带你了解Python面向对象(6)高级篇:元类
目录
- 前言:
- 元类
-
- type元类
- exec内置函数
- 元类产生类的过程
- 手动创建类
- 自定义元类
-
- 控制生产类的过程
- 类实例化对象的过程
-
- 代码演示:对象实例化出来的整个过程
- 练习:定义修改属性为隐藏属性
- 属性查找
- 小结
- 补充内容:元类实现单例模式
前言:
既然Python中一切皆为对象,有没有想过,我们定义的类它是否也为一个对象?类本质上也是一个对象,既然类是一个对象,那么就应该有一个类来产生它。这也就是本章节讲到的主题:元类,它也可以称之为:类的类。
元类
元类:负责产生类的,我们学习使用元类的目的就是:控制类的产生过程,也可以控制类实例化的对象产生的过程。
type元类
Python中一切类都是由type产生出来的
我们查看一个类的类型就可以知道。查看类型本质上就是查看目标是由哪个类产生出来的
class People:
pass
print(type(People))
执行结果
<class 'type'>
可以看到,结果为type,由此可以得知,Python中所有类都是由type所生产出来的,那有没有一个疑问?type是由谁生产出来的?
print(type(type))
执行结果
<class 'type'>
它也是由自身type生产出来的,不过不必纠结于这个。我们需要了解的是,type是如何生产类的,且我们可以自定义一个元类,来产生类。
在此之前我们需要储备一个知识点。
exec内置函数
exec可以执行存储在字符串或文件中的Python代码。
语法:
exec(object[, globals[, locals]])
第一个参数:Python代码
第二个参数:全局名称空间
第三个参数:将Python代码添加到局部名称空间
可以理解它们自成一个空间,其中第二个参数就是当前文件的全局名称空间,不需要了解
使用方式:
s = '''
a = 10
l = [1,2,3,4]
def test():
print('这是局部空间内的函数test')
''' # 注意缩进问题:因为里面的内容是要被当做Python代码执行的
dic1 = {
}
dic2 = {
}
exec(s,dic1,dic2) # 将dic2当做局部名称空间,将s里面的Python代码放入
print(dic2)
执行结果
{
'a': 10, 'l': [1, 2, 3, 4], 'test': <function test at 0x7fb4ea5b91f0>}
可以看到s被当做Python代码存入到了dic2这个命名空间内
我们尝试调用dic2里面的test函数
dic2['test']()
执行结果
'这是局部空间内的函数test'
注意:exec函数直接使用即可,不需要赋给某个变量或打印出来,因为它的返回值永远是None
元类产生类的过程
我们可以进去type里面去查看一下它的源码。
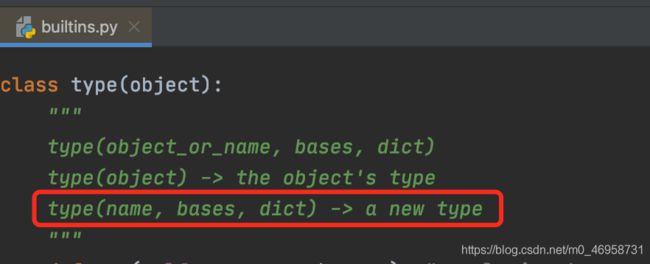
可以看到,当type创建类时,需要传递3个参数
name:类的名称
bases:父类(基类)
dict:类的名称空间
但是我们平时创建类时,并没有执行传值操作啊。这是因为Python在我们使用class时就默认帮我们将这些参数传递进去了
我们了解到这些以后,可以不使用class来创建类,根据元类提供的参数,我们自己定义参数传递给type,进行type返回给我们的一个新的类
手动创建类
首先需要类的名称:
class_name = 'People'
定义父类:
# class_bases = object 这样定义是错误的
class_bases = (object,) # 需要将它放在元组里才可以传递,注意后面的逗号
在定义类的名称空间前,我们需要先写好类里面需要的代码。称为:类体
class_body = """
name = 'jack'
age = 18
def print_name(self):
print(self.name)
"""
# 注意缩进哦,因为我们需要将它作为代码放到一个名称空间内
类的名称空间:
dic = {
}
exec(class_body,{
},dic)
# 第二个参数我们不需要,所以{}占位即可。此时我们就将代码放入了局部名称空间内
将以上所写传递给type,然后定义一个变量来接收产生的类
People = type(class_name,class_bases,dic)
最终效果:我们定义的People变量此时已经时一个真正的类了,来查看效果
print(People.__dict__)
# 因为是一个方法,所以需要传递一个参数进去,我们将类传入
People.print_name(People)
print(People.age)
执行结果
{
'name': 'jack', 'age': 18, 'print_name': <function print_name at 0x7f80c9db91f0>, '__module__': '__main__', '__dict__': <attribute '__dict__' of 'People' objects>, '__weakref__': <attribute '__weakref__' of 'People' objects>, '__doc__': None}
'jack'
'18'
我们此上做的所有步骤,等同于如下代码:
class People: # 此代码本质就是:type('People',object,dic)
name = 'jack'
age = 18
def print_name(self):
print(self.name)
我们使用class创建的类,Python都会帮助我们将这个类的相关参数传递给type。接下来我们要了解的是如何自定义元类,再使用自定义的元类来创建一个类。
自定义元类
我们自定义元类,需要将type作为继承。自定义主要目的就是让我们这个元类产生类的过程中能够变得可控制。
class MyType(type):
pass
class People(metaclass=MyType): # 选择MyType作为元类
pass
p = People()
print(People)
执行结果
<class '__main__.People'>
为什么还是有效果呢?因为我们自定义的元类继承type以后啥也没做,所以People这个类结果还是由type产生出来的,因为它会去找到我们自定义元类的父类,也就是type。
控制生产类的过程
第一个调用的就是__new__方法,来帮助我们生产类,而接下来调用的__init__方法则是对类做一些限制等等
所以我们可以重写父类的__init__与__new__方法
class MyType(type):
# 接收到__new__传递过来的参数
def __init__(self, class_name, class_bases, dic):
print(f'成功生产:{class_name}类')
super().__init__(class_name,class_bases,dic)
# 接收到传递而来的参数:('People',object,dic)
def __new__(cls, *args, **kwargs): # 元类的__new__是生产类的
print(f'正常在产:{args[0]}类')
return super().__new__(cls, *args, **kwargs)
# 等同于:People = MyType('People',object,dic)
class People(metaclass=MyType):
pass
p = People()
print(People)
执行结果:
'正在生产:People类'
'成功生产:People类'
(<class 'object'>,)
那么此时,我们已经可以控制类在生产过程中做的事情了,如上序:我们在生产类时执行了print操作,在平常可不能这样。
我们可以对类名进行限制,如:首字母必须大写
class MyType(type):
def __init__(self,class_name,class_bases,dic):
print(f'正常生产:{class_name}类')
if not class_name.istitle():
# 如果需要生产的类名首字母不是大写则抛出异常
raise TypeError("类名的首字母必须大写!!!")
super().__init__(class_name,class_bases,dic)
print(f'成功生产:{class_name}类')
class people(metaclass=MyType):
pass
p = people()
执行结果
'正常生产:people类'
TypeError: 类名的首字母必须大写!!!
我们还可以判断,生产的类是否带有注释,如果没有则抛出异常
class MyType(type):
def __init__(self,class_name,class_bases,dic):
print(f'正常生产:{class_name}类')
if not class_name.istitle():
raise TypeError("类名的首字母必须大写!!!")
elif dic.get('__doc__') is None or len(dic.get('__doc__').strip()) == 0:
raise Exception("生产的类必须携带注释,且注释不能为空!!!")
super().__init__(class_name,class_bases,dic)
print(f'成功生产:{class_name}类')
class People(metaclass=MyType):
'''
这是People类的注释
'''
p = People()
类实例化对象的过程
在我们平时通过类实例化对象时,第一个触发的是__new__方法产生对象,再是__init__方法初始化对象,但是学习元类有有所改变!
类实例化对象其实是先调用了元类里面的__call__方法,然后由元类调用我们类里面的__new__方法拿到对象,再来调用我们类里面的__init__方法,初始化这个空对象`
通过在元类里面帮助我们生产的类实例化对象
class MyType(type):
def __call__(self, *args, **kwargs): # 拿到传递的值
# 这里self代表:是哪个类加()调用的就是哪个类
# 这里的self代表了People类,因为是People类加()调用了这个元类
# 调用People类的__new__方法,帮助我们实例化一个对象
# 注意看下面:People类没有此方法,所以调用了People父类(object)的__new__
obj = self.__new__(self) # 拿到一个空对象
obj.__init__(*args,**kwargs) # 调用这个空对象所属类的__init__方法,并把值传递进去,相当于帮助我们初始化这个对象
return obj # 返回这个对象给调用者
class People(metaclass=MyType):
'''
这是类的注释
'''
def __init__(self,name,age): # 其实是元类来调用的这个__init__方法
self.name = name
self.age = age
p = People('jack',18) # 类名加()触发元类的__call__执行
# 对象加()触发所属类的__call__执行
# p拿到MyType.__call__的返回值
print(p.name)
执行结果
'jack'
这样是我们平时实例化对象的整体流程:
类() ->
元类.__new__方法(生产出一个类) ===>
元类.__init__方法 ===>
元类.__call__方法 ===>
类或父类.__new__方法(拿到空对象) ===> # 如果类有则调用类的,否则调用父类的
类.__init__方法(初始化空对象) ===>
拿到初始化后的对象
代码演示:对象实例化出来的整个过程
class MyType(type):
def __new__(cls, *args, **kwargs): # 首先执行__new__产生类
return super().__new__(cls,*args,**kwargs)
def __init__(self,*args,**kwargs): # 调用__init__传一些内部可能需要的参数
super().__init__(*args,**kwargs)
# 通过调用People的__new__方法产生对象,如果没有则调用People父类的(object)
# 将传递进来的参数传给People的__init__初始化
def __call__(self, *args, **kwargs):
obj = self.__new__(self)
obj.__init__(*args,**kwargs)
return obj # 返回对象
class People(metaclass=MyType):
def __init__(self,name):
self.name = name
# 最终,p接收到了对象
p = People('jack')
print(p.name)
切记:类名加()触发元类的__call__执行,对象加()才是触发类里面的__call__运行
练习:定义修改属性为隐藏属性
class MyType(type):
def __call__(self, *args, **kwargs):
obj = self.__new__(self)
obj.__init__(*args,**kwargs) # 先将属性初始化给对象
obj.__dict__ = {
f'_{self.__name__}__{key}':value for key,value in obj.__dict__.items()
}
# 修改对象的初始化属性,将属性名变形:_类名__属性名,这样就成了隐藏属性
return obj
class People(metaclass=MyType):
'''
这是类的注释
'''
def __init__(self,name,age):
self.name = name
self.age = age
p = People('jack',18)
print(p.__dict__)
print(p.name)
执行结果
{
'_People__name': 'jack', '_People__age': 18}
AttributeError: 'People' object has no attribute 'name'
# 修改成功,已经无法正常找到属性了
属性查找
了解元类以后,属性查找的顺序将更新一步了,注意:只针对类查找属性,对象的属性查找还是一样的。
此时类的查询顺序为:
当前类自身 > 父类 > 元类
可以看一下,在自身或父类未找到,则去元类里面找到了n属性
class MyType(type):
n = 10
class A(object):
pass
class B(A):
pass
class C(B,metaclass=MyType):
pass
print(C.n)
执行结果
10
而如果我们使用对象,也去查找属性,是否会找到元类里面呢?答案是不行的
class MyType(type):
n = 10
class A(object):
pass
class B(A):
pass
class C(B,metaclass=MyType):
pass
c = C()
print(c.n)
执行结果
AttributeError: 'C' object has no attribute 'n'
发生报错,因为对象只会在类之间查找属性或方法。不会找到元类
理解:只有类可以找到元类,而对象只能找到类
小结
元类也是一个类,它也继承至object,但与它生产类没有任何冲突,我们自定义的元类,可以很好的控制类创建时的操作,也可以在类的实例化对象时做一些操作。
补充内容:元类实现单例模式
单例模式(Singleton mode)是一种常见的设计模式,该模式的主要目的就是一个类中只有一个实例
作用:节省资源,如果产生成千上万的对象,而它们却只做一个事情,这样会占用大量资源,所以这时使用单例模式最适合不过
class MyType(type):
instance = False # 元类的属性
def __call__(self, *args, **kwargs):
# 先去自身及父类里面找instance,没有找到该属性则找到元类里面了
if not self.instance:
# 给自身类增加一个属性,该属性值就是一个实例。
self.instance = super().__call__(*args, **kwargs)
# 每次都可以为这个实例设置新的属性
self.instance.__init__(*args, **kwargs)
return self.instance # 返回这个实例
# 因为我们类的属性名设置了instance,所以下一次就会在自身找到,判断为True取反,不执行if,所以每次拿到的都是第一次的实例
class People(metaclass=MyType):
def __init__(self,name):
self.name = name
def send_email(self):
print(f'{self.name}发送了邮箱~')
p = People('jack')
p.send_email()
p1 = People('tom')
p1.send_email()
print(id(p), id(p1)) # 查看两个对象的内存地址,如果相同则是同一个对象
执行结果
'jack发送邮箱~'
'tom发送邮箱~'
140717084402880 140717084402880
可以看到,我们创建的两个对象内存地址都是相同的,说明使用的是同一个对象。我们即使实例化再多,每次都会返回我们最初设置的那个实例。所以并不会占用多少资源。
技术小白记录学习过程,有错误或不解的地方请指出,如果这篇文章对你有所帮助请
点赞 收藏+关注子夜期待您的关注,谢谢支持!