带你了解Python面向对象 高级篇:总结了21种魔法方法,7种类或对象自带的属性
内容较多,如发现错误或需要纠正的地方,请评论通知笔者修改!感谢阅读与支持~
目录
- 前言:
- 魔法方法
-
- 点拦截方法
-
- setattr
- getattr
- delattr
- 阶段小结
- 拦截方法:__getattribute__
- [] 拦截方法
-
- setitem
- getitem
- delitem
- format 格式化对象触发
- del 删除对象触发
- call 调用对象触发
- __init__与__new__的关系,面试常见问题
-
-
- 小结:使用一个类创建多个类的对象
-
- str 返回对象描述信息
- repr 返回对象描述信息
- str与repr的区别
- iter与next 实现迭代器对象
-
- __iter__与__next__魔法方法的使用
-
- 小结:制作一个模拟range函数的迭代器
- len 通过len(对象)触发
- hash 通过hash(对象)触发
- eq 对象之间比较触发
- enter与exit 实现上下文管理器
- 补充内容:链式调用
- 类或对象自带属性
-
- doc 查看类的注释信息
- class 查看对象所属类
- module 查看实例对象的类所在模块
- slots限制对象可用属性
- base 查询单继承类
- bases 查询多继承的类
- mro 多继承时属性或方法的查找顺序
前言:
本章节即将了解到Python中,类提供的一些内置方法,可以称之为:魔法方法,它的特殊之处在哪里?为何以魔法相称,是因为这些方法不需要我们主动调用,它们自己就能够在某些场景下触发:如:__init__方法,它则是在我们调用类时触发的,那么下来来详细了解魔法方法的使用
魔法方法
魔法方法存在于类中,指的是在某种情况下自动触发的方法
我们根据分类来掌握魔法方法更为简单一些
点拦截方法
为什么这称为:点拦截方法呢,因为此类魔法方法只有在通过对象.操作属性时才会触发,所以在触发方法时,对给属性赋的值进行一个处理
这个方法有点类似于我们封装里面提到过的property类似效果,那么是否相似接着向下了解吧!!!
点拦截方法分别是:
__setattr__在对象.属性=值时自动触发,也就是更改属性值时自动触发
__getattr__在对象.属性时自动触发,前提是:当属性不在对象内的时候才会触发,有点鸡肋
__delattr__在del 对象.属性时自动触发,也就是在删除对象属性时自动触发
setattr
当我们通过.增加或修改对象属性的时候,会触发此方法
class People:
def __setattr__(self, key, value): # 默认携带3个参数,属性、属性名、属性值
print('修改了对象属性')
# 注意:如果我们查找对象的属性,那么则会报错,
# 因为对象在增加属性的时候就会执行这个方法
# 而那时候属性还没有添加到对象里,所以会报错
# print(self.name)
p = People()
p.name = 'tom'
> '我们修改了对象属性' # 可以看到,当通过:对象.属性赋值时 触发__setattr__方法的运行
getattr
在我们通过.查询属性的时候且查询的方法不存在才会触发这个方法,太鸡肋了
class People:
def __init__(self, name, age):
self.name = name
self.age = age
def __getattr__(self, item):
# 不可以这样使用:self.属性名,因为涉及到了查询属性,这样也会造成无限递归
return f'{item}属性不存在'
p = People('jack', 18)
p.name = 'tom'
print(p.name) # 存在,不触发__getattr__方法
> 'tom'
print(p.n) # 查找的属性不存在,触发__getattr__方法
> 'n属性不存在'
delattr
当通过del 对象.属性删除时,才会触发此方法
class People:
def __init__(self, name, age):
self.name = name
self.age = age
def __delattr__(self, item):
print(f'已经删除{item}属性')
# 我们这里不可以使用:del self.属性,因为在这里再进行属性删除会造成递归
p = People('jack', 18)
p.name = 'tom'
del p.name
> '已经删除name属性'
del p.s
> '已经删除s属性'
即使删除的属性不存在,也会执行该方法且不会报错
阶段小结
自定义一个字典,继承dict类,可以通过[]取值赋值,也可以通过.取值赋值
class Dic(dict):
def __setattr__(self, key, value):
self[key] = value # 将对象.属性名 = 值拿到,添加到字典内
def __getattr__(self, item):
return self[item] # 查询属性时,会传递一个属性名进来,返回对象字典内key对应的值
dic = Dic(name='jack', age=18)
dic['sex'] = 'male'
dic.width = 20000
print(dic.__dict__) # 查看dic对象的属性
> {
} # 可以看到为空,因为我们并没有将值赋到属性内
print(dic['width'])
> 20000
print(dic.sex)
> 'male'
题目分析:
我们在给字典赋值时,如果通过
对象.属性赋值时,则触发了__setattr__方法,触发以后将传递进去的属性名与值添加到字典对象里面也就是self,然后我们通过对象.属性查询时,触发了__getattr__执行,为何会触发呢,因为我们在前面并没有将对象.属性=值执行后的结果放入对象属性内,而是放到了字典内它是一个特殊的存在,可以看到值,但并没有属性,找到到这个属性则执行了__getattr__方法,然后拿着传递的属性名,返回字典(self)内key对应的value即可。
必须依赖继承与dict类,因为没有它我们无法做到[]赋值的操作,等我们学到item系列的魔法方法时,就可以完全自定义字典类,不需要任何继承而做到这种效果
拦截方法:getattribute
咋眼一看,它很类似于我们点拦截方法里面的:__getattr__,但它们却是背道而驰,水火不容。__getattr__只要查询的属性不存在时,才会触发。而__getattribute__则是不管属性是否存在,它都会触发。那么就会出现一个问题,它们谁会优先执行呢?答案是:__getattribute__
而且它会起到一个拦截的作用,就是说在涉及到查询属性时就会触发,并且会被这个方法所拦截,我们需要进行处理才能通过
我们实例便知:
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __getattr__(self, item):
print('__getattr__执行了')
def __getattribute__(self, item):
print('__getattribute__执行了')
p = People('jack',18)
p.llll
> '__getattribute__执行了'
# 查询一个不存在的属性,可以发现也是__getattribute__方法执行了,所以它会优先于__getattr__触发
print(p.name)
> '__getattribute__执行了'
> 'None'
我们看不到p.name的属性值,原因是执行了__getattribute__方法,被拦截住了
我们需要它在执行__getattribute__后再将对象属性的数据进行返回
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __getattr__(self, item):
print('__getattr__执行了')
def __getattribute__(self, item):
print('__getattribute__执行了')
return object.__getattribute__(self,item) # 返回对象属性
p = People('jack',18)
print(p.name)
> '__getattribute__执行了'
> 'jack'
两个同时存在,那么__getattr__真的就毫无作用了?并不是的
如果两个方法都存在,且执行__getattribute__·抛出了异常AttributeError,那么才会触发__getattr__的执行
实例:
class People:
def __init__(self, name, age):
self.name = name
self.age = age
def __getattr__(self, item):
print('__getattr__执行了')
def __getattribute__(self, item):
raise AttributeError("111") # raise表示直接抛出异常
p = People('jack', 18)
p.name
执行结果:
'__getattr__执行了'
[] 拦截方法
此方法,主要是通过[]操作对象时才会触发
[]拦击方法分别是:__setitem__、__getitem__、__delitem__
__setitem__:通过中括号向对象设置值时会触发
__getitem__:通过中括号向对象查询值时会触发
__delitem__:通过中括号删除对象值时会触发
setitem
实现起来的效果类似于字典赋值
实例:
class People:
def __init__(self,name,age):
self.name = name
self.age = age
# 当我们通过对象[key] = value时会触发这个方法
def __setitem__(self, key, value):
# 只能将值写入到属性内,因为如果是这样:self[key] = value,
# 则会继续触发__setitem__这个方法的运行,最终导致递归
self.__dict__[key] = value
p = People('jack',18)
p['sex'] = 'male'
print(p.sex)
> 'male'
已经可以实现,通过[]向对象赋值,那么我们接下来使用[]进行取值
getitem
当我们进行对象[key]取值时,会触发__getitem__方法的运行
实例:
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __setitem__(self, key, value):
self.__dict__[key] = value
def __getitem__(self, key):
# 不可以这样返回值,我们并不是一个真正的字典,因为我们的属性还都只是存在于属性字典__dict__内。
# return self[key]
return self.__dict__[key] # 返回对象属性字典内对应key值
p = People('jack',18)
p['sex'] = 'male'
print(p['sex'])
> 'male'
print(p.sex)
> 'male'
我们已经达到了一种伪字典的取值和赋值的操作。且支持使用.取值与赋值,后期读源码可能会遇见使用[]操作对象。
delitem
当我们进行del 属性[key]时,也就是通过key删除对象属性时,触发的方法
实例:
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __setitem__(self, key, value):
self.__dict__[key] = value
def __getitem__(self, key):
return self.__dict__[key]
def __delitem__(self, key):
print(f'已经删除{key}属性值')
del self.__dict__[key] # 删除对象属性字典内对应的key
p = People('jack',18)
p['sex'] = 'male'
del p['sex']
format 格式化对象触发
__format__触发方式有两种:format内置函数、"{:}’’.format(对象名)
第一种:format函数
class People:
def __format__(self, format_spec):
print(format_spec)
return ''
p = People()
format(p,'222')
执行结果
'222'
第二种:
class People:
def __format__(self, format_spec):
print(format_spec)
return '返回值'
p = People()
print('{:08}'.format(p))
执行结果
08
返回值
下面结合案例来了解一下它的基本作用
class Date:
# 时间格式字典
__dict = {
# 我们待会用obj来接收到对象,那么obj就相当于对象了
'y-m-d':'{obj.year}-{obj.month}-{obj.day}',
'y/m/d':'{obj.year}/{obj.month}/{obj.day}',
'y:m:d':'{obj.year}:{obj.month}:{obj.day}',
'y年m月d日':'{obj.year}年{obj.month}月{obj.day}日',
}
def __init__(self,year,month,day):
self.year = year
self.month = month
self.day = day
def __format__(self, format_spec): # 根据传递的值,来决定时间格式
# 如果传入的格式,在我们定义的时间格式字典内,拿到对应的时间格式
if format_spec in self.__dict:
fmt = self.__dict[format_spec]
else: # 不在的话,选择一个默认的作为时间格式
fmt = self.__dict['y-m-d']
return fmt.format(obj = self) # 将self变成obj传递给时间格式内
date = Date(2020,10,20)
print('{:y年m月d日}'.format(date))
print(format(date,'y:m:d'))
执行结果
'2020:10:20'
'2020年10月20日'
del 删除对象触发
删除对象时会触发__del__方法
注意:删除属性不会触发__del__方法的运行
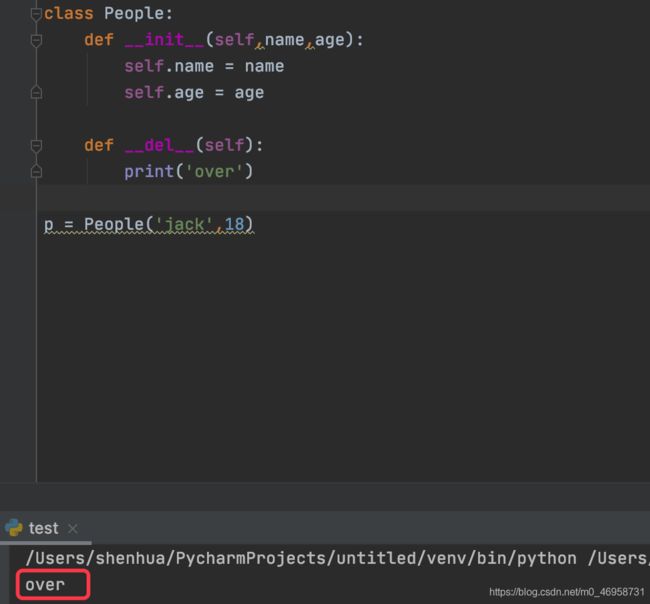
第一种触发方式:主动删除对象
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __del__(self):
print('over')
p = People('jack',18)
del p
> 'over'
第二种触发方式:整个程序结束时
那么del方法的作用是什么呢?在对象结束时,回收这个对象所占资源,例如:
class People:
def __init__(self):
self.f = open('a.txt','wt',encoding='utf-8')
def __del__(self):
print('over,已回收该对象所有资源')
self.f.close()
p = People()
如果我们不在利用完文件以后关闭文件,则文件会继续占用系统资源一段时间才会关闭,所以我们在使用完毕以后及时回收,所以这里写了一个__del__里面会帮助我们回收掉这个对象占用的资源。
重点理解:可以不用del,在程序结束时,Python默认会给我们加上,但是有些占用的资源还是我们提前写好回收更好些,就如上序文件的关闭
至于什么时候回收取决于开发者,但最好还是写上这个方法
call 调用对象触发
在调用对象时触发此方法,且可以传值进入
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __call__(self, *args, **kwargs):
print('对象调用了')
print(args,kwargs)
p = People('jack',18)
# 调用对象时,会触发实例化该对象的类里面的__call__方法的运行
p(1,2,3,4,a = 111,b=222)
# 并且可以传值进入
执行结果
对象调用了
(1, 2, 3, 4) {
'a': 111, 'b': 222}
__init__与__new__的关系,面试常见问题
在之前一直了解的是,__init__是类实例化对象时第一个触发的方法。但其实__init__并不是第一个触发的,而是__new__方法。
当我们通过:p = People('jack',18)时,最先被调用的是__new__方法
__new__作用就是,创建一个空对象,没有初始化的。我们传递的值,也会首先传递到__new__里面去
def __init__(self)
__init__里面的self(对象),就是由__new__所创建出来的。在__new__返回创建的空对象以后触发,然后初始化属性。
实例:
class People:
def __init__(self,name,age):
print('init方法触发了')
self.name = name
self.age = age
# 我们重写了new方法,然而我们并没有返回一个空对象
def __new__(cls, *args, **kwargs): # 调用类时传递的值,在这里也会接收到
print('new方法触发了')
p = People('jack',18)
print(p.name) # 我们调用这个对象的name属性
执行结果
new方法触发了 # 调用类时,第一个触发的就是new方法,因为需要它创建一个对象出来
产生报错:表示p对象没有name这个属性
AttributeError: 'NoneType' object has no attribute 'name'
__init__并没有接收到一个对象,所以self什么也不能代表,最后就是报错
那么我们需要让__new__方法返回一个对象出来,这样__init__方法才能正常运行。
对象要借助父类的new方法帮助我们创建出来,可以是object作为父类
class People:
def __init__(self,name,age):
print('init方法触发了')
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
print('new方法触发了')
# 借助父类帮助我们当前类创建一个空对象出来,然后返回由__init__的self接收到
return object.__new__(cls) # 也可以是super().__new__(cls)
p = People('jack',18)
print(p.name)
执行结果
'''
new方法触发了
init方法触发了
jack
'''
注意:
__new__返回的只有是自身这个类创建的对象才会触发__init__的执行
class People:
def __init__(self,name,age):
print('init触发了',self)
self.name = name
self.age = age
def __new__(cls, *args, **kwargs):
obj = super().__new__(cls)
print('new触发了',obj)
return obj # __init__执行
# 因为它是借助父类帮助我们当前类创建的对象,属于当前类对象,所以可以执行
# return 10 __init__不执行
# 10也算对象,为何__init__不执行呢,因为它不是当前类的对象。
p = People('jack',18)
执行结果
new触发了 <__main__.People object at 0x7f92ccc464c0>
init触发了 <__main__.People object at 0x7f92ccc464c0>
小结:使用一个类创建多个类的对象
class Teacher:
pass
class Student:
pass
class People:
# 调用People时传递的值也会传递到new里面,重要的事情提3遍!!
def __new__(cls, *args, **kwargs):
if args[0] == 't':
return super().__new__(Teacher) # 创建Teacher类的对象
elif args[0] == 's':
return super().__new__(Student) # 创建Student类的对象
elif args[0] == 'p':
return super().__new__(cls) # 创建当前类的对象
else:
print('该类不存在,无法实例对象')
t = People('t')
s = People('s')
p = People('p')
oo = People('oo')
执行结果
'该类不存在,无法实例对象'
<class '__main__.People'>
<class '__main__.Student'>
<class '__main__.People'>
str 返回对象描述信息
此方法通常返回对象的描述信息,一般放置一个return + 描述信息即可
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __str__(self):
return f'这是{self.name}的对象'
p = People('jack',18)
print(p) # 打印时会触发__str__的运行
执行结果
'这是jack的对象'
repr 返回对象描述信息
与__str__的效果类似,都是打印对象提供信息的
class People:
def __init__(self,name,age):
self.name = name
self.age = age
def __repr__(self):
return f'这是{self.name}的对象'
p = People('jack',18)
print(p)
执行结果
'这是jack的对象'
str与repr的区别
如果它们同时存在,__str__优先于__repr__触发
class People:
def __repr__(self):
return 'this repr return'
def __str__(self):
return 'this str return'
p = People()
print(p)
而__str__与__repr__跟显著的区别在于命令行中的显示
repr在命令行的效果

再来看一下str在命令行展示的效果

repr:倾向于给开发者更好的提示:在命令行调用和print打印对象都会触发__repr__的运行
str:倾向于给使用者更好的提示:在命令行只是调用对象就会返回这个对象自身的信息,而print打印则会触发__str__的运行
iter与next 实现迭代器对象
了解过迭代器的都应该知道,__iter__是将可迭代对象转换成迭代器对象。
我们在魔法方法内使用这两个方法作用是:让对象可以被for循环
可迭代对象具备了:__iter__()方法
迭代器对象则具备了:__iter__()与__next__()的方法
拿列表举例:
# 列表为可迭代对象
l = [1,2,3,4].__iter__() # 将可迭代对象变成迭代器对象
# 此时列表就具备了迭代的功能,
print(l.__next__())
print(l.__next__())
> 1
> 2
只要能被for循环的都是可迭代对象
那么我们平时所使用的对象是否为可迭代对象呢?可以来查看一下
class Test:
def __init__(self,lis):
self.lis = lis
p = Test([1,2,3,4])
可以看到并不具备__iter__,所以它不是一个迭代对象,但是我们可以通过魔法方法让它成为变成迭代对象
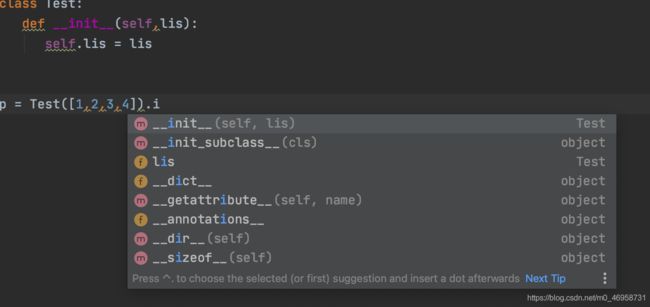
__iter__与__next__魔法方法的使用
__iter__生成迭代器对象时调用,返回值必须是对象自身
__next__进行__iter__返回迭代器对象以后就可以调用此方法了
class Test:
def __init__(self):
self.__x = 0
def __iter__(self):
return self # 返回一个迭代器对象
def __next__(self): # 我们使用循环,每次都会调用此方法
self.__x += 1
if self.__x > 10: # 当调用过10次这个next方法后,抛出一个异常,结束循环
raise StopIteration()
return self.__x # 返回每一次调用next方法的结果
# for循环流程:
# 调用in后面的对象,先执行里面的__iter__方法,拿到一个迭代器对象
# 然后再不断执行__next__方法,直到抛出异常,结束循环
for i in Test():
print(i)
执行结果
1
2
3
4
5
6
7
8
9
10
小结:制作一个模拟range函数的迭代器
class MyRange:
def __init__(self, start, end, step=1):
self.start = start
self.end = end
self.step = step # 步长,如果未传值,默认为1
print(self.start) # 打印初始值,因为经过next后会覆盖初始值
def __iter__(self):
return self
def __next__(self):
self.start += self.step # 循环的初始值加步长
if self.start >= self.end: # 当大于指定的结束数值时,抛出异常
raise StopIteration()
return self.start
for i in MyRange(1, 10, 2):
print(i)
执行结果
1
3
5
7
9
len 通过len(对象)触发
我们平常使用len函数,作用就是统计元素的数量。那么我们也可以给自己这个对象定制一个__len__方法。
class People:
def __init__(self,name,age):
self.name = name
self.age = age
# 当通过len方法调用我们这个类实例化的对象时,会触发这个方法
def __len__(self):
return len(self.__dict__) # 这里我们可以返回这个对象具备的属性个数
p = People('jack',18)
print(len(p))
执行结果
2
可根据自身需要重写__len__方法,至于返回内容取决于个人。
hash 通过hash(对象)触发
哈希分为两种:
可hash:不可变数据类型
不可hash:可变数据类型
我们通过测试来查看:
l = [1,2,3,4]
print(hash(l))
> TypeError: unhashable type: 'list'
因为是不可哈希类型
如果一个对象不可hash,可以通过重写 __hash__让它变得可hash。
我们自己定义一个对象,让它变得可hash
class Foo:
def __init__(self):
self.name = 'lqz'
def __hash__(self):
return hash(self.name)
f = Foo()
print(hash(f))
此后这个对象就可hash,且返回了一个哈希值
执行结果
4484138826618334890
eq 对象之间比较触发
针对的是:obj1 == obj2对象之间比较的的规则__eq__方法
可以自定义比较规则
class People:
def __init__(self, name):
self.name = name
def __eq__(self, other):
# 如果当前对象与比较的对象name属性相同,则返回True
if self.name == other.name:
return True
return False
# 两个对象都有相同的name属性
p1 = People('jack')
p2 = People('jack')
print(p1 == p2)
print(p2 == p1)
执行结果
True
True
enter与exit 实现上下文管理器
在此之前,我们都是使用:with(上下文管理协议)来帮助我们对操作的对象进行善后操作,如:关闭文件等
with open('a.txt','wt',encoding='utf-8') as f:
f.write(123)
方便之处在于,我们不需要执行完操作以后,手动清理一些资源。如上序:with会在我们使用完文件以后,帮助我们关闭掉这个文件。很良心!
而它本质就是由__enter__与__exit__两个方法组成。
__enter__:在使用with 对象后触发
__exit__:with语句内代码执行完毕或抛出异常后触发
我们通过小案例来简单说明:
class Opend: # 默认参数,如果有传值则替换,没有则使用默认
def __init__(self, file_path, mode='wt', encoding='utf-8'):
self.f = open(file_path, mode, encoding=encoding) # 创建文件句柄
def __enter__(self):
print('已使用with进行上下文管理')
return self.f # 当使用with Open对象时,as 后的内容就是我们使用__enter__返回的文件句柄
# 当使用完with结束以后触发,做一些资源清理操作
def __exit__(self, exc_type, exc_val, exc_tb):
print('已退出with上下文管理')
self.f.close()
with Opend('a.txt', 'wt', 'utf-8') as f:
f.write('123')
print('写入了内容:123')
执行无报错,相信已经可以看到内容写入到了文件。上面只是感受一下可以实现的效果,但还是有一些细节需要讲解。
__exit__方法的参数:
exc_type:with结束时,如果产生报错的话,报错类型就会被传到这里
exc_val:报错信息
exc_tb:追溯信息
如果执行with里面的代码时产生报错,那么后面的所有代码都不会运行
class Opend:
def __init__(self, file_path, mode='wt', encoding='utf-8'):
self.f = open(file_path, mode, encoding=encoding) # 创建文件句柄
def __enter__(self):
print('已使用with进行上下文管理')
return self.f # 当使用with Open对象时,as 后的内容就是我们使用__enter__返回的文件句柄
# 当使用完with结束以后触发,做一些资源清理操作
def __exit__(self, exc_type, exc_val, exc_tb):
print('已退出with上下文管理')
self.f.close()
with Opend('a.txt', 'wt', 'utf-8') as f:
f.read() # 设置的是写模式,读取文件就会产生报错
print('写入了内容:123')
print('==========================')
执行效果
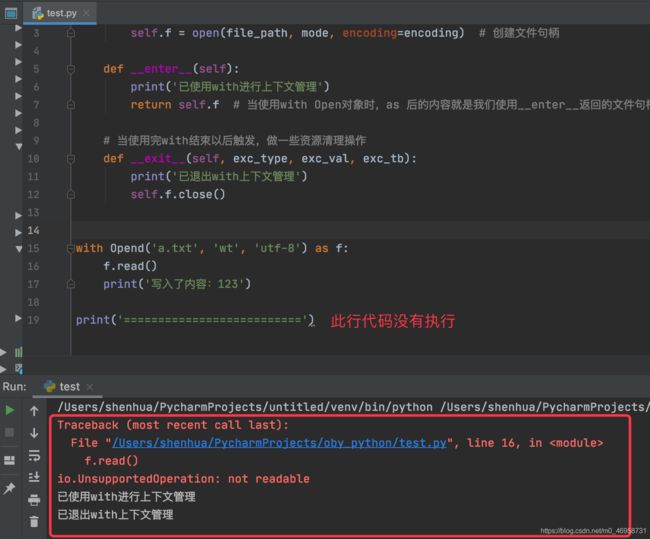
我们可以对这个报错进行一个清空,也就是说,不让它影响后续代码的运行。
只需要在with产生报错后,在__exit__里面进行return True,这样就可以达到我们的目的
class Opend:
def __init__(self, file_path, mode='wt', encoding='utf-8'):
self.f = open(file_path, mode, encoding=encoding) # 创建文件句柄
def __enter__(self):
print('已使用with进行上下文管理')
return self.f # 当使用with Open对象时,as 后的内容就是我们使用__enter__返回的文件句柄
# 当使用完with结束以后触发,做一些资源清理操作
def __exit__(self, exc_type, exc_val, exc_tb):
if exc_type:
print(f'使用with过程中产生{exc_type}错误,错误信息:{exc_val}')
print('已退出with上下文管理')
self.f.close()
return True
else:
print('已退出with上下文管理')
self.f.close()
with Opend('a.txt', 'wt', 'utf-8') as f:
f.read()
print('写入了内容:123')
print('==========================')
执行结果
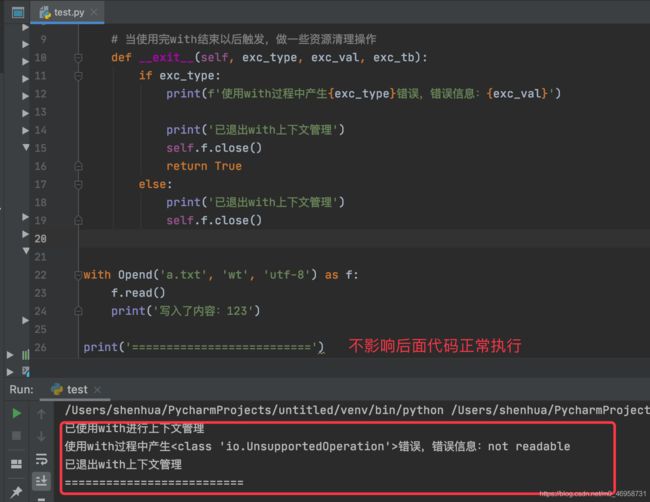
使用上下文管理的好处:
1.使用with语句的目的就是把代码块放入with中执行,with结束后,自动完成清理工作,无须手动。
2.在需要管理一些资源比如文件,网络连接和锁的编程环境中,可以在__exit__中定制自动释放资源的机制,写好相关资源清理以后,我们在使用自己定制的上下文管理器。无需担心使用完后会有资源残留。
补充内容:链式调用
看到这个有没有想起链式赋值?
a = b = c = 1
虽说名称比较类似,但效果则不同
拿一个常见的举例:
c = '123'.strip().lower().swapcase()
# 解析:
'123'.strip() # 进行strip()方法后,还是会返回一个字符串对象
# 拿到这个对象又调用了lower()方法,这个方法还是返回一个字符串对象
# 所以又可以调用swapcase()方法
# 所以,只要返回了对象,而且这个对象有方法则可以继续调用
这种就是链式调用,后面都是在前面返回了对象的基础上,且对象具备调用方法,就可以进行链式调用
我们可以通过自己创建的对象来尝试
class People:
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
# 每次调用方法都返回了对象,如果不返回对象,则不能进行链式调用
def print_name(self):
print(self.name)
return self
def print_age(self):
print(self.age)
return self
def print_sex(self):
print(self.sex)
return self
p = People('jack', 18, 'male')
# 正常调用
# p.print_name()
# p.print_age()
# p.print_sex()
# 链式调用
p.print_name().print_age().print_sex() # 每次调用方法都能拿到对象,所以可以持续调用
执行结果:
'jack'
'18'
'male'
类或对象自带属性
doc 查看类的注释信息
此属性用于获取类的描述信息
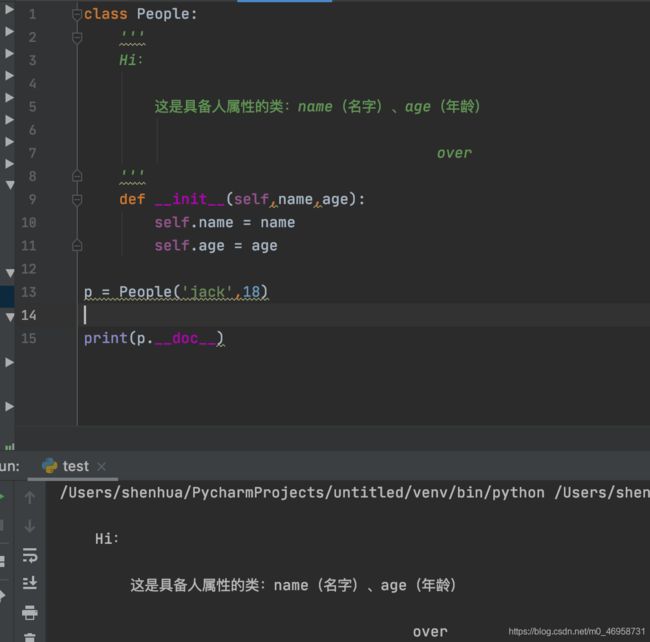
class People:
'''
Hi:
这是具备人属性的类:name(名字)、age(年龄)
over
'''
def __init__(self,name,age):
self.name = name
self.age = age
p = People('jack',18)
print(p.__doc__) # 或通过 print(People.__doc__)
执行效果:
注意:doc只能获取直属类的描述信息,不能获取继承类的描述信息
class Animal:
'''
Hi:
This Animal Description!
'''
class Dog(Animal):
pass
print(Dog.__doc__)
> 'None' # 结果为空
class 查看对象所属类
__class__查看当前这个对象的所属类,它与__bases__有些相似,但是__bases__提供给类使用,可以看到对象继承关系
class People:
pass
class Student(People):
pass
s = Student()
print(s.__class__)
执行结果:
<class '__main__.Student'>
只能看到实例出这个对象的类
module 查看实例对象的类所在模块
module:查看对象属于哪个模块下面的类,如果是当前文件则打印__main__,不是当前文件则打印模块名
先来使用不属于当前文件内的类
# test.py
class People:
pass
# run.py
from test import People
p = People()
print(p.__module)
执行结果
test # 不属于当前文件内的类,打印出所在模块的文件名
当前文件内的类
class People:
pass
p = People()
print(p.__class__)
执行结果
<class '__main__.People'>
slots限制对象可用属性
在类中设置__slots__后,通过该类实例化后的对象,都将失去__dict__属性,也就是说,我们实例化后的对象都不能产生任何属性了。
__slots__它是一个类属性,可以是字符串、列表、元组
class People:
__slots__ = ['name','age']
def __init__(self,name,age):
self.name = name # 都是给类设置的属性,因为我们使用了__slots__
self.age = age # 此时self指向的就是__slots__里面的类属性名
p = People('jack',18)
print(p.name)
print(p.__dict__)
执行结果
'jack'
报错:AttributeError: 'People' object has no attribute '__dict__'
对象已经不存在__dict__属性了,我们在__init__里面设置的属性都将成为类属性,且我们调用类时传递的内容必须遵循__slots__里面的配置
class People:
__slots__ = ['name','age'] # 此类只允许设置name和age属性
def __init__(self,name,age,sex):
self.name = name
self.age = age
self.sex = sex
# 从这里开始就报错了,因为限制了类可以设置的属性。
p = People('jack',18,'male')
它也可以作为查询可用属性来使用
class People:
__slots__ = ['name','age']
def __init__(self,name):
self.name = name
p = People('jack')
print(People.__slots__)
print(p.__slots__)
执行结果
['name', 'age']
['name', 'age']
表示这个类开放设置的属性
而__slots__的应用场景是什么呢?
1、限制对象属性
2、节省内存(对象很多,属性很少,推荐使用)
因为如果我们对象特别多,属性又很少,那么将会占用大量内存,此时我们可以使用__slots__来帮助我们节省内存空间,共用类属性(共用指的是共用属性名,并不是属性值)
class People:
__slots__ = ['name','age']
def __init__(self,name):
self.name = name
p = People('jack')
p2 = People('tom')
print(p.name)
print(p2.name)
执行结果
'jack'
'tom'
对象自身没有名称空间,统一使用类的名称空间(类属性名)
base 查询单继承类
查看当前类继承的父类
class People:
pass
class Student(People):
pass
print(Student.__base__)
> <class '__main__.People'>
bases 查询多继承的类
查看当前类继承的所有父类
class A:
pass
class B:
pass
class C(A,B):
pass
print(C.__bases__)
> (<class '__main__.A'>, <class '__main__.B'>)
mro 多继承时属性或方法的查找顺序
用于查看多继承时属性或方法查找的顺序,在多继承里会经常用到
class A:
pass
class B(A):
pass
class C(A):
pass
class D(B, C):
pass
print(D.__mro__) # D.mro() 效果相同
> (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
技术小白记录学习过程,有错误或不解的地方欢迎在评论区留言,如果这篇文章对你有所帮助请
点赞、评论、收藏+关注子夜期待您的关注,谢谢支持!