用一张图来表示
顶点的度(degree):
在图中跟顶点相连接的边的条数叫做顶点的度。
无向图(Undirected Graph)和有向图(Directed Graph):
刚刚所说的图属于“无向图”,边没有方向,如果给边引入“方向”,就成为有向图。

举例:抖音用户之间可以互相关注,也可以单向关注!
入度和出度:
在无向图中,顶点有度的概念,代表每个顶点边的个数,在有向图中把度分为“入度”和“出度”
顶点的入度,表示有多少条边指向这个顶点;顶点的出度,表示有多少条边是以这个顶点为起点指向其他顶点。
举例:对应到抖音用户,入度就表示有多少粉丝,出度就表示关注了多少人
权重图(Weighted Graph)/网:
在图中,每条边都有自己的权重(出现频率,访问次数等等有意义的值),这样的图称为权重图,带权的图我们称之为网。

举例:qq的社交关系中不仅记录了用户直接的好友关系,还记录了两个用户之间的亲密度,如果两个用户经常往来,那亲密度就比较高;如果不经常往来,亲密度就比较低;我们可以通过这个权重来表示 QQ 好友间的亲密度。
路径,路径长度,回路:
路径:接续的边构成的顶点序列。
路径长度:路径上边的个数/边的权值 之和。
回路:第一个顶点和最后一个顶点相同的路径。
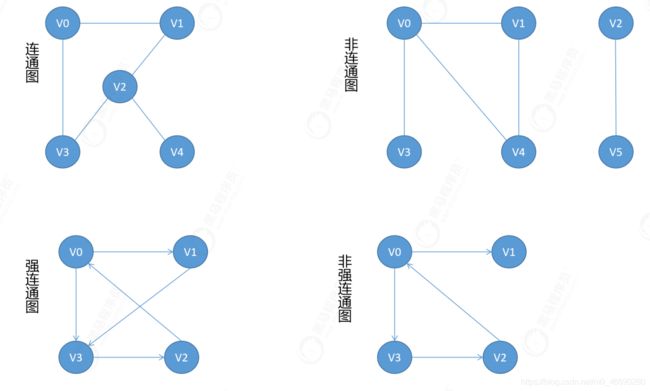
连通图,强连通图:
连通图:在无向图中,若任意两个顶点v,u之间都存在从v到u的路径,则称该图是连通图。
强连通图:在有向图中,若任意两个顶点v,u之间都存在从v到u的路径,则称该图是强连通图。
子图:
设有两个图 G1= (V1,E1),G2=(V2,E2),若V1包含于V2 (V1是V2的子集), E1 包含于E2(E1是E2的子集),则称G1是G2的子图。

连通分量,强连通分量:
**极大连通子图:**首先该子图是图G一个连通子图,另外如果将图G中任意一个不在该子图中的顶点加入到该子图中,该子图不再连通。
**连通分量:**在无向图G中的极大连通子图称为G的连通分量。

而对于强连通分量指的就是在有向图G中,它的极大强连通子图称为G的强连通分量。
极大强连通子图:图G的一个强连通子图,如果将图G中任何一个不在该子图中的顶点加入该子图中,该子图不再连通,则说明该子图是图G的极大强连通子图。
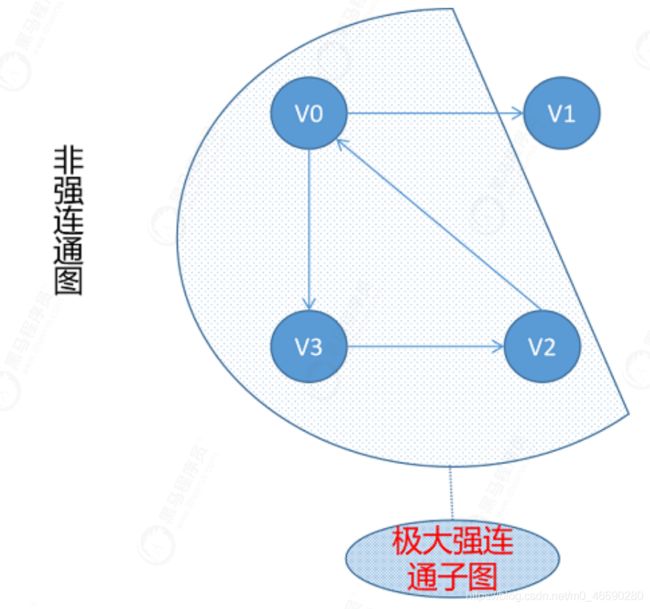
这里还有另一个概念:极小连通子图
极小连通子图:一个图G的连通子图,在该子图中删除任何一条边后该子图都不再连通,则称该子图是图G的极小连通子图。
生成树:
包含无向图G所有顶点的极小连通子图叫图G的生成树

2.2、图的表示和存储
理解了图的概念之后,那我们想如何在内存中存储一个图呢?其实图有很多中存储形式包括:邻接矩阵,邻接表,十字链表,邻接多重表,边集数组等等,在今天的课程中我们主要讲解其中的两种存储:邻接矩阵和邻接表
2.2.1、邻接矩阵表示法
邻接矩阵存储图底层依赖一个二维数组。
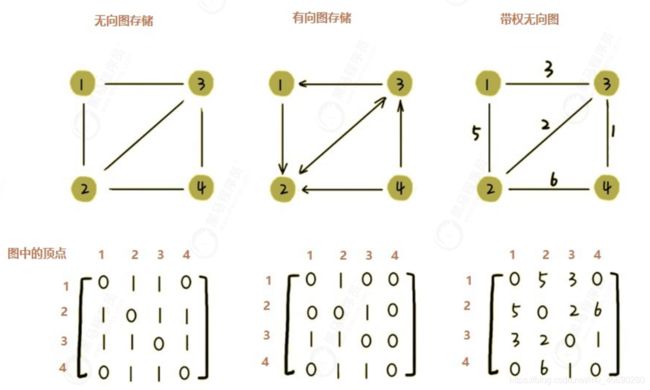
1:对于无向图来说,如果顶点 i 与顶点 j 之间有边,我们就将 A[i][j] 和 A[j][i] 标记为 1;
2:对于有向图来说,如果顶点 i 到顶点 j 之间,有一条箭头从顶点 i 指向顶点 j 的边,那我们就将 A[i] [j] 标记为1。同理,如果有一条箭头从顶点 j 指向顶点 i 的边,我们就将 A[j][i] 标记为 1。 3:对于带权图,数组中就存储相应的权重。使用邻接矩阵来存储图的特点是:简单,直观。但是也有一定的缺点就是浪费存储空间。
比如以上第一种无向图的存储, A[i][j] 等于1那么 A[j][i] 也等于1,在那个二维数组中我们沿着对角线划分为上下两部分,两部分其实是对称的,其实我们只需要一半的存储空间就够了,另一半算是浪费了。
面试题1:华为2019
1 将10阶对称矩阵压缩存储到一维数组中,则数组A的长度最少为()
A:100
B:40
C:55
D:80
解析:C n阶对称矩阵下三角元素个数,n * (n+1)/2
面试题2:美团点评2019
已知存在8阶对称矩阵,采用压缩存储方式按行序为主序存储,每个元素占一个地址空间。若a22为元素的存储 地址为1,每个元素占一个地址空间,则a74的地址为
A:11
B:23
C:32
D:33
解析:n阶对称矩阵,采用压缩存储方式按行序为主序存储,存储其下三角即可。 8阶对称矩阵压缩存储需要的存储长度为:8 * (8+1) /2 = 36。 a22的地址为1,每个元素占一个地址,因此最后一个地址是35,a74一直到最后还有12个存储空间,因此a74的 地址是:35-12=23.

面试题3:哈罗
图的邻接矩阵表示法适用于什么图
A:稀疏图
B:稠密图
C:有向图
D:无向图
题解:数据多的用邻接矩阵算法算的快,数据少的用邻接表算法算的快. 稠密图数据多, 选B
因此邻接矩阵适用场景:使用于稠密的图,可以快速定位到指定的边,但是如果是稀疏的图,会比较浪费空间。
2.2.2、邻接表表示法
针对上面邻接矩阵比较浪费内存空间的问题,我们来看另外一种图的存储方法,邻接表(Adjacency List)。
下面用一幅图示来描述一下邻接表存储图
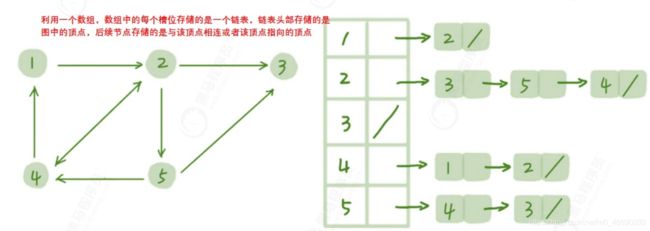
乍一看邻接表是不是有点像散列表?
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。另外图中画的是一个有向图的
邻接表存储方式,每个顶点对应的链表里面,存储的是指向的顶点。
对于无向图来说,也是类似的,不过,每个顶点的链表中存储的,是跟这个顶点有边相连的顶点。
总结:
使用邻接矩阵存储图的好处是直观简单方便,但是缺点是浪费存储空间,相反的邻接表存储图的好处就是比较节省存储空间,但是缺点就是时间成本较高。
就像图中的例子,如果我们要确定,是否存在一条从顶点 2 到顶点 4 的边,那我们就要遍历顶点 2对应的那条链表,看链表中是否存在顶点 4。
当然这里也可以进行优化,因为如果链表拉的过长,整个查找效率会低下,我们也可以借鉴一些优秀底层的思想,比如:java语言中HashMap,底层基于散列表,散列表每个槽位如果有冲突的话会形成一个链表,为了防止链表过大查找时间过长,会将链表转换成其他查找性能更高的数据结构,如红黑树,平衡二叉树等等。
我们可以将邻接表中的链表改成查找性能更高的数据结构。实际开发中,我们可以选择用红黑树。这样,我们就可以更加快速地查找两个顶点之间是否存在边了。当然,这里的二叉查找树可以换成其他动态数据结构,比如跳表、散列表等。除此之外,我们还可以将链表改成有序动态数组,可以通过二分查找的方法来快速定位两个顶点之间否是存在边。
2.3、图的应用
1、最小生成树
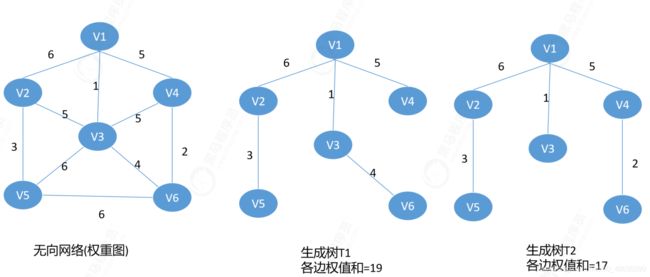
给定一个无向网络,在该网络的所有生成树中,使得各边权值之和最小的树称为该网的最小生成树,也叫最小代价生成树。
最小生成树的各边权值之和是唯一的。
应用举例:
欲在n个城市之间建立通信道路,但是两两城市之间的道路建设经济成本不太一样,那如何选择道路会使得总费用最少呢?
数学模型: 顶点----------------表示城市,有n个
边------------------表示城市间的道路,最少需要(n-1)条道路
边的权值-------------建设道路的经济代价
连通网---------------表示n个城市之间的道路通信网
对应的最小生成树就是能使总费用最少的道路建设方案。
https://www.bilibili.com/video/av84820276?from=search&seid=17476598104352152051
2、最短路径:
典型应用:交通网络问题,譬如
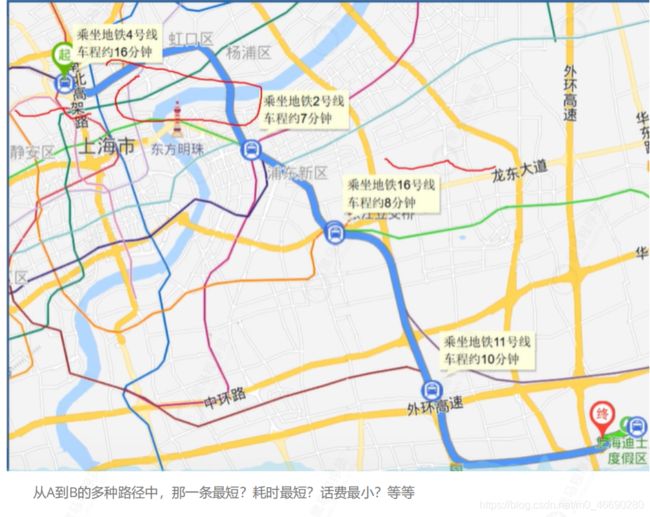
从A到B的多种路径中,那一条最短?耗时最短?话费最小?等等
对于这种交通网络,如果我们用有向图来表示的话:
顶点:表示各个地点。
边(弧):表示从一个顶点到另一个顶点的通路。
边的权值:两个顶点之间的距离,交通费,或图中花费的时间等等。
求一个地点到另一个地点的时间最短,运费最省等这类问题我们叫做两顶点间的最短路径问题。
抽象一下就是:
在一个有向网中从起点A到终点B的多条路径中,寻找一条各边权值之和最小的路径,即最短路径。
注意:最短路径和最小生成树是不一样的,最小生成树是一定要包含n个顶点(n-1条边)且各边权值之
和最小。而最短路径中不一定包含n个顶点,也不一定包含n-1条边。
最短路径又可分为两类:
第一类:两点间的最短路径

第二类:某源点到其他各顶点的最端路径

https://www.bilibili.com/video/av25829980?from=search&seid=13391343514095937158
3、拓扑排序:
拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
1、每个顶点出现且只出现一次。
2、若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。 有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
通常,一个有向无环图可以有一个或多个拓扑排序序列。
参考:https://zhuanlan.zhihu.com/p/34871092
2.4、面试题
题目1:华为2019
判断:不含回路的有向图一定存在拓扑排序 ()
A: true
B: false
题解:根据拓扑排序的定义,有向无环图才有拓扑排序。
题目2:美团点评2020
下列说法正确的是( )
A:图中存在有向环时,不存在拓扑排序
B:DAG上可以借助DFS完成拓扑排序
C:DAG上任意两点有确定的优先顺序,在此DAG上的拓扑排序有唯一解
D:全错
题解:AB很好理解,对于C,如果DAG上任意两点都有确定的优先顺序则表明入度为0的顶点只有一个,,拓扑排序可能存在多个的原因是每次查找入度为0的顶点可能不止一个,我们是随机选取的一个来操作,这样排序的结果就有多种。所以正确答案是ABC。
题目3:小米2019
假设一个无向图中包含12个顶点,其中5个顶点有5个度,7个顶点有7个度,那么这个图有几条边?
A:12
B:25
C:37
D:49
E:60
题解:对于有向图,度分入度和出度,分别代表指向自己的边数量和指向别人的边数量;那么对于无向图来说,顶点的度表述图中跟顶点相连接的边的条数。所以对于无向图来说要注意:一条边它会带来两个度,因此边的条数为度的一半。所以(55+77)/2=37
分治和回溯
1、递归
111. 二叉树的最小深度
https://leetcode-cn.com/problems/minimum-depth-of-binary-tree/submissions/

递归解法
public int minDepth(TreeNode root) {
if(root==null){
return 0;
}
//左孩子和右孩子都为空的情况说明找到了,直接返回1
if(root.left==null&&root.right==null){
return 1;
}
//如果左孩子为空,去找右
if(root.left==null){
return minDepth(root.right)+1;
}
if(root.right==null){
return minDepth(root.left)+1;
}
//找最小的,递归往下找并加1
return Math.min(minDepth(root.left),minDepth(root.right))+1;
}
非递归解法:广度优先搜索BFS
public int minDepth(TreeNode root) {
//特殊判断
if(root==null){
return 0;
}
int pathLevel=1;
//bfs需要借助队列(dfs借助递归)
Queue<TreeNode>queue=new LinkedList();
queue.offer(root);
while(!queue.isEmpty()){
int size=queue.size();
for(int i=0;i<size;i++){
//一层一层的递归
TreeNode poll=queue.poll();
if(poll.left==null&&poll.right==null){
return pathLevel;
}
if(poll.left!=null){
queue.offer(poll.left);
}
if(poll.right!=null){
queue.offer(poll.right);
}
}
pathLevel++;
}
return pathLevel;
}
236. 二叉树的最近公共祖先
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/

精选题解
https://leetcode-cn.com/problems/lowest-common-ancestor-of-a-binary-tree/solution/236-er-cha-shu-de-zui-jin-gong-gong-zu-xian-jian-j/
//p,q这个条件是公共父节点的情况,比如2和4这种,找4就可以了
if(root==null||root==p||root==q){
return root;
}
//分别在左右子树中查最近父节点
TreeNode lefttp=lowestCommonAncestor(root.left,p,q);
TreeNode righttp=lowestCommonAncestor(root.right,p,q);
//如果左子树最近公共父节点,那肯定在右子树上
if(lefttp==null){
return righttp;
}
if(righttp==null){
return lefttp;
}
//如果左右子树中都没有找到最近公共父节点,证明p和q一个在左子树,一个在右子树,那当前节点,就是左右子树的父节点就为最近公共父节点
return root;
}
2、算法思想-分治,回溯
前言:
分治和回溯,从本质上来讲它算一种递归,只不过他是属于递归的一个细分类,所以我们可以任务分治回溯就是一种特殊的递归或者复杂度的递归。
因此考虑这种问题有一个要点:找重复性(重复子问题).
2.1、分治
分治算法在维基百科上的定义为:在计算机科学中,分治法是建基于多项分支递归的一种很重要的算法范式。字面上的解释是**“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并**。
通过维基百科的定义我们可以发现分治算法的核心就是分而治之,当然这个定义和递归有点类似,这里我们要说一下分治和递归的区别:分治算法是一种处理问题的思想,递归是一种编程技巧,当然了在实际情况中,分治算法大都采用递归来实现。
并且用递归实现分治算法的基本步骤为:
1:分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
2:解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
3:合并:将各个子问题的解合并为原问题的解。
什么样的问题适合用分治算法去解决呢?
- 原问题与分解成的小问题具有相同的模式;
- 原问题分解成的子问题可以独立求解,子问题之间没有相关性,这一点是分治算法跟动态规划的
明显区别,至于动态规划下一小节会详细讲解并对比这两种算法; - 具有分解终止条件,也就是说,当问题足够小时,可以直接求解;
- 可以将子问题合并成原问题,并且合并操作的复杂度不能太高,否则就起不到减小算法总体复
杂度的效果了,这也是能否使用分治法的关键特征
分治算法应用场景举例:
排序:后期要讲的很多排序算法有很多就利用了分治的思想,比如归并排序,快速排序。
海量数据处理:分治算法思想还经常用在海量数据处理的场景中。比如:给 10GB 的订单文件按照金额排序这样一个需求,看似是一个简单的排序问题,但是因为数据量大,有 10GB,而我们的机器的内存可能只有 2、3GB,总之就是小于订单文件的大小因而无法一次性加载到内存,所以基础的排序算法在这样的场景下无法使用。
要解决这种数据量大到内存装不下的问题,我们就可以利用分治的思想。我们可以将海量的数据集合根
据某种方法,划分为几个小的数据集合,每个小的数据集合单独加载到内存来解决,然后再将小数据集合合
并成大数据集合。实际上,利用这种分治的处理思路,不仅仅能克服内存的限制,还能利用多线程或者多机
处理,加快处理的速度。
假设现在要给 10GB 的订单排序,我们就可以先扫描一遍订单,根据订单的金额,将10GB 的文件划分
为几个金额区间。比如订单金额为 1 到 100 元的放到一个小文件,101 到 200 之间的放到另一个文件,以此
类推。这样每个小文件都可以单独加载到内存排序,最后将这些有序的小文件合并,就是最终有序的 10GB
订单数据了。如果订单数据存储在类似 GFS 这样的分布式系统上,当 10GB 的订单被划分成多个小文件的时候,每个文件可以并行加载到多台机器上处理,最后再将结果合并在一起,这样并行处理的速度也加快了很多。
分治代码模板:
private static int divide_conquer(Problem problem, ) {
//问题终止条件
if (problem == NULL) {
//处理最小子问题的解
int res = process_last_result();
return res;
}
//将问题拆分成一个一个的重复子问题。
subProblems = split_problem(problem)
//下探到下一层求解子问题
res0 = divide_conquer(subProblems[0])
res1 = divide_conquer(subProblems[1])
//将子问题的结合并变成最终问题的解
result = process_result(res0, res1);
//清楚当前层状态等其他信息
return result;
2.2、回溯
04年上映的《蝴蝶效应》,影片中讲述的是主人公为了实现自己的目标一直通过回退的方法回到童年,在一些重要的人生岔路口重新做出选择,最终实现整个美好人生的故事,当然了这只是电影,现实中人生是无法倒退的,但是这其中蕴含的就是思想就是我们要讲的回溯思想。
回溯算法实际上是一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求
解条件时,就“回溯”返回,尝试别的路径。回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的思想为回溯。
回溯法采用试错的思想,尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确答案时,它将取消上一步甚至上几步的计算(回退),再通过其他的可能的分步解答再次尝试寻找问题的解。
回溯法通常用最简单的递归方法来实现,在反复重复上面所讲的步骤后可能会出现以下两种情况:
1:找到了一个可能存在的正确答案
2:在尝试了所有可能的分步方法后宣告没有答案
在最坏情况下,回溯法会导致一次复杂度为指数时间的计算。
回溯算法是一种遍历算法,以 深度优先遍历 的方式尝试所有的可能性。有些教程上也叫「暴力搜索」。回溯算法是 有方向地 搜索,区别于多层循环实现的暴力法。
3、面试实战
50. Pow(x, n)
https://leetcode-cn.com/problems/powx-n/

朴素解法
public double myPow(double x, int n) {
double res=1.0;
int count=n>0?n:-n;
for(int i=0;i<count;i++){
res=res*x;
}
return n>0?res:1/res;
}
时间复杂度:O (n)
分治思想: x^n = x^(n/2) * x^ (n/2)
public double myPow(double x, int n) {
if(n<0){
return 1/recurPow(x,-n);
}else{
return recurPow(x,n);
}
}
public double recurPow(double x,int n){
//最小的子问题,终止条件
if(n==0){
return 1.0;
}
if(n==1){
return x;
}
//处理当前层逻辑,下探到下一层
//大问题分解为小的子问题
double subRes=recurPow(x,n/2);
//合并子问题的解
if(n%2==0){
return subRes*subRes;
}else{
return subRes*subRes*x;
}
}
扩展题目 69. x 的平方根
https://leetcode-cn.com/problems/sqrtx/

赖皮解法
public int mySqrt(int x) {
return (int)Math.sqrt(x);
}
小机灵鬼解法
public int mySqrt(int x) {
if(x==0) return 0;
if(x>0){
return(int) Math.pow(x,0.5);
}
return -1;
}
牛顿迭代法:http://www.matrix67.com/blog/archives/361
牛顿迭代法代码:http://www.voidcn.com/article/p-eudisdmk-zm.html
46. 全排列
https://leetcode-cn.com/problems/permutations/
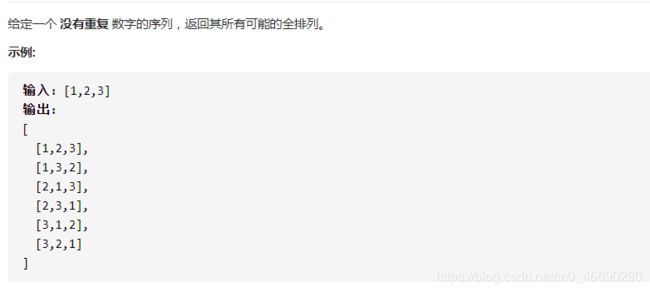
我们在高中的时候就做过排列组合的数学题,我们也知道 n 个不重复的数,全排列共有 n! 个。
那么我们当时是怎么穷举全排列的呢?
比方说给三个数 [1,2,3] ,你肯定不会无规律地乱穷举,一般是这样:
1:固定第一位为 1,然后第二位可以是 2,那么第三位只能是 3;然后可以把第二位变成 3,第三位就只能是 2 了;
2:固定第一位为2,然后再穷举后两位……
3:固定第一位为3,然后再穷举后两位……
其实这就是回溯算法。
我们把刚刚穷举的过程画下来,会发现是一棵树

只要从根遍历这棵树,记录路径上的数字,其实就是所有的全排列结果。
我们把这棵树称为回溯算法的:决策树(递归状态树)
为什么说这是决策树呢,因为你在每个节点上其实都在做决策。比如说你站在下图的红色节点上:
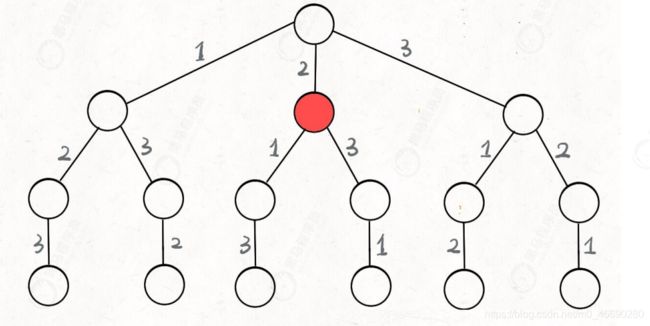
现在就需要做决策,可以选择 1 那条树枝,也可以选择 3 那条树枝。不选2的原因是因为 2 这个树枝在之前已经选择过了,而全排列是不允许重复使用的。
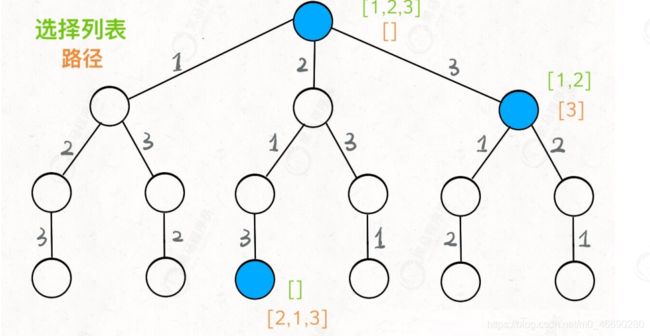
解决一个回溯问题,实际上就是一个决策树的遍历过程。只需要思考 3 个问题:
1、路径:用于记录我们已经做出的选择,走过的节点等等,比如 [2] 。
2、选择列表:表示当前可以做的选择,比如 [1,3]
3、结束条件:也就是到达决策树底层,无法再做选择的条件。就是遍历到树的底层,在这里就是选择列表为空的时候(终止条件)
把路径和选择列表作为决策树上每个节点的属性,比如下图列出了几个节点的属性:
回溯算法的代码框架如下:
result = []
def backtrack(路径, 选择列表):
if 满足结束条件:
result.add(路径)
return;
for 选择 in 选择列表:
// 做选择
在选择列表中做出一个选择
路径.add(选择)
// 下探到下一层
backtrack(路径, 选择列表)
// 撤销选择
路径.remove(选择)
将该选择再加入选择列表
其核心就是 for 循环里面的递归,在递归调用之前「做选择」,在递归调用之后「撤销选择」。

下面我们来实现46,全排列代码
回溯+剪枝
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>>res=new ArrayList();
//记录走过的路径
Deque<Integer>path=new ArrayDeque();
//记录是否已经选择过了,因为回溯要会到过去重新选择,必须要知道之前已经选择过哪些,因为可能重新选择的路径是之前已经选择过的,因此用一个boolean数组来进行剪枝,减少一些操作
boolean[]visted=new boolean[nums.length];
backTrack(nums,1,path,visted,res);
return res;
}
public void backTrack(int[]nums,int level,Deque<Integer>path,boolean[]visted,List<List<Integer>>res){
//终止条件
if(level>nums.length){
res.add(new ArrayList(path));
return;
}
//从可选择表中依次选择,可选择列表就是nums中的数据
for(int i=0;i<nums.length;i++){
if(!visted[i]){
//如果没有被访问过
path.addLast(nums[i]);
visted[i]=true;
//下探到下一层
backTrack(nums,level+1,path,visted,res);
path.removeLast();
visted[i]=false;
}
}
}

回溯面试题
47. 全排列 II
https://leetcode-cn.com/problems/permutations-ii/submissions/

这一题在力扣第 46 题: 全排列 的基础上增加了序列中的元素可重复这一条件,但要求:返回的结果又不能有重复元素。
如何理解:参考精选题解:
所谓返回结果的重复:
重复即为:存在相同数字,比如 [1,2,2’] ,那么答案 [1,2,2’] 和 [1,2’,2] 就其实是一样的,在保
存结果的时候,我们只需要一个。
我们能想到的最简单的做法可能会有下面几种:
1:先生成完所有的结果,然后对结果集进行去重
2:每次生成结果时先判断是否已有这个结果了,如果有了则丢弃(全排列终止时判断)
这两种办法均不太好的地方在于:
1:我们生成的结果并非字符串这种简单结构,每个结果是 List
无论是去重,还是判断结果是否已存在都不太好操作
2:及时能够这样做,但是最终的复杂度也非常高。
那么我们能不能在生成答案的过程中就将其 剪枝(类比用过的数字就不考虑),这样根本就不会生成重
复的答案了。答案是可以的,具体思路我们可以借鉴精选题解:https://leetcodecn.com/problems/permutations-ii/solution/hot-100-47quan-pai-lie-ii-python3-hui-su-kao-lu-zh/中对于
如何剪枝的图解部分!
核心思想就是:
1:考虑重复元素一定要优先排序,将重复的都放在一起,便于找到重复元素和剪枝!!!
2:剪枝条件是:和前一个元素值相同(index>0),并且前一个元素还没有被使用过
因为每次在处理当前层的时候,如果前一个重复元素没有使用过,那么它一定会出现在当前重复元素的下一层可选择列表中,那最终枚举出来的结果就一定会重复。(和前一个重复元素使用后,当前重复元素出现在它的下一层可选择列表中枚举出来的结果重复)
当然:在整个代码编写过程中,需要有两处剪枝,一处是正常全排列要记录哪些已经走过了,第二处就是刚刚说的遇到重复元素的剪枝;当然第二个剪枝依赖于对可选择列表排序!
public List<List<Integer>> permuteUnique(int[] nums) {
List<List<Integer>>res=new ArrayList();
Deque<Integer>path=new ArrayDeque();
boolean[]visted=new boolean[nums.length];
//排序,是剪枝的前提
Arrays.sort(nums);
backTrack(nums,1,visted,path,res);
return res;
}
public void backTrack(int[]nums,int level,boolean[]visted,Deque<Integer>path,List<List<Integer>>res){
//层数大于了数组的长度 terminal
if(level>nums.length){
res.add(new ArrayList(path));
return;
}
//process current logic
for(int i=0;i<nums.length;i++){
//剪枝
if(visted[i]){
continue;
}
//长度大于1,并且与前面一个比一样,而且前面一个是被访问过的,跳过
if(i>0&&nums[i]==nums[i-1]&&!visted[i-1]){
continue;
}
path.addLast(nums[i]);
visted[i]=true;
backTrack(nums,level+1,visted,path,res);
path.removeLast();
visted[i]=false;
}
}
78. 子集
https://leetcode-cn.com/problems/subsets/

回溯算法,套通用模板!
选择的过程及构成的决策树如下

public List<List<Integer>> subsets(int[] nums) {
List<List<Integer>>res=new ArrayList();
Deque<Integer>deque=new ArrayDeque();
backTrack(nums,0,deque,res);
return res;
}
public void backTrack(int[]nums,int start,Deque<Integer>deque,List<List<Integer>>res){
//每下探一层都会记录中间结果!
res.add(new ArrayList(deque));
//这里for循环结束就是终止条件了
for(int i=start;i<nums.length;i++){
//做出选择
deque.addLast(nums[i]);
//下探,start传i+1,找的是子集
backTrack(nums,i+1,deque,res);
//撤销本层选择,回溯发生的地点
deque.removeLast();
}
}
注意:
1:这道题和全排列终止的条件不一样,全排列是到树的底部后我们才需要记录排列结果,而子集这道题,我们是选择一步就需要记录一下结果,因为每选择的一步都会构成一个新的子集。
2:子集这道题和全排列他们的选择列表处理形式不太一样,全排列每次选择都可以从数组nums中任意选择,只不过我们通过visited/used来剪枝,以前选过的就不选了;而子集这道题我们是通过循环开始start 来逐步缩小子集的范围。
此题还可以用数学归纳法思想,结合递归来求解!
90. 子集 II
https://leetcode-cn.com/problems/subsets-ii/

public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>>res=new ArrayList();
Deque<Integer>path=new ArrayDeque();
boolean[]used=new boolean[nums.length];
Arrays.sort(nums);
backTrack(nums,0,used,path,res);
return res;
}
public void backTrack(int[]nums,int start,boolean[]used,Deque<Integer>path,List<List<Integer>>res){
//每下探一层都记录中间结果
res.add(new ArrayList(path));
for(int i=start;i<nums.length;i++){
if(i>0&&nums[i]==nums[i-1]&&!used[i-1]){
continue;
}
path.addLast(nums[i]);
used[i]=true;
backTrack(nums,i+1,used,path,res);
path.removeLast();
used[i]=false;
}
}
77. 组合
https://leetcode-cn.com/problems/combinations/

public List<List<Integer>> combine(int n, int k) {
List<List<Integer>>res=new ArrayList();
Deque<Integer>path=new ArrayDeque();
从1~n,数组下标0不可用,长度为n+1
boolean[]used=new boolean[n+1];
backTrack(n,k,1,used,path,res);
return res;
}
public void backTrack(int n,int k,int start,boolean[]used,Deque<Integer>path,List<List<Integer>>res){
//terminal 这里并不是递归的深度达到多少而终止,而是走过的路径中包含了k个数就需要记录一下结果
if(path.size()==k){
res.add(new ArrayList(path));
return;
}
for(int i=start;i<=n;i++){
if(used[i]){
continue;
}
path.addLast(i);
used[i]=true;
backTrack(n,k,i+1,used,path,res);
path.removeLast();
used[i]=false;
}
}
17. 电话号码的字母组合
https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number/
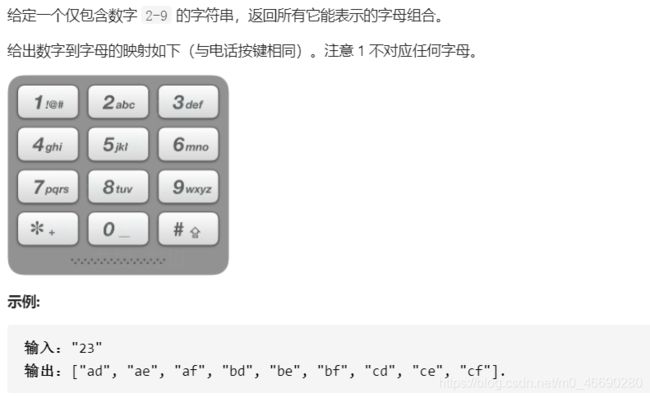
思考要点:
1:给出的字符串digits有多少位,结果集中每种组合的长度就是多少。
2:有点类似括号生成,只不过不再是生成左右括号,而是生成每个字符对应的字母
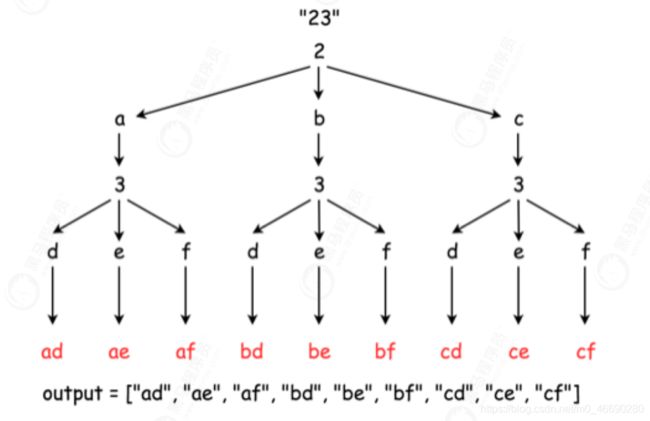
每层生成的结果,及下探到下一层的过程如下图(递归的状态树):
public List<String> letterCombinations(String digits) {
List<String>res=new ArrayList();
if(digits==null||digits.length()==0){
return res;
}
Map<Character,String>map=new HashMap();
map.put('2',"abc");
map.put('3',"def");
map.put('4',"ghi");
map.put('5',"jkl");
map.put('6',"mno");
map.put('7',"pqrs");
map.put('8',"tuv");
map.put('9',"wxyz");
StringBuilder sb=new StringBuilder();
backTrack(digits,0,sb,map,res);
return res;
}
//此处的StringBuilder sb就是我们走过的路径,
public void backTrack(String str,int index,StringBuilder sb,Map<Character,String>map,List<String>res){
//相当于扫描题目所给的digits,每遇见一位字符就去生成对应的字母
if(index==str.length()){
res.add(sb.toString());
return;
}
//找出待选择列表(这里和之前不一样的是,每层选择列表不一样)
char c=str.charAt(index);
String st=map.get(c);
//这里不需要用uesd来剪枝的原因是每次选择列表不一样,不存在所谓的重复(之前是因为每次下探到下 一层是还是在原选择列表做选择)
for(int i=0;i<st.length();i++){
sb.append(st.charAt(i));
backTrack(str,index+1,sb,map,res);
sb.deleteCharAt(sb.length()-1);
}
}
51. N 皇后
https://leetcode-cn.com/problems/n-queens/

经典的回溯问题,N皇后是8皇后的扩展,8皇后经常在教科书中被那出来讲解回溯算法!
参考官方题解的解法一:基于集合的回溯:https://leetcode-cn.com/problems/nqueens/solution/nhuang-hou-by-leetcode-solution/
回溯过程参看题解:https://leetcode-cn.com/problems/n-queens/solution/gen-ju-di46-ti-quan-pai-lie-de-hui-su-suan-fa-si-/中的动图效果
public List<List<String>> solveNQueens(int n) {
//特殊判断 n=1 或 n>=4才有解
List<List<String>>res=new ArrayList();
if((n<1)||(n>1&&n<4)){
return res;
}
//存储n皇后的放置结果,数组下标i代表放在哪行,queens[i]代表放在哪列
int[]queens=new int[n];
Arrays.fill(queens,-1);//代表初始状态
//创建三个Set集合,在回溯过程中用于判断在列,撇,捺上是否已经有皇后存在了
Set<Integer>lie=new HashSet();
Set<Integer>pie=new HashSet();
Set<Integer>na=new HashSet();
bakcTrack(n,0,queens,lie,pie,na,res);
return res;
}
public void bakcTrack(int n,int row,int[]queens,Set<Integer>lie,Set<Integer>pie,Set<Integer>na,List<List<String>>res){
if(row==n){
//根据queens生成返回结果
List<String>result=genResult(queens,n);
res.add(result);
return;
}
//相当于是在行,列,撇,捺四个层面去回溯
for(int i=0;i<n;i++){
//剪枝1:如果该列上有皇后了则跳过
if(lie.contains(i)){
continue;
}
//剪枝2:判断撇上是否已经有皇后了:在同一撇上的皇后,行列坐标之和是相等的
int rowAddColumn=row+i;
if(pie.contains(rowAddColumn)){
continue;
}
//剪枝3:判断捺上是否已经有皇后了:在同一捺上的皇后,行列坐标之差是相等的
int rowSubColumn=row-i;
if(na.contains(rowSubColumn)){
continue;
}
//让皇后落在该行该列上
queens[row]=i;
lie.add(i);//该列已经有皇后了
pie.add(rowAddColumn);;//该撇上已经有皇后了
na.add(rowSubColumn);//该捺上已经有皇后了
//drill down下探到下一行(下一层)bakcTrack(n,row+1,queens,lie,pie,na,res);
queens[row]=-1;
lie.remove(i);
pie.remove(rowAddColumn);
na.remove(rowSubColumn);
}
}
public List<String> genResult(int[]queens,int n){
List<String>tempResult=new ArrayList();
for(int i=0;i<queens.length;i++){
char[]row=new char[n];
Arrays.fill(row,'.');
row[queens[i]]='Q';
tempResult.add(new String(row));
}
return tempResult;
}
169. 多数元素
https://leetcode-cn.com/problems/majority-element/

我们使用经典的分治算法递归求解,直到所有的子问题都是长度为 1 的数组。长度为 1 的子数组中唯一的数显然是众数,直接返回即可。
如果分治后某区间的长度大于 1,我们必须将左右子区间的值合并。如果它们的众数相同,那么显然这一段区间的众数是它们相同的值。否则,我们需要比较两个众数在整个区间内出现的次数来决定该区间的众数。
public int majorityElement(int[] nums) {
return
// 分治~合并
divideConquer(nums,0,nums.length-1);
}
public int divideConquer(int[]nums,int start,int end){
if(start==end){
return nums[start];
}
int mid=(end-start)/2+start;
int leftMajor=divideConquer(nums,start,mid);
int rightMajor=divideConquer(nums,mid+1,end);
//子区间的众数一样则直接返回
if(leftMajor==rightMajor){
return leftMajor;
}
//leftMajor在[start,end]中出现的次数为
int leftCount=count(nums,leftMajor,start,end);
//rightMajor在[start,end]中出现的次数为
int rightCount=count(nums,rightMajor,start,end);
return leftCount>rightCount?leftMajor:rightMajor;
}
public int count(int[]nums,int major,int start,int end){
// 在[start,end]区间内统计众数major的出现次数
int count=0;
for(int i=start;i<=end;i++){
if(nums[i]==major){
count++;
}
}
return count;
}