快速搭建易于医疗领域的小型知识图谱
本文仅限于调通项目运行,并对其代码进行解释,没有对其代码进行修改,仅供入门学习使用!
1、知识图谱介绍
知识图谱技术包括信息抽取(命名体识别和关系识别),知识表示,知识融合,知识推理。
信息抽取是从不同数据源得到本体化的知识表达;知识融合是对新知识进行合并消除歧义和重复;知识加工是将新知识加到现有知识库,新增数据,拓展知识库。
- 自互联网技术产业化以来,网络信息量与日俱增,人们对信息获取的准确度也有更高要求。在信息量巨大的网络中,找到符合预期的结果信息是亟待解决的问题。长期以来,传统的信息检索方式是通过搜索引擎查询和使用特定领域的信息管理系统来实现。但是,这种方式需要用户准确输入关键词,并且需要再耗时在相关网页中查询,使得用户体验不友好。特定领域的信息管理系统需要用户很熟悉当前领域,操作繁琐,效率低。
- 近年来,随着互联网上涌现的一批大规模的知识图谱,使得基于知识图谱的智能问答有了更好地发展契机。基于知识图谱的智能问答作为一种新的信息查询方式,它以自然语言问句这种用户友好的方式作为输入,然后为用户输出精准的答案,受到学术界和工业界的广泛关注。知识图谱(Knowledge Graph)的概念是谷歌在 2012 年 5 月所提出[1],其目的是为了提高搜索的质量,提高用户体验。知识图谱是一种新型的数据表示方式,其基本单位是以“实体-关系-实体”或者“实体-属性-属性值”三元组的形式组成。它能很好的组织和管理互联网信息,是一个高质量的语料库,已被广泛应用于搜索、智能问答、个性化推荐等领域。
本项目基于检索式问答技术(基于模板匹配和机器学习方法),主要利用浅层语义理解技术从大量的候选集中寻找答案并且构建医疗问答系统
2、项目介绍
该项目的地址:https://github.com/zhihao-chen/QASystemOnMedicalGraph
(1)、项目准备
1)、项目运行环境
- python3.0及以上
- neo4j的安装(windows版本)
- sklearn(机器学习)、ahocorasick(树,安装时应该安装pyahocorasick)、pandas(数据处理)、numpy(矩阵运算)、jieba(中文分词)、py2neo(原生图数据库)…
2)、neo4j的安装及使用
-
官网下载地址:https://neo4j.com/download-center/
-
百度云链接:https://pan.baidu.com/s/1hygHS6_W5rqoAc41V30sTQ 提取码:v5z4 (版本为3.5)
-
neo4j需要配合openjdk8.0使用:下载链接:https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/8/jdk/x64/windows/
name为:OpenJDK8U-jdk_x64_windows_hotspot_8u262b10.zip -
openjdk和neo4j的环境变量设置:将openjdk和neo4j的解压缩地址放入环境变量中,具体查看我的另一个博客:https://blog.csdn.net/qq_41744697/article/details/107747136
-
点击组合键:Windows+R,输入cmd,启动DOS命令行窗口输入neo4j.bat console,进入其浏览器(localhost:)
出现下图即为成功:

-
在浏览器中运行“http://localhost:7474/”,出现以下图片
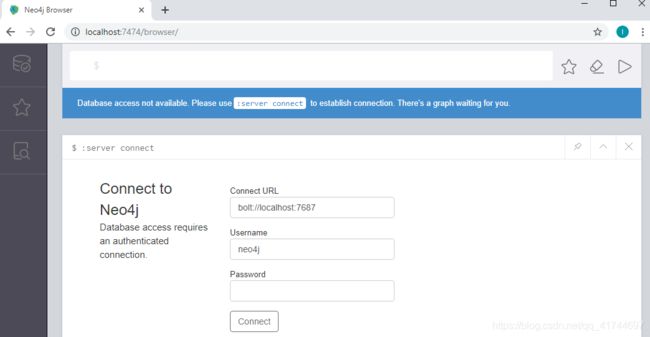
默认的host是bolt://localhost:7687,默认的用户是neo4j,默认的密码是:neo4j,第一次成功connect到Neo4j服务器之后,需要重置密码。 -
如果访问Neo4j验证失败(The client is unauthorized due to authentication failure.)
可以访问该博客寻找办法:https://blog.csdn.net/weixin_39198406/article/details/85068102
(2)、项目分析
1)、先来介绍一下目录
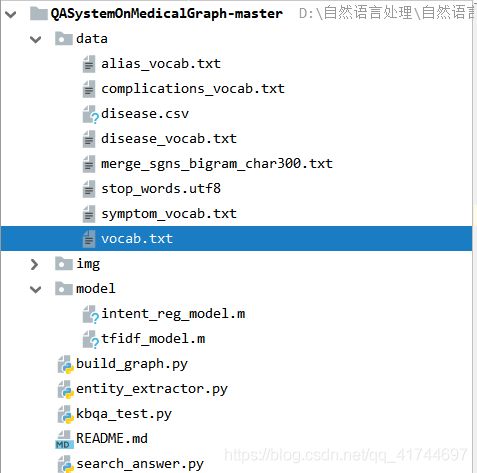
data文件夹:
- stop_words.utf8 过滤question中的停用词
- merge_sgns_bigram_char300.txt word2vec模型中用来计算相似度的预处理向量文件
- vocab.txt jieba库预加载词汇文件
- disease_vocab.txt 、 symptom_vocab.txt、 alias_vocab.txt、 complications_vocab.txt 模板匹配时使用的关键词
- disease.csv 提供训练所有的数据,使用pandas读取,neo4j配合ahocorasick建立知识图谱模型
model文件夹:
- tfidf_model.m TF_IDF统计关键词模型
- intent_reg_model.m 朴素贝叶斯模型(统计分类)
code文件夹:
- kbqa_test.py 主代码
- build_graph.py 建图
- entity_extractor.py 分析question的实体、和实体关系、实体属性以及问题意图
- search_answer.py 根据question提供的信息在图数据库中寻找答案
kbqa_test.py分析:
15行:解析question,返回question中的实体、和实体关系、实体属性以及问题意图
例如:
{'Disease': ['乙肝', '哮喘'], 'Complication': ['哮喘'], 'intentions': ['query_period']}
19行:将15行返回的信息转换为neo4j的sql语句用于查询
例如:
# 查询疾病描述
if intent == "disease_describe" and label == "Alias":
sql = ["MATCH (d:Disease)-[]->(a:Alias) WHERE a.name='{0}' return d.name,d.age," \
"d.insurance,d.infection,d.checklist,d.period,d.rate,d.money".format(e) for e in entities]
if intent == "disease_describe" and label == "Disease":
sql = ["MATCH (d:Disease) WHERE d.name='{0}' return d.name,d.age,d.insurance,d.infection," \
"d.checklist,d.period,d.rate,d.money".format(e) for e in entities]
if intent == "disease_describe" and label == "Symptom":
sql = ["MATCH (d:Disease)-[]->(s:Symptom) WHERE s.name='{0}' return d.name,d.age," \
"d.insurance,d.infection,d.checklist,d.period,d.rate,d.money".format(e) for e in entities]
if intent == "disease_describe" and label == "Complication":
sql = ["MATCH (d:Disease)-[]->(c:Complication) WHERE c.name='{0}' return d.name," \
"d.age,d.insurance,d.infection,d.checklist,d.period,d.rate,d.money".format(e) for e in entities]
返回:
[{'intention': 'query_period', 'sql': ["MATCH (d:Disease) WHERE d.name='乙肝' return d.name,d.period", "MATCH (d:Disease) WHERE d.name='哮喘' return d.name,d.period"]}]
21行:使用sql语句在neo4j图数据库中进行搜索,同时匹配上我们自己加上的回答模板
"疾病 {0} 的描述信息如下:\n发病人群:{1}\n医保:{2}\n传染性:{3}\n检查项目:{4}\n" \
"治愈周期:{5}\n治愈率:{6}\n费用:{7}\n"
biuld_graph.py代码解析:
11-13行: 加载图(注意用户名和密码(密码可能开始登录后修改过,使用修改后的密码))
15-106行:读取disease.csv中的数据,实体返回集合,实体间关系和实体属性返回列表形式
108-197行:创建知识图谱实体(创建实体节点、创建实体间关系、创建节点属性)
运行结果:
在基于模板方式询问答案时,正确率很高,但是一旦语义脱离模板,回答的答案和问题不符合甚至直接放弃回答




本项目知识图谱的构建是使用了人工标注的数据(人工选取出了实体和实体之间的信息),未来主流的方向是,先使用爬虫对信息网站进行数据爬取,进行数据清洗和数据标注(监督模型:CNN),再使用某个神经网络模型对实体之间的关系进行抽取,然后将实体和实体间关系构建知识图谱。
本项目的问答系统,进入一个question之后,先进行分词处理,将其中的每一个词都放入实体集合中进行模板匹配(如果匹配失败则使用word2vec模型中的向量文件,计算匹配失败的实体的相似度,用向量库中寻找一个相似的词),将返回的实体和问题特征(TF-IDF处理)再使用朴素贝叶斯模型进行关系预测,再拿到实体与其之间的关系后转换为neo4j的sql查询语言,去neo4j中进行查询得到答案,加上人为设定的回答模型就可以返回answer。
3、改进方向
基于模板匹配和统计的方法建立的基于知识图谱的问答系统在特定的问题和领域中的识别率还是很高,但是问题的匹配形式需要人为设定和标注,通用性差,而且限制了提问者的语义,无法做到真正符合人类使用习惯的语义分析,应该采用近来热门的神经网络系统来实现自然语言处理。
1、知识图谱技术包括信息抽取(命名体识别和关系识别),知识表示,知识融合,知识推理
(1)、信息抽取
1)、命名体识别
命名实体识别的任务是给句子中的每一个词都分配一个命名实体标签,一个命名实体可以标记句子中的多个词条。(监督学习)
1.jieba分词
2. word2vec(一个生成词向量的神经网络)(CBOW模型(一个词语的上下文作为输入,来预测这个词语本身)或 Skip-gram 模型(一个词语作为输入,来预测它周围的上下文))或者glove工具将词处理成向量
3. 使用Bi-LSTM双向LSTM神经网络进行训练(这些表征有效包括了上下文中的单词表征,这有利于提高命名实体识别的准确性),在最后一层神经网络中加一层softmax层实现分类
4. 如果在第三点中不加入softmax层用来分类,可以使用CRF实现分类预测
也可以摒弃以上4点,直接使用BERT模型去做命名体识别,BERT模型属于无监督模型,只要给如足够的语料库,可以取得惊人的效果。
前一段时间谷歌推出的BERT模型在11项NLP任务中夺得SOTA结果,引爆了整个NLP界。而BERT取得成功的一个关键因素是Transformer的强大作用。谷歌的Transformer模型最早是用于机器翻译任务,当时达到了SOTA效果。Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行。并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提升模型准确率。
《Attention is All You Need》论文地址:https://arxiv.org/abs/1706.03762
BERT模型介绍:http://blog.itpub.net/29829936/viewspace-2642324/
2)、关系抽取
输入是给定包含两个实体的一个句子 ,输出是两个实体之间的关系
关系抽取方法通常可分为有监督学习方法、远程监督学习方法和开放式抽取方法
- 有监督的实体关系抽取方法虽然准确率高,
但是很依赖于标注语料的数量和质量,特别是在深度学习中。这就需要人工标注数据,是一项耗时耗力的任务,所以效率会很低;也缺乏不同领域之间的迀移性和适应性。(监督模型,例:CNN+…) - 远程监督是利用已有的知识库对语料进行自动标注,标注过程过于直接,通常都会在标注时就引入了噪声,使得召回率较低。(基于小型知识图谱)
- 开放式抽取方法无需定义实体关系类型,借助网页结构和规则自动完成实体关系类型,一般这种得到的三元组质量不高。(无监督模型)
关系抽取又可以分为流水线模型和端到端的模型。流水线模型是分阶段实现的,即先识别实体,再抽取关系,这通常会存在错误传播的影响;而端到端的模型则同时得到实体和关系,这种方法目前准确率不高。
什么是端到端的模型?:https://blog.csdn.net/cs24k1993/article/details/79118460
可以使用基于 CATT 的少样本关系抽取
(2)、知识表示
通过知识抽取可以从自然语言文本中得到三元组信息,为了在问答系统中应用到已有的知识,在此小节将使用翻译模型将这些已有的知识表示成数值向量。在实际的工程应用中采用的开源模型是 TransE 模型,有许多工作都对其进行了再包装,方便工程应用。模型的输入是前面工作所提供的实体和关系,输出是每个实体或关系各自的数值向量。使用 TransE 模型训练完成后,保存模型,提取模型中的实体词嵌入矩阵和关系词嵌入矩阵,这就是表示好的向量,作为预训练的实体和关系,然后存储到磁盘上的指定目录,待后续使用。
(3)、基于图数据库的知识存储
1、由于知识图谱是关联密集型的数据集,使用传统的关系型数据库不能突出连接关系;存在数据冗余,关联查询开销大,扩展性不好等问题。而图数据库直接使用图形结构来表示和存储数据,很符合知识图谱这种语义网络信息。在图数据库中,关联查询操作速度快,能够使用基于图数据结构的相关算法查找关系路径。因此,本文选用开源图数据库 Neo4j 作为知识存储工具。
2、在 Neo4j 中,节点对应的是图中实体,边对应的是图中关系或属性。为了将数据批量导入到 Neo4j 中,需要先将数据按照 CSV 文件格式存储,然后采用 Neo4j的图数据库语言Cypher 导入数据,具体而言,可以在命令窗口直接调用命令"LOADCSV"来批量导入数据。
(4)、基于知识图谱的智能问答
当知识图谱构建好之后,问句就可以使用已有的知识图谱来回答问题,采用的模型是 KEAtt 问答模型。问答处理流程如下:首先,自然语言文本问句,识别出问句中的实体。然后,对实体进行扩展,得到候选实体,使用实体在知识图谱中查找相应关系作为候选关系。最后,根据文本问句在候选关系中找出最匹配的关系,再选择出最匹配的实体。
参考文献(格式不太规范,请理解):
[1] github项目:https://github.com/zhihao-chen/QASystemOnMedicalGraph
[2]刘良. 基于领域知识图谱的智能问答关键技术研究[D].电子科技大学,2020.
[3] 百度百科 环境变量的解释 https://baike.baidu.com/item/%E7%8E%AF%E5%A2%83%E5%8F%98%E9%87%8F/1730949
[4] 访问Neo4j验证失败(The client is unauthorized due to authentication failure.): https://blog.csdn.net/weixin_39198406/article/details/85068102
[5] neo4j的使用 : https://www.cnblogs.com/ljhdo/archive/2017/05/19/5521577.html
[6] 机器学习中什么是端到端的学习(end-to-end learning)?:
https://blog.csdn.net/cs24k1993/article/details/79118460